Dans cette légère annexe, je vous présente les principaux outils à connaître pour tester et débugger votre application Java EE.
Les fichiers de logs
Quels fichiers ?
Les premiers outils à connaître, si tant est que l'on puisse les qualifier d'outils, sont les fichiers de logs des différents composants de votre application. Ils contiennent les messages, avertissements et erreurs enregistrés lors du démarrage des composants et lors de leur fonctionnement. Pour des applications basiques, comme celles que nous développons dans ce cours, trois fichiers différents peuvent vous être utiles :
- les logs du serveur d'applications ;
- les logs du SGBD ;
- les logs de la JVM.
Fichier de logs du serveur d'applications
Le fichier dont vous aurez le plus souvent besoin est le fichier de logs de votre serveur d'applications. Il contient des informations enregistrées au démarrage du serveur, lors du déploiement de votre application et lors de l'utilisation de votre application. C'est ici par exemple qu'atterrissent toutes les exceptions imprévues, c'est-à-dire celles qui ne sont pas interceptées dans votre code, et qui peuvent donc être synonymes de problèmes.
Selon le serveur que vous utilisez et le système d'exploitation sur lequel il s'exécute, le fichier se situera dans un répertoire différent. Vous pourrez trouver cette information sur le web ou tout simplement dans la documentation de votre serveur. À titre d'exemple, le fichier de logs d'une application web sous GlassFish se nomme server.log et se situe dans le répertoire /glassfish/domains/nom-du-domaine/logs/, où nom-du-domaine dépend de la manière dont vous avez configuré votre serveur lors de son installation. Par défaut, ce répertoire se nomme domain1.
Voici un exemple de contenu possible :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | Dec 3, 2012 2:16:40 PM com.sun.enterprise.admin.launcher.GFLauncherLogger info INFO: Successfully launched in 16 msec. [#|2012-12-03T14:16:43.331+0800|INFO|glassfish3.1.2|com.sun.enterprise.server.logging.GFFileHandler|_ThreadID=1;_ThreadName=Thread-3;| Running GlassFish Version: GlassFish Server Open Source Edition 3.1.2.2 (build 5)|#] [#|2012-12-03T14:16:43.629+0800|INFO|glassfish3.1.2|javax.enterprise.system.core.com.sun.enterprise.v3.services.impl|_ThreadID=12;_ThreadName=Thread-3;| Grizzly Framework 1.9.50 started in: 61ms - bound to [0.0.0.0:4848]|#] ... [#|2012-12-09T21:55:54.774+0800|SEVERE|glassfish3.1.2|javax.enterprise.system.tools.admin.org.glassfish.deployment.admin|_ThreadID=17;_ThreadName=Thread-3;| Exception while preparing the app : Exception [EclipseLink-4002] (Eclipse Persistence Services - 2.3.2.v20111125-r10461): org.eclipse.persistence.exceptions.DatabaseException Internal Exception: java.sql.SQLException: Error in allocating a connection. Cause: Connection could not be allocated because: Unable to open a test connection to the given database. JDBC url = jdbc:mysql://localhost:3306/bdd_sdzee, username = java. Terminating connection pool. Original Exception: ------ com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ..... |
Extrait de logs de GlassFish
Vous pouvez définir le niveau de détail des informations enregistrées via la console d'administration asadmin que je vous fais découvrir dans le chapitre du cours portant sur JPA. En ce qui concerne le framework de persistance EclipseLink, il suffit d'ajouter une section dans le fichier de configuration persistence.xml de votre application :
1 2 3 4 5 6 7 | <persistence-unit ...> ... <properties> <property name="eclipselink.logging.level.sql" value="FINE"/> <property name="eclipselink.logging.parameters" value="true"/> </properties> </persistence-unit> |
Niveau de détails de logs d'EclipseLink
En procédant à cet ajout, vous pourrez visualiser les requêtes SQL générées par votre application au sein du fichier de logs de GlassFish.
Fichier de logs du SGBD
Votre gestionnaire de base de données peut également générer des fichiers de logs. Il existe généralement différents niveaux de détails : l'enregistrement des erreurs uniquement, l'enregistrement de toutes les connexions établies et requêtes effectuées, l'enregistrement des requêtes longues (on parle alors de Slow Query), etc.
Là encore, selon la BDD utilisée et le système d'exploitation sur lequel elle s'exécute, les fichiers se trouveront dans un répertoire différent. À titre d'exemple toujours, MySQL n'enregistre par défaut aucune information (à l'exception des erreurs sous Windows uniquement). Il est alors possible d'activer les différents modes de logging en ajoutant des paramètres lors du lancement du serveur SQL :
- pour activer le mode Error Log, il suffit d'ajouter
--log-error[=nom_du_fichier]à la commande de lancement de MySQL, où nom_du_fichier est optionnel et permet de spécifier dans quel fichier enregistrer les informations ; - pour activer le mode General Query Log, c'est-à-dire l'enregistrement des connexions et requêtes effectuées, alors il suffit d'ajouter
--log[=nom_du_fichier]à la commande de lancement de MySQL, où nom_du_fichier est optionnel et permet de spécifier dans quel fichier enregistrer les informations.
Voici un exemple de contenu d'un fichier Error Log :
1 2 3 4 5 6 7 8 9 10 | InnoDB: Setting log file ./ib_logfile1 size to 5 MB InnoDB: Database physically writes the file full: wait... InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: 127 rollback segment(s) active. InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created 121114 0:29:59 InnoDB: Waiting for the background threads to start 121114 0:30:00 InnoDB: 1.1.8 started; log sequence number 0 121114 0:30:00 [Note] Server hostname (bind-address): '0.0.0.0'; port: 3306 |
Extrait de logs de MySQL
Par défaut sous les systèmes de type Unix, le fichier de logs d'erreurs se trouve dans /usr/local/mysql/data/.
Fichier de logs de la JVM
Dans certains cas, vous pouvez être confrontés à des problèmes liés aux fondations de votre application, à savoir la JVM utilisée pour faire tourner Java sur votre machine. Elle aussi peut enregistrer des logs d'erreurs, et vous pouvez spécifier dans quel répertoire et quel fichier en ajoutant -XX:ErrorFile=nom_du_fichier lors de son lancement. Par exemple, si vous souhaitez que votre JVM crée un fichier nommé jvm_error_xxx.log dans le répertoire /var/log/java/, où xxx est l'identifiant du processus courant, il faut lancer Java ainsi :
1 | java -XX:ErrorFile=/var/log/java/java_error_%p.log
|
Si l'option -XX:ErrorFile= n'est pas précisée, alors le nom de fichier par défaut sera hs_err_pidxxx.log, où xxx est l'identifiant du processus courant. En outre, le système essaiera de créer ce fichier dans le répertoire de travail du processus. Si jamais le fichier ne peut être créé pour une raison quelconque (espace disque insuffisant, problème de droits ou autre), alors le fichier sera créé dans le répertoire temporaire du système d'exploitation (/tmp sous Linux, par exemple).
Comment les utiliser ?
Si vous avez intégré votre serveur d'applications à Eclipse, alors son fichier de logs sera accessible depuis le volet inférieur de l'espace de travail Eclipse, ce qui vous permettra de ne pas avoir à quitter votre IDE pour régler les problèmes liés au code de votre application. Par exemple, si vous utilisez le serveur GlassFish depuis Eclipse il vous suffit de faire un clic droit sur le nom de votre serveur, et de suivre GlassFish > View Log File.
En ce qui concerne les logs des autres composants, il vous faudra le plus souvent aller les chercher et les parcourir par vous-mêmes, manuellement. Pour ne rien vous cacher, ce travail est bien plus aisé sous les systèmes basés sur Unix (Mac OS, Linux, etc.), qui proposent, via leur puissant terminal, quelques commandes très pratiques pour la recherche et l'analyse de données, notamment tail -f et grep.
Cela dit, quel que soit le système d'exploitation utilisé, il est souvent intéressant de pouvoir colorer le contenu d'un fichier de logs, afin de pouvoir plus facilement repérer les blocs d'informations intéressantes parmi le flot de messages qu'il contient. Pour ce faire, vous pouvez par exemple utiliser un logiciel comme SublimeText. La coloration syntaxique vous aidera grandement au déchiffrage des sections qui vous intéressent. Observez par exemple sur la figure suivante un extrait du fichier server.log de GlassFish ouvert avec SublimeText, coloration syntaxique activée.
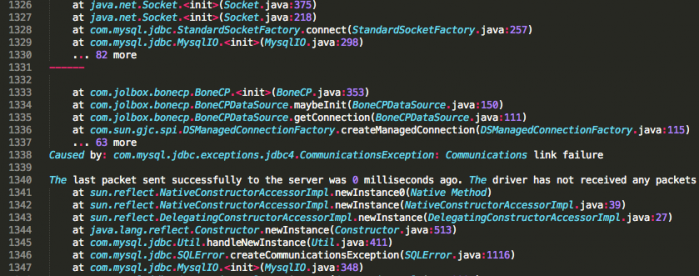
C'est déjà bien moins austère ainsi, n'est-ce pas ? 
Le mode debug d'Eclipse
Principe
Le second outil le plus utile pour le développement d'une application avec Eclipse est le mode Debug que ce dernier fournit. Il s'agit d'un mode d'exécution pas à pas, que vous avez la possibilité de contrôler manuellement et de manière aussi fine que souhaitée. Le principe est simple : Eclipse prend la main sur votre serveur, et vous offre la possibilité de littéralement mettre en pause l'exécution du code de votre application.
Le système se base sur des breakpoints, de simples marqueurs que vous avez la possibilité de poser sur les lignes de code que vous souhaitez analyser.
Interface
Pour lancer le serveur en mode debug, il ne faut plus utiliser le bouton classique mais cette fois celui qui ressemble à un petit insecte, ou bug en anglais. Le serveur va alors démarrer, et vous pourrez commencer à utiliser l'application que vous y avez déployée sans différence apparente avec le mode classique (voir la figure suivante).

Pour pouvoir mettre en pause l'exécution de votre application et étudier son fonctionnement, il faut au minimum ajouter un breakpoint dans la portion de code que vous souhaitez analyser. Cela se fait tout simplement en double-cliquant sur l'espace vide situé à gauche d'une ligne de code, comme indiqué sur la figure suivante.

Un petit rond bleu apparaît alors dans l'espace libre et, au survol de ce marqueur, une infobulle vous informe de la ligne de code et de la méthode ciblée par le breakpoint. Rendez-vous à nouveau dans le navigateur depuis lequel vous testez l'application, et effectuez à nouveau la ou les actions faisant intervenir la portion de code sur laquelle vous avez posé un marqueur. Cette fois, votre navigateur va rester en attente d'une réponse de votre serveur, et une fenêtre d'avertissement va alors apparaître dans Eclipse (voir la figure suivante).

Eclipse vous informe que vous vous apprêtez à ouvrir un espace visuel dédié au mode debug. Vous devrez alors cliquer sur Yes pour accepter, et Eclipse vous affichera alors une nouvelle interface depuis laquelle vous allez pouvoir contrôler votre application.
Pendant ce temps, le navigateur reste logiquement en attente d'une réponse du serveur, tant que vous n'avez pas fait avancer le déroulement jusqu'au bout du cycle en cours, c'est-à-dire jusqu'au renvoi d'une réponse au client.
Depuis l'espace de debug, vous avez pour commencer la possibilité de revenir vers la vue de travail classique, sobrement intitulée Java EE, en cliquant sur le bouton situé dans le volet en haut à droite de l'écran (voir la figure suivante).
Réciproquement, vous pourrez passer de la vue d'édition vers la vue de debug en cliquant sur le bouton intitulé Debug depuis la vue de travail classique.
Deuxième volet important, celui situé en haut à gauche de l'écran de debug (voir la figure suivante).
C'est via ces quelques boutons que vous allez pouvoir commander le déroulement de l'exécution de votre code.
Une autre fonctionnalité importante du mode debug est la possibilité de surveiller des variables ou des objets, d'inspecter leur contenu en temps réel afin de vérifier qu'elles se comportent bien comme prévu. Il faut pour cela sélectionner l'objet à observer dans le code affiché dans le volet gauche central de la fenêtre de debug, puis effectuer un clic droit et choisir Watch (voir la figure suivante).
Le volet supérieur droit de l'écran de debug va alors se mettre à jour et afficher les informations concernant l'objet que vous avez sélectionné (voir la figure suivante).
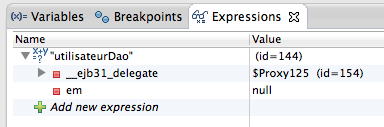
Vous pouvez bien entendu surveiller plusieurs objets simultanément. C'est dans cette petite fenêtre que vous pourrez vérifier que les données que vous créez et manipulez dans votre code sont bien celles que vous attendez, au moment où vous l'attendez !
Exemple pratique
Assez disserté, passons à l'action. Nous allons mettre en place un projet constitué d'une seule et unique servlet, dans le but de faire nos premiers pas avec le mode debug d'Eclipse, mais pas seulement : nous allons également en profiter pour observer le cycle de vie d'une servlet, et son caractère multithreads. D'une pierre deux coups !
Pour commencer, nous allons créer un nouveau projet web dynamique depuis Eclipse, et le nommer test_debug. Nous allons ensuite y créer une nouvelle servlet nommée Test et placée dans un package intitulé com.test, dont voici le code :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | package com.test; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; @WebServlet( "/test" ) public class Test extends HttpServlet { private int compteur = 0; @Override public void init() throws ServletException { System.out.println( ">> Servlet initialisée." ); } public void doGet( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException { ++compteur; int compteurLocal = 0; ++compteurLocal; System.out.println( ">> Compteurs incrémentés." ); } @Override public void destroy() { System.out.println( ">> Servlet détruite." ); } } |
Servlet de test
Avant de passer aux tests, attardons-nous un instant sur le code ici mis en place. Vous devez vous souvenir des méthodes init() et destroy(). Nous les avons déjà rencontrées dans nos exemples, que ce soit dans des servlets ou dans des filtres. Pour rappel, elles sont présentes par défaut dans la classe mère de toute servlet, HttpServlet (qui les hérite elle-même de sa classe mère GenericServlet), et ne doivent pas nécessairement être surchargées dans une servlet, contrairement aux méthodes doXXX() dont une au moins doit être présente dans chaque servlet.
Dans cet exemple, nous surchargeons donc ces méthodes init() et destroy() aux lignes 17 à 19 et 30 à 32, dans lesquelles nous ne faisons rien d'autre qu'afficher un simple message dans la sortie standard, à savoir la console du serveur. Ne vous inquiétez pas, vous allez très vite comprendre pourquoi nous nous embêtons à surcharger ces deux méthodes !
Reste alors le code de la méthode doGet(). Là encore, rien de bien compliqué : nous incrémentons deux compteurs, l'un étant déclaré localement dans la méthode doGet(), et l'autre étant déclaré en tant que variable d'instance.
Voilà tout ce dont nous allons avoir besoin. Pas besoin de JSP, ni de fichier web.xml d'ailleurs puisque nous avons utilisé l'annotation @WebServlet pour déclarer notre servlet auprès de Tomcat ! Nous pouvons donc démarrer notre projet en mode debug, en cliquant sur le bouton ressemblant à un petit insecte dont je vous ai parlé précédemment. Avant d'accéder à notre servlet depuis notre navigateur, nous allons placer quelques breakpoints dans le code, afin de pouvoir mettre en pause son exécution aux endroits souhaités. Nous allons choisir les lignes 18, 22, 26 et 31, et nous allons donc effectuer un clic droit dans l'espace vide sur la gauche de chacune d'elles et choisir "Toggle breakpoint", comme indiqué sur la figure suivante.

Le même effet est réalisable en double-cliquant simplement dans cet espace vide. Une fois les breakpoints positionnés, nous visualisons alors quatre petits ronds bleus (voir la figure suivante).

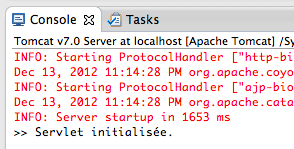
Notre environnement est maintenant prêt, nous pouvons commencer à tester. Pour ce faire, il nous suffit de nous rendre depuis notre navigateur sur la page http://localhost:8080/test_debug/test. Dès lors, Eclipse va prendre le dessus et va nous avertir que nous allons changer de vue de travail, nous cliquons alors sur Yes. Dans la vue de debug qui s'affiche, nous pouvons remarquer que l'exécution du code s'est mise en pause sur la ligne 18 du code. C'est bien le comportement que nous attendions, car comme nous accédons à notre servlet pour la première fois, sa méthode init() est appelée et notre premier breakpoint est activé.
Pour poursuivre le déroulement, nous appuyons sur la touche F8 du clavier, ou sur le bouton correspondant dans le volet de contrôle en haut à gauche de la vue de debug. L'exécution continue alors et se met aussitôt en pause sur la ligne 22. Logique, puisqu'il s'agit là de notre second breakpoint, et qu'il est activé à chaque passage d'une requête dans la méthode doGet() ! En d'autres termes, à ce moment précis, la requête GET émise par notre navigateur lorsque nous avons appelé l'URL de notre servlet, a déjà été acheminée dans notre méthode doGet().
Au passage, vous en profiterez pour observer que la méthode init() a bien été appelée en vérifiant le contenu du volet inférieur de la vue de debug. Il s'agit de la console, et si tout s'est bien passé vous devriez y trouver le message écrit par la ligne 18 de notre code (voir la figure suivante).
Nous allons alors sélectionner la variable compteur dans le code affiché dans le volet central, faire un clic droit puis choisir Watch.
Dans le volet supérieur droit apparaît alors le contenu de notre variable (voir la figure suivante).
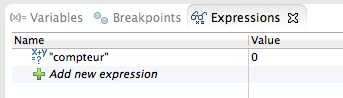
Puisque la ligne n'a pas encore été exécutée, la valeur est encore zéro. Nous appuyons alors à nouveau sur F8, et le cycle se poursuit jusqu'au prochain breakpoint à la ligne 26. La valeur du compteur a alors changé et est maintenant logiquement 1. Nous allons également surveiller la variable compteurLocal, en la sélectionnant, en effectuant un clic droit et en choisissant Watch. Le volet supérieur droit nous affiche alors les contenus des deux variables (voir la figure suivante).
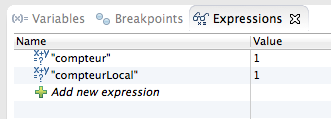
Un nouvel appui sur F8 permet de terminer le cycle : le navigateur affiche une page blanche, ce qui est logique puisque nous n'avons pas envoyé d'informations au client à travers la réponse HTTP. Aucune tâche n'étant en attente de traitement, la vue de travail de debug cesse d'afficher le contenu des variables. Nous allons maintenant changer de navigateur, et accéder une nouvelle fois à notre servlet via son URL http://localhost:8080/test_debug/test. Du point de vue du serveur, tout se passera donc comme si la visite était issue d'un utilisateur différent.
La vue de debug va alors s'activer à nouveau, l'exécution du code va se bloquer sur la ligne 22 et nous allons devoir appuyer sur F8 pour passer à la ligne 26. À cet instant, vous allez observer deux valeurs de compteurs différentes dans le volet des variables surveillées (voir la figure suivante).

Que s'est-il passé ?
Eh oui, à première vue nous sommes en droit de nous poser la question ! Dans notre code, nous initialisons bien nos deux compteurs à zéro. Pourquoi le compteur déclaré en tant que variable d'instance n'a-t-il pas été remis à zéro comme l'a été notre compteur local ? Eh bien tout simplement parce que comme je vous l'ai déjà expliqué à plusieurs reprises dans le cours, une servlet n'est instanciée qu'une seule et unique fois par votre serveur, et cette unique instance va ensuite être partagée par toutes les requêtes entrantes.
Concrètement, cela signifie que toutes les variables d'instance ne seront initialisées qu'une seule fois, lors de l'instanciation de la servlet. Les variables locales quant à elles sembleront réinitialisées à chaque nouvel appel. Voilà pourquoi la variable compteur a conservé sa valeur entre deux appels, alors que la variable compteurLocal a bien été réinitialisée.
"Sembleront ?"
Oui, sembleront. Car en réalité, c'est un petit peu plus compliqué que cela. Voilà comment tout cela s'organise :
- chaque requête entrante conduit à la création d'un
thread, qui accède alors à l'instance de la servlet ; - une variable d'instance n'est créée, comme son nom l'indique, que lors de l'instanciation de la servlet, et un unique espace mémoire est alloué pour cette variable dans la heap ;
- tous les threads utilisant cette instance, autrement dit toutes les requêtes entrantes dirigées vers cette servlet, partagent et utilisent cette même variable, et donc ce même espace mémoire ;
- une variable locale est initialisée à chaque utilisation par un
thread, autrement dit par chaque nouvelle requête entrante, dans sa stack ; - un espace mémoire différent est alloué pour chaque initialisation dans la stack, même comportement d'ailleurs pour les paramètres de méthodes.
Stack ? Heap ?
Vous devriez déjà connaître ces concepts si vous avez déjà programmé en Java, mais nous allons tout de même nous y pencher un instant. Dans une JVM, la mémoire est découpée en plusieurs sections : code, stack, heap et static. Pour faire simple, voici comment sont utilisées les fractions qui nous intéressent ici :
- la stack contient les méthodes, variables locales et variables références ;
- la heap contient les objets.
Voilà pourquoi notre variable d'instance est déclarée dans la heap : elle fait partie d'une classe, donc d'un objet.
Ce qu'il est très important de retenir ici, ce n'est pas uniquement le fait qu'une variable d'instance conserve son état d'un appel à l'autre. Ce qui est extrêmement important, c'est de bien comprendre qu'une variable d'instance est partagée par tous les clients ! Eh oui, vous avez bien constaté dans notre exemple que même en utilisant un autre navigateur, la variable compteur utilisée était la même que celle utilisée pour le premier appel.
Alors bien entendu, dans notre petit exemple ça ne vous paraît pas important. Mais imaginez maintenant que dans cette variable d'instance vous stockiez non plus un banal compteur mais un nom d'utilisateur, une adresse mail ou un mot de passe… De telles informations ainsi stockées seront alors partagées par tous les clients ! Et selon l'usage que vous faites de cette variable dans votre code, vous vous exposez à de graves ennuis.
Nous voilà maintenant au point sur deux aspects importants : nous avons pris en main le mode de debug d'Eclipse, et nous avons illustré le caractère multithread d'une servlet.
Conseils au sujet de la thread-safety
Avant de passer à la suite, revenons brièvement sur la problématique des threads et des servlets. Avec ce que nous avons posé, nous avons compris que la principale inquiétude se situe au niveau de la thread-safety. Nous savons maintenant que les servlets et les filtres sont partagés par toutes les requêtes. C'est un avantage du Java, c'est multithread, et des threads différents (comprendre ici "des requêtes HTTP") peuvent utiliser la même instance d'une classe. Cela serait par ailleurs bien trop coûteux (en termes de mémoire et de performances) d'en recréer une à chaque requête.
Rappelons que lorsque le conteneur de servlets démarre, il lit le fichier web.xml de chaque application web, et/ou scanne les annotations existantes, à la recherche des url-pattern associés aux servlets déclarées. Il place alors les informations trouvées dans ce qui s'apparente grossièrement à une map de servlets.
À ce sujet, sachez qu'en réalité une servlet peut être instanciée plusieurs fois par un même conteneur. En effet, si une même servlet est mappée sur plusieurs URL différentes, alors autant d'instances de la servlet seront créées et mises en mémoire. Mais le même principe de base tient toujours : une seule instance est partagée par toutes les requêtes adressant la même URL.
Ces servlets sont donc stockées dans la mémoire du serveur, et réutilisées à chaque fois qu'une URL appelée correspond à la servlet associée à l'url-pattern défini dans le web.xml ou l'annotation. Le conteneur de servlets déroule grossièrement ce processus pour chaque étape :
1 2 3 4 5 6 7 8 | for (Entry<String, HttpServlet> entry : servlets.entrySet()) { String urlPattern = entry.getKey(); HttpServlet servlet = entry.getValue(); if (request.getRequestURL().matches(urlPattern)) { servlet.service(request, response); break; } } |
La méthode HttpServlet#service() décide alors quelle méthode parmi doGet(), doPost(), etc. appeler en fonction de HttpServletRequest#getMethod().
Nous voyons bien à travers ce code que le conteneur de servlets réutilise pour chaque requête la même instance de servlet (ici, elles sont représentées grossièrement stockées dans une map). En d'autres termes : les servlets sont partagées par toutes les requêtes. C'est pourquoi il est très important d'écrire le code d'une servlet de manière threadsafe, ce qui signifie concrètement : ne jamais assigner de données issues des portées request ou session dans des variables d'instance d'une servlet, mais uniquement dans des variables déclarées localement dans ses méthodes.
Comprenez bien de quoi il est ici question. Si vous assignez des données issues de la session ou de la requête dans une variable d'instance d'une servlet ou d'un filtre, alors un tel attribut se retrouverait partagé par toutes les requêtes de toutes les sessions… Il s'agit là en quelque sorte d'un débordement : alors que votre variable devrait rester confinée à sa portée, elle se retrouve accessible depuis un périmètre bien plus large. Ce qui écrase bien évidemment les principes résumés précédemment ! Ce n'est absolument pas threadsafe ! L'exemple ci-dessous illustre clairement cette situation :
1 2 3 4 5 6 7 8 9 10 11 | public class MaServlet extends HttpServlet { private Object objetNonThreadSafe; // Objet déclaré en tant que variable d'instance protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { Object objetThreadSafe; // Objet déclaré localement dans la méthode doGet() objetNonThreadSafe = request.getParameter("foo"); // MAUVAIS !!! Cet objet est partagé par toutes les requêtes... objetThreadSafe = request.getParameter("foo"); // OK, c'est threadsafe : l'objet reste bien dans la bonne portée. } } |
Quelques outils de tests
Les tests unitaires
Un autre outil indispensable au bon développement d'une application est le test unitaire. La solution proposée par la plate-forme Java s'appelle JUnit : c'est un framework destiné aux tests.
Qu'est-ce qu'un test unitaire ?
Un test unitaire est une portion de code, écrite par un développeur, qui se charge d'exécuter une fonctionnalité en particulier. Le développeur doit donc en écrire autant qu'il existe de fonctionnalités dans son application, afin de tester l'intégralité du code. On parle alors de couverture du code ; dans un projet, plus le taux de couverture est élevé, plus le pourcentage de fonctionnalités testées est important.
Généralement dans les projets en entreprise, un niveau de couverture minimum est demandé : par exemple 80%. Cela signifie qu'au moins 80% des fonctionnalités du code doivent être couvertes par des tests unitaires.
Quel est l'intérêt de mettre en place de tels tests ?
En effet, la question est légitime. A priori, à partir du moment où le développeur teste correctement (et corrige éventuellement) ses classes et méthodes après écriture de son code, aucune erreur ne doit subsister. Oui, mais cela n'est vrai que pour une fraction de l'application : celle qui a été testée par le développeur pour vérifier que son code fonctionnait correctement. Mais rien ne garantit qu'après ajout d'une nouvelle fonctionnalité, la précédente fonctionnera toujours !
Voilà donc le principal objectif de la couverture du code : pouvoir s'assurer que le comportement d'une application ne change pas, après corrections, ajouts ou modifications. En effet, puisque chacun des tests unitaires s'applique à une seule fonctionnalité de manière indépendante, il suffit de lancer tous les tests un par un pour confirmer que tout se comporte comme prévu.
Pour information, c'est ce que l'on appelle des "tests de non régression" : s'assurer qu'après l'ajout de code nouveau ou la modification de code existant, l'application fonctionne toujours comme espéré et aucun nouveau problème - ou aucune régression - ne survient. La couverture du code par une batterie de tests unitaires permet d'automatiser la vérification, alors qu'il faudrait procéder à la main sinon, et donc être minutieux et bien penser à tester tous les cas de figure possibles.
Quelle partie du code d'une application doit être couverte ?
Seules les classes métier et d'accès aux données ont besoin d'être testées, car c'est ici que les fonctionnalités et résultats sont contenus. Les servlets n'étant que des aiguilleurs, elles ne sont pas concernées. Doivent donc être testés unitairement les JavaBeans, les objets métier, les EJB, les DAO, les éventuels WebServices, etc. Au sein de ces classes, seules les méthodes publiques doivent être testées : le fonctionnement des méthodes privées ne nous intéresse pas. Tout ce qui importe est que les méthodes publiques qui font appel à ces méthodes privées en interne retournent le bon résultat ou respectent le bon comportement.
À quoi ressemble un test unitaire ?
Les tests unitaires sont en principe codés dans un projet ou package à part, afin de ne pas être directement liés au code de l'application. Un test unitaire consiste en une méthode au sein d'une classe faisant intervenir des annotations spécifiques à JUnit. Imaginez par exemple que nous ayons écrit une classe nommée MaClasse, contenant des méthodes de calcul basiques nommées multiplication() et addition(). Voici alors à quoi pourrait ressembler la classe de tests unitaires chargée de vérifier son bon fonctionnement :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import org.junit.*; public class Test{ @Test public void testMultiplication() { // MaClasse est ciblée par le test MaClasse test = new MaClasse(); // Vérifie que multiplication( 6, 7 ) retourne bien 42 assertEquals( "Erreur", 42, test.multiplication( 6, 7 ) ); } @Test public void testAddition() { // MaClasse est ciblée par le test MaClasse test = new MaClasse(); // Vérifie que addition( 43, 115 ) retourne bien 158 assertEquals( "Erreur", 158, test.addition( 43, 115 ) ); } |
Exemple de test unitaire JUnit
Chaque test unitaire suit de près ou de loin ce format, et les tests doivent pouvoir être exécutés dans un ordre arbitraire : aucun test ne doit dépendre d'un autre test. Comme vous pouvez l'observer, pour écrire un test JUnit il suffit d'écrire une méthode et de l'annoter avec @Test. La méthode utilisée pour vérifier le résultat de l'exécution, assertEquals(), est fournie par JUnit et se charge de comparer le résultat attendu avec le résultat obtenu.
Pour le lancement des tests, Eclipse permet d'intégrer intuitivement l'exécution de tests JUnit depuis l'interface utilisateur via un simple clic droit sur la classe de tests, puis Run As > JUnit Test. En ce qui concerne la couverture du code, il existe un excellent plugin qui permet de mesurer le taux de couverture d'une application, et de surligner en vert et rouge les portions de codes qui sont respectivement couvertes et non couvertes : EclEmma. Pour vous donner une meilleure idée du principe, voici en figure suivante une capture de la solution en action.
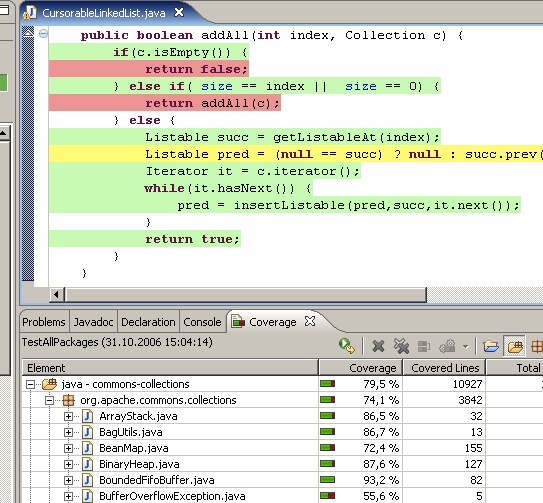
Nous allons nous arrêter là pour la découverte des tests unitaires, vous avez en main toutes les informations nécessaires pour savoir quoi chercher et comment mettre le tout en place dans vos projets ! 
Les tests de charge
Pour conclure cette annexe, je vais vous présenter très brièvement deux solutions que vous serez un jour ou l'autre amenés à utiliser si vous développez des applications web.

La première se nomme JMeter, elle est éditée par la fondation Apache. Elle permet d'effectuer des tests de charge et des mesures de performances. Elle est particulièrement utile pour le test d'applications web : vérifier que le code d'une application se comporte de manière correcte est une chose, mais il faut également vérifier qu'une application fonctionne toujours de manière convenable lorsque des dizaines, centaines ou milliers de visiteurs l'utilisent simultanément.
C'est là qu'intervient JMeter : la solution permet d'automatiser et de simuler des charges importantes sur un serveur, un réseau ou un composant en particulier, ou pour analyser la performance et la réactivité globale d'une application sous différents niveaux de charge. Bref, elle vous permettra de contrôler la présence de problèmes très importants, que vous ne pouvez pas déceler manuellement. Elle permet également de générer des graphiques et rapports afin de vous faciliter l'analyse des comportements observés par la suite.

La seconde se nomme JProfiler. Plus complexe à maîtriser, elle n'est généralement mise en œuvre que lorsque des problèmes sont observés sur une application. Ses atouts les plus classiques sont l'analyse poussée de la mémoire utilisée lors de l'utilisation d'une application, l'analyse de l'utilisation du CPU, l'analyse du temps passé dans chaque méthode ou portion de code, etc. Les rapports qu'elle génère permettent alors de découvrir qu'est-ce qui cause des problèmes, de comprendre pourquoi cela ne fonctionne pas comme prévu, et surtout sous quelles conditions.