Nous y voilà enfin ! Nous allons commencer par découvrir ce qu'est une servlet, son rôle au sein de l'application et comment elle doit être mise en place. J'adopte volontairement pour ce chapitre un rythme assez lent, afin que vous preniez bien conscience des fondements de cette technologie.
Pour ceux qui trouveraient cela barbant, comprenez bien que c'est important de commencer par là et rassurez-vous, nous ne nous soucierons bientôt plus de tous ces détails ! 
Derrière les rideaux
Retour sur HTTP
Avant d'étudier le code d'une servlet, nous devons nous pencher un instant sur le fonctionnement du protocole HTTP. Pour le moment, nous avons simplement appris que c'était le langage qu'utilisaient le client et le serveur pour s'échanger des informations. Il nous faudrait idéalement un chapitre entier pour l'étudier en détail, mais nous ne sommes pas là pour ça ! Je vais donc tâcher de faire court…
Si nous observions d'un peu plus près ce langage, nous remarquerions alors qu'il ne comprend que quelques mots, appelés méthodes HTTP. Ce sont les mots qu'utilise le navigateur pour poser des questions au serveur. Mieux encore, je vous annonce d'emblée que nous ne nous intéresserons qu'à trois de ces mots : GET, POST et HEAD.
GET
C'est la méthode utilisée par le client pour récupérer une ressource web du serveur via une URL. Par exemple, lorsque vous tapez www.zestedesavoir.com dans la barre d'adresses de votre navigateur et que vous validez, votre navigateur envoie une requête GET pour récupérer la page correspondant à cette adresse et le serveur la lui renvoie. La même chose se passe lorsque vous cliquez sur un lien.
Lorsqu'il reçoit une telle demande, le serveur ne fait pas que retourner la ressource demandée, il en profite pour l'accompagner d'informations diverses à son sujet, dans ce qui s'appelle les en-têtes ou headers HTTP : typiquement, on y trouve des informations comme la longueur des données renvoyées ou encore la date d'envoi.
Enfin, sachez qu'il est possible de transmettre des données au serveur lorsque l'on effectue une requête GET, au travers de paramètres directement placés après l'URL (paramètres nommés query strings) ou de cookies placés dans les en-têtes de la requête : nous reviendrons en temps voulu sur ces deux manières de faire. La limite de ce système est que, comme la taille d'une URL est limitée, on ne peut pas utiliser cette méthode pour envoyer des données volumineuses au serveur, par exemple un fichier.
Les gens qui ont écrit la norme décrivant le protocole HTTP ont émis des recommandations d'usage, que les développeurs sont libres de suivre ou non. Celles-ci précisent que via cette méthode GET, il est uniquement possible de récupérer ou de lire des informations, sans que cela ait un quelconque impact sur la ressource demandée : ainsi, une requête GET est censée pouvoir être répétée indéfiniment sans risques pour la ressource concernée.
POST
La taille du corps du message d'une requête POST n'est pas limitée, c'est donc cette méthode qu'il faut utiliser pour soumettre au serveur des données de tailles variables, ou que l'on sait volumineuses. C'est parfait pour envoyer des fichiers par exemple.
Toujours selon les recommandations d'usage, cette méthode doit être utilisée pour réaliser les opérations qui ont un effet sur la ressource, et qui ne peuvent par conséquent pas être répétées sans l'autorisation explicite de l'utilisateur. Vous avez probablement déjà reçu de votre navigateur un message d'alerte après avoir actualisé une page web, vous prévenant qu'un rafraîchissement de la page entraînera un renvoi des informations : eh bien c'est simplement parce que la page que vous souhaitez recharger a été récupérée via la méthode POST, et que le navigateur vous demande confirmation avant de renvoyer à nouveau la requête. 
HEAD
Cette méthode est identique à la méthode GET, à ceci près que le serveur n'y répondra pas en renvoyant la ressource accompagnée des informations la concernant, mais seulement ces informations. En d'autres termes, il renvoie seulement les en-têtes HTTP ! Il est ainsi possible par exemple de vérifier la validité d'une URL ou de vérifier si le contenu d'une page a changé ou non sans avoir à récupérer la ressource elle-même : il suffit de regarder ce que contiennent les différents champs des en-têtes. Ne vous inquiétez pas, nous y reviendrons lorsque nous manipulerons des fichiers.
Pendant ce temps-là, sur le serveur…
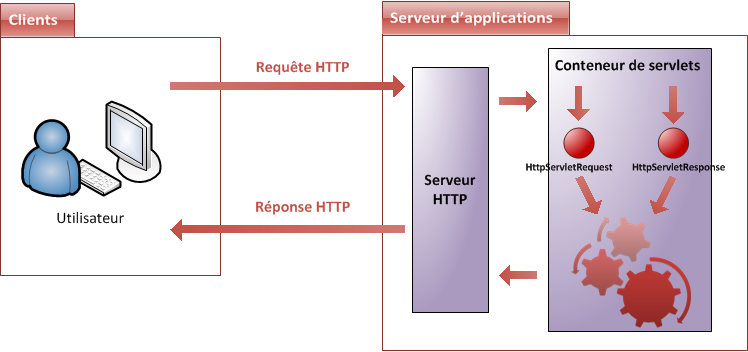
Rappelez-vous notre schéma global : la requête HTTP part du client et arrive sur le serveur. L'élément qui entre en jeu est alors le serveur HTTP (on parle également de serveur web), qui ne fait qu'écouter les requêtes HTTP sur un certain port, en général le port 80.
Que fait-il lorsqu'une requête lui parvient ?
Nous savons déjà qu'il la transmet à un autre élément, que nous avons jusqu'à présent qualifié de conteneur : il s'agit en réalité d'un conteneur de servlets, également nommé conteneur web (voir la figure suivante). Celui-ci va alors créer deux nouveaux objets :
HttpServletRequest: cet objet contient la requête HTTP, et donne accès à toutes ses informations, telles que les en-têtes (headers) et le corps de la requête.HttpServletResponse: cet objet initialise la réponse HTTP qui sera renvoyée au client, et permet de la personnaliser, en initialisant par exemple les en-têtes et le corps (nous verrons comment par la suite).
Et ensuite ? Que fait-il de ce couple d'objets ?
Eh bien à ce moment précis, c'est votre code qui va entrer en jeu (représenté par la série de rouages sur le schéma). En effet, le conteneur de servlets va les transmettre à votre application, et plus précisément aux servlets et filtres que vous avez éventuellement mis en place. Le cheminement de la requête dans votre code commence à peine, et nous devons déjà nous arrêter : qu'est-ce qu'une servlet ?
Création
Une servlet est en réalité une simple classe Java, qui a la particularité de permettre le traitement de requêtes et la personnalisation de réponses. Pour faire simple, dans la très grande majorité des cas une servlet n'est rien d'autre qu'une classe capable de recevoir une requête HTTP envoyée depuis le navigateur de l'utilisateur, et de lui renvoyer une réponse HTTP. C'est tout !
En principe, une servlet dans son sens générique est capable de gérer n'importe quel type de requête, mais dans les faits il s'agit principalement de requêtes HTTP. Ainsi, l'usage veut qu'on ne s'embête pas à préciser "servlet HTTP" lorsque l'on parle de ces dernières, et il est donc extrêmement commun d'entendre parler de servlets alors qu'il s'agit bien en réalité de servlets HTTP. Dans la suite de ce cours, je ferai de même.
Un des avantages de la plate-forme Java EE est sa documentation : très fournie et offrant un bon niveau de détails, la Javadoc permet en un rien de temps de se renseigner sur une classe, une interface ou un package de l'API Java EE. Tout au long de ce cours, je mettrai à votre disposition des liens vers les documentations des objets importants, afin que vous puissiez facilement, par vous-mêmes, compléter votre apprentissage et vous familiariser avec ce système de documentation.
Regardons donc ce qu'elle contient au chapitre concernant le package servlet : on y trouve une quarantaine de classes et interfaces, parmi lesquelles l'interface nommée Servlet. En regardant celle-ci de plus près, on apprend alors qu'elle est l'interface mère que toute servlet doit obligatoirement implémenter.
Mieux encore, on apprend en lisant sa description qu'il existe déjà des classes de base qui l'implémentent, et qu'il nous suffit donc d'hériter d'une de ces classes pour créer une servlet (voir la figure suivante).

Nous souhaitons traiter des requêtes HTTP, nous allons donc faire hériter notre servlet de la classe HttpServlet !
De retour sur votre projet Eclipse, faites un clic droit sur le répertoire src, puis choisissez New > Class. Renseignez alors la fenêtre qui s'ouvre comme indiqué sur les figures suivantes.
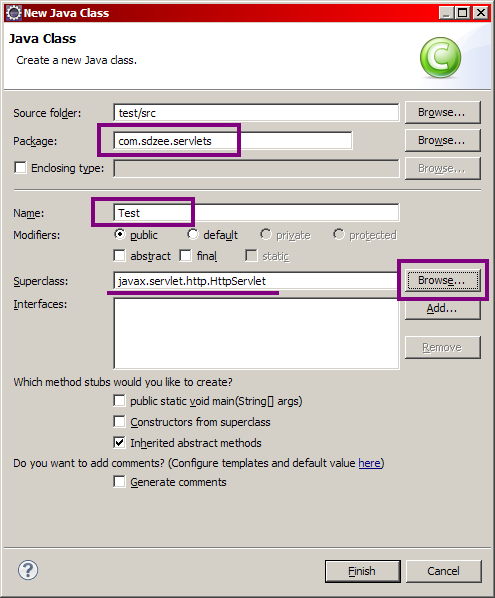
Renseignez le champ package par un package de votre choix : pour notre projet, j'ai choisi de le nommer com.sdzee.servlets !
Renseignez le nom de la servlet, puis cliquez ensuite sur le bouton Browse… afin de définir de quelle classe doit hériter notre servlet, puis allez chercher la classe HttpServlet et validez. Voici le code que vous obtenez alors automatiquement :
1 2 3 4 5 6 7 | package com.sdzee.servlets; import javax.servlet.http.HttpServlet; public class Test extends HttpServlet { } |
com.sdzee.servlets.Test
Rien d'extraordinaire pour le moment, notre servlet étant absolument vide. D'ailleurs puisqu'elle ne fait encore rien, sautons sur l'occasion pour prendre le temps de regarder ce que contient cette classe HttpServlet héritée, afin de voir un peu ce qui se passe derrière. La Javadoc nous donne des informations utiles concernant le fonctionnement de cette classe : pour commencer c'est une classe abstraite, ce qui signifie qu'on ne pourra pas l'utiliser telle quelle et qu'il sera nécessaire de passer par une servlet qui en hérite. On apprend ensuite que la classe propose les méthodes Java nécessaires au traitement des requêtes et réponses HTTP ! Ainsi, on y trouve les méthodes :
doGet()pour gérer la méthode GET ;doPost()pour gérer la méthode POST ;doHead()pour gérer la méthode HEAD.
Comment la classe fait-elle pour associer chaque type de requête HTTP à la méthode Java qui lui correspond ?
Vous n'avez pas à vous en soucier, ceci est géré automatiquement par sa méthode service() : c'est elle qui se charge de lire l'objet HttpServletRequest et de distribuer la requête HTTP à la méthode doXXX() correspondante.
Ce qu'il faut retenir pour le moment :
- une servlet HTTP doit hériter de la classe abstraite HttpServlet ;
- une servlet doit implémenter au moins une des méthodes doXXX(), afin d'être capable de traiter une requête entrante.
Puisque ce sont elles qui prennent en charge les requêtes entrantes, les servlets vont être les points d'entrée de notre application web, c'est par elles que tout va passer. Contrairement au Java SE, il n'existe pas en Java EE de point d'entrée unique prédéfini, comme pourrait l'être la méthode main()…
Mise en place
Vous le savez, les servlets jouent un rôle très particulier dans une application. Je vous ai parlé d'aiguilleurs en introduction, on peut encore les voir comme des gendarmes : si les requêtes étaient des véhicules, les servlets seraient chargées de faire la circulation sur le gigantesque carrefour qu'est votre application ! Eh bien pour obtenir cette autorité et être reconnues en tant que telles, les servlets nécessitent un traitement de faveur : il va falloir les enregistrer auprès de notre application.
Revenons à notre exemple. Maintenant que nous avons codé notre première servlet, il nous faut donc un moyen de faire comprendre à notre application que notre servlet existe, à la fois pour lui donner l'autorité sur les requêtes et pour la rendre accessible au public ! Lorsque nous avions mis en place une page HTML statique dans le chapitre précédent, le problème ne se posait pas : nous accédions directement à la page en question via une URL directe pointant vers le fichier depuis notre navigateur.
Mais dans le cas d'une servlet qui, rappelons-le, est une classe Java, comment faire ?
Concrètement, il va falloir configurer quelque part le fait que notre servlet va être associée à une URL. Ainsi lorsque le client la saisira, la requête HTTP sera automatiquement aiguillée par notre conteneur de servlet vers la bonne servlet, celle qui est en charge de répondre à cette requête. Ce "quelque part" se présente sous la forme d'un simple fichier texte : le fichier web.xml.
C'est le cœur de votre application : ici vont se trouver tous les paramètres qui contrôlent son cycle de vie. Nous n'allons pas apprendre d'une traite toutes les options intéressantes, mais y aller par étapes. Commençons donc par apprendre à lier notre servlet à une URL : après tous les efforts que nous avons fournis, c'est le minimum syndical que nous sommes en droit de lui demander ! 
Ce fichier de configuration doit impérativement se nommer web.xml et se situer juste sous le répertoire /WEB-INF de votre application. Si vous avez suivi à la lettre la procédure de création de notre projet web, alors ce fichier est déjà présent. Éditez-le, et supprimez le contenu généré par défaut. Si jamais le fichier est absent de votre arborescence, créez simplement un nouveau fichier XML en veillant bien à le placer sous le répertoire /WEB-INF et à le nommer web.xml. Voici la structure à vide du fichier :
1 2 3 4 5 6 7 8 | <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> </web-app> |
Fichier /WEB-INF/web.xml vide
L'intégralité de son contenu devra être placée entre les balises <web-app> et </web-app>.
Pour le moment, ne prêtez pas attention aux nombreux attributs présents au sein de cette balise <web-app>, nous reviendrons sur leur rôle lorsque nous découvrirons les expressions EL.
La mise en place d'une servlet se déroule en deux étapes : nous devons d'abord déclarer la servlet, puis lui faire correspondre une URL.
Définition de la servlet
La première chose à faire est de déclarer notre servlet : en quelque sorte il s'agit de lui donner une carte d'identité, un moyen pour le serveur de la reconnaître. Pour ce faire, il faut ajouter une section au fichier qui se présente ainsi sous sa forme minimale :
1 2 3 4 | <servlet> <servlet-name>Test</servlet-name> <servlet-class>com.sdzee.servlets.Test</servlet-class> </servlet> |
Déclaration de notre servlet
La balise responsable de la définition d'une servlet se nomme logiquement <servlet>, et les deux balises obligatoires de cette section sont très explicites :
<servlet-name>permet de donner un nom à une servlet. C'est ensuite via ce nom qu'on fera référence à la servlet en question. Ici, j'ai nommé notre servlet Test.<servlet-class>sert à préciser le chemin de la classe de la servlet dans votre application. Ici, notre classe a bien pour nom Test et se situe bien dans le package com.sdzee.servlets.
Bonne pratique : gardez un nom de classe et un nom de servlet identiques. Bien que ce ne soit en théorie pas nécessaire, cela vous évitera des ennuis ou des confusions par la suite.
Il est par ailleurs possible d'insérer au sein de la définition d'une servlet d'autres balises facultatives :
1 2 3 4 5 6 7 8 9 10 11 12 13 | <servlet> <servlet-name>Test</servlet-name> <servlet-class>com.sdzee.servlets.Test</servlet-class> <description>Ma première servlet de test.</description> <init-param> <param-name>auteur</param-name> <param-value>Coyote</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> |
Déclaration de notre servlet avec options
On découvre ici trois nouveaux blocs :
<description>permet de décrire plus amplement le rôle de la servlet. Cette description n'a aucune utilité technique et n'est visible que dans ce fichier ;<init-param>permet de préciser des paramètres qui seront accessibles à la servlet lors de son chargement. Nous y reviendrons en détail plus tard dans ce cours ;<load-on-startup>permet de forcer le chargement de la servlet dès le démarrage du serveur. Nous reviendrons sur cet aspect un peu plus loin dans ce chapitre.
Mapping de la servlet
Il faut ensuite faire correspondre notre servlet fraîchement déclarée à une URL, afin qu'elle soit joignable par les clients :
1 2 3 4 | <servlet-mapping> <servlet-name>Test</servlet-name> <url-pattern>/toto</url-pattern> </servlet-mapping> |
Mapping de notre servlet sur l'URL relative /toto
La balise responsable de la définition du mapping se nomme logiquement <servlet-mapping>, et les deux balises obligatoires de cette section sont, là encore, très explicites.
<servlet-name>permet de préciser le nom de la servlet à laquelle faire référence. Cette information doit correspondre avec le nom défini dans la précédente déclaration de la servlet.<url-pattern>permet de préciser la ou les URL relatives au travers desquelles la servlet sera accessible. Ici, ça sera /toto !
Pourquoi un "pattern" et pas simplement une URL ?
En effet il s'agit bien d'un pattern, c'est-à-dire d'un modèle, et pas nécessairement d'une URL fixe. Ainsi, on peut choisir de rendre notre servlet responsable du traitement des requêtes issues d'une seule URL, ou bien d'un groupe d'URL. Vous n'imaginez pour le moment peut-être pas de cas qui impliqueraient qu'une servlet doive traiter les requêtes issues de plusieurs URL, mais rassurez-vous nous ferons la lumière sur ce type d'utilisation dans la partie suivante de ce cours. De même, nous découvrirons qu'il est tout à fait possible de déclarer plusieurs sections <servlet-mapping> pour une même section <servlet> dans le fichier web.xml.
Que signifie "URL relative" ?
Cela veut dire que l'URL ou le pattern que vous renseignez dans le champ <url-pattern> sont basés sur le contexte de votre application. Dans notre cas, souvenez-vous du contexte de déploiement que nous avons précisé lorsque nous avons créé notre projet web : nous l'avions appelé test. Nous en déduisons donc que notre <url-pattern>/toto</url-pattern> fait référence à l'URL absolue /test/toto.
Nous y voilà, notre servlet est maintenant joignable par le client via l'URL http://localhost:8080/test/toto.
Pour information, le code final de notre fichier web.xml est donc :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" version="3.0"> <servlet> <servlet-name>Test</servlet-name> <servlet-class>com.sdzee.servlets.Test</servlet-class> </servlet> <servlet-mapping> <servlet-name>Test</servlet-name> <url-pattern>/toto</url-pattern> </servlet-mapping> </web-app> |
/WEB-INF/web.xml
L'ordre des sections de déclaration au sein du fichier est important : il est impératif de définir une servlet avant de spécifier son mapping.
Mise en service
Do you « GET » it?
Nous venons de créer un fichier de configuration pour notre application, nous devons donc redémarrer notre serveur pour que ces modifications soient prises en compte. Il suffit pour cela de cliquer sur le bouton "start" de l'onglet Servers, comme indiqué à la figure suivante.

Faisons le test, et observons ce que nous affiche notre navigateur lorsque nous tentons d'accéder à l'URL http://localhost:8080/test/toto que nous venons de mapper sur notre servlet (voir la figure suivante).
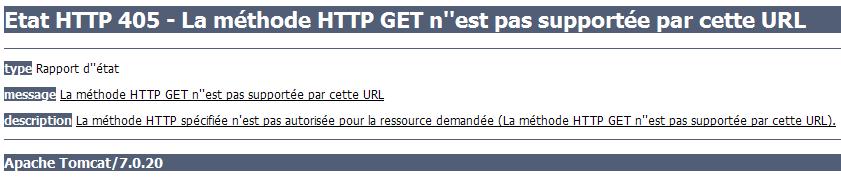
Nous voici devant notre premier code de statut HTTP. En l'occurrence, c'est à la fois une bonne et une mauvaise nouvelle :
- une bonne nouvelle, car cela signifie que notre mapping a fonctionné et que notre serveur a bien contacté notre servlet !
- une mauvaise nouvelle, car notre serveur nous retourne le code d'erreur 405 et nous précise que la méthode GET n'est pas supportée par la servlet que nous avons associée à l'URL…
Par qui a été générée cette page d'erreur ?
Tout est parti du conteneur de servlets. D'ailleurs, ce dernier effectue pas mal de choses dans l'ombre, sans vous le dire ! Dans ce cas précis, il a :
- reçu la requête HTTP depuis le serveur web ;
- généré un couple d'objets requête/réponse ;
- parcouru le fichier web.xml de votre application à la recherche d'une entrée correspondant à l'URL contenue dans l'objet requête ;
- trouvé et identifié la servlet que vous y avez déclarée ;
- contacté votre servlet et transmis la paire d'objets requête/réponse.
Dans ce cas, pourquoi cette page d'erreur a-t-elle été générée ?
Nous avons pourtant bien fait hériter notre servlet de la classe HttpServlet, notre servlet doit pouvoir interagir avec HTTP ! Qu'est-ce qui cloche ? Eh bien nous avons oublié une chose importante : afin que notre servlet soit capable de traiter une requête HTTP de type GET, il faut y implémenter une méthode… doGet() ! Souvenez-vous, je vous ai déjà expliqué que la méthode service() de la classe HttpServlet s'occupera alors elle-même de transmettre la requête GET entrante vers la méthode doGet() de notre servlet… Ça vous revient ?
Maintenant, comment cette page d'erreur a-t-elle été générée ?
C'est la méthode doGet() de la classe mère HttpServlet qui est en la cause. Ou plutôt, disons que c'est grâce à elle ! En effet, le comportement par défaut des méthodes doXXX() de la classe HttpServlet est de renvoyer un code d'erreur HTTP 405 ! Donc si le développeur a bien fait son travail, pas de problème : c'est bien la méthode doXXX() de la servlet qui sera appelée. Par contre, s'il a mal fait son travail et a oublié de surcharger la méthode doXXX() voulue, alors c'est la méthode de la classe mère HttpServlet qui sera appelée, et un code d'erreur sera gentiment et automatiquement renvoyé au client. Ainsi, la classe mère s'assure toujours que sa classe fille - votre servlet ! - surcharge bien la méthode doXXX() correspondant à la méthode HTTP traitée !
Par ailleurs, votre conteneur de servlets est également capable de générer lui-même des codes d'erreur HTTP. Par exemple, lorsqu'il parcourt le fichier web.xml de votre application à la recherche d'une entrée correspondant à l'URL envoyée par le client, et qu'il ne trouve rien, c'est lui qui va se charger de générer le fameux code d'erreur 404 !
Nous voilà maintenant au courant de ce qu'il nous reste à faire : il nous suffit de surcharger la méthode doGet() de la classe HttpServlet dans notre servlet Test. Voici donc le code de notre servlet :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.sdzee.servlets; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class Test extends HttpServlet { public void doGet( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException{ } } |
Surcharge de la méthode doGet() dans notre servlet Test
Comme vous pouvez le constater, l'ajout de cette seule méthode vide fait intervenir plusieurs imports qui définissent les objets et exceptions présents dans la signature de la méthode : HttpServletRequest, HttpServletResponse, ServletException et IOException.
Réessayons alors de contacter notre servlet via notre URL : tout se passe comme prévu, le message d'erreur HTTP disparaît. Cela dit, notre servlet ne fait strictement rien de la requête HTTP reçue : le navigateur nous affiche alors une page… blanche !
Comment le client sait-il que la requête est arrivée à bon port ?
C'est une très bonne remarque. En effet, si votre navigateur vous affiche une simple page blanche, c'est parce qu'il considère la requête comme terminée avec succès : si ce n'était pas le cas, il vous afficherait un des codes et messages d'erreur HTTP… (voir la figure suivante). Si vous utilisez le navigateur Firefox, vous pouvez utiliser l'onglet Réseau de l'outil Firebug pour visualiser qu'effectivement, une réponse HTTP est bien reçue par votre navigateur (si vous utilisez le navigateur Chrome, vous pouvez accéder à un outil similaire en appuyant sur F12 ).
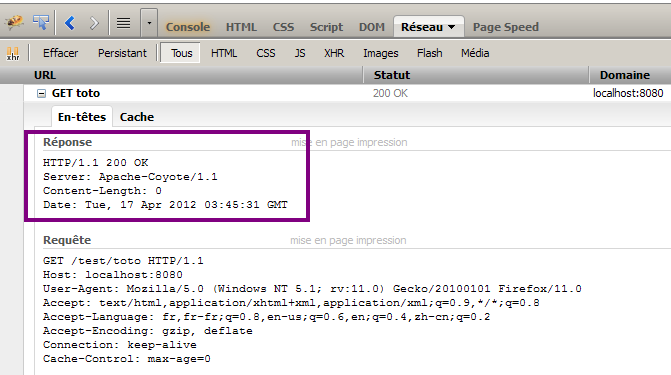
On y observe :
- un code HTTP 200 OK, qui signifie que la requête s'est effectuée avec succès ;
- la longueur des données contenues dans la réponse (Content-Length) : 0…
Eh bien encore une fois, c'est le conteneur de servlets qui a fait le boulot sans vous prévenir ! Quand il a généré la paire d'objets requête/réponse, il a initialisé le statut de la réponse avec une valeur par défaut : 200. C'est-à-dire que par défaut, le conteneur de servlets crée un objet réponse qui stipule que tout s'est bien passé. Ensuite, il transmet cet objet à votre servlet, qui est alors libre de le modifier à sa guise. Lorsqu'il reçoit à nouveau l'objet en retour, si le code de statut n'a pas été modifié par la servlet, c'est que tout s'est bien passé. En d'autres termes, le conteneur de servlets adopte une certaine philosophie : pas de nouvelles, bonne nouvelle !
Le serveur retourne donc toujours une réponse au client, peu importe ce que fait notre servlet avec la requête ! Dans notre cas, la servlet n'effectue aucune modification sur l'objet HttpServletResponse, et par conséquent n'y insère aucune donnée et n'y modifie aucun en-tête. D'où la longueur initialisée à zéro dans l'en-tête de la réponse, le code de statut initialisé à 200… et la page blanche en guise de résultat final !
Cycle de vie d'une servlet
Dans certains cas, il peut s'avérer utile de connaître les rouages qui se cachent derrière une servlet. Toutefois, je ne souhaite pas vous embrouiller dès maintenant : vous n'en êtes qu'aux balbutiements de votre apprentissage et n'avez pas assez d'expérience pour intervenir proprement sur l'initialisation d'une servlet. Je ne vais par conséquent qu'aborder rapidement son cycle de vie au sein du conteneur, à travers ce court aparté. Nous lèverons le voile sur toute cette histoire dans un chapitre en annexe de ce cours, et en profiterons pour utiliser le puissant outil de debug d'Eclipse !
Quand une servlet est demandée pour la première fois ou quand l'application web démarre, le conteneur de servlets va créer une instance de celle-ci et la garder en mémoire pendant toute l'existence de l'application. La même instance sera réutilisée pour chaque requête entrante dont les URL correspondent au pattern d'URL défini pour la servlet. Dans notre exemple, aussi longtemps que notre serveur restera en ligne, tous nos appels vers l'URL /test/toto seront dirigés vers la même et unique instance de notre servlet, générée par Tomcat lors du tout premier appel.
En fin de compte, l'instance d'une servlet est-elle créée lors du premier appel à cette servlet, ou bien dès le démarrage du serveur ?
Ceci dépend en grande partie du serveur d'applications utilisé. Dans notre cas, avec Tomcat, c'est par défaut au premier appel d'une servlet que son unique instance est créée.
Toutefois, ce mode de fonctionnement est configurable. Plus tôt dans ce chapitre, je vous expliquais comment déclarer une servlet dans le fichier web.xml, et j'en ai profité pour vous présenter une balise facultative : <load-on-startup>N</load-on-startup>, où N doit être un entier positif. Si dans la déclaration d'une servlet vous ajoutez une telle ligne, alors vous ordonnez au serveur de charger l'instance de la servlet en question directement pendant le chargement de l'application.
Le chiffre N correspond à la priorité que vous souhaitez donner au chargement de votre servlet. Dans notre projet nous n'utilisons pour le moment qu'une seule servlet, donc nous pouvons marquer n'importe quel chiffre supérieur ou égal à zéro, ça ne changera rien. Mais dans le cas d'une application contenant beaucoup de servlets, cela permet de définir quelle servlet doit être chargée en premier. L'ordre est établi du plus petit au plus grand : la ou les servlets ayant un load-on-startup initialisé à zéro sont les premières à être chargées, puis 1, 2, 3, etc.
Voilà tout pour cet aparté. En ce qui nous concerne, nous n'utiliserons pas cette option de chargement dans nos projets, le chargement des servlets lors de leur première sollicitation nous ira très bien ! 
Envoyer des données au client
Avec tout cela, nous n'avons encore rien envoyé à notre client, alors qu'en mettant en place une simple page HTML nous avions affiché du texte dans le navigateur du client en un rien de temps. Patience, les réponses vont venir… Utilisons notre servlet pour reproduire la page HTML statique que nous avions créée lors de la mise en place de Tomcat. Comme je vous l'ai expliqué dans le paragraphe précédent, pour envoyer des données au client il va falloir manipuler l'objet HttpServletResponse. Regardons d'abord ce qu'il est nécessaire d'inclure à notre méthode doGet(), et analysons tout cela ensuite :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | public void doGet( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException{ response.setContentType("text/html"); response.setCharacterEncoding( "UTF-8" ); PrintWriter out = response.getWriter(); out.println("<!DOCTYPE html>"); out.println("<html>"); out.println("<head>"); out.println("<meta charset=\"utf-8\" />"); out.println("<title>Test</title>"); out.println("</head>"); out.println("<body>"); out.println("<p>Ceci est une page générée depuis une servlet.</p>"); out.println("</body>"); out.println("</html>"); } |
Comment procédons-nous ?
- Nous commençons par modifier l'en-tête Content-Type de la réponse HTTP, pour préciser au client que nous allons lui envoyer une page HTML, en faisant appel à la méthode
setContentType()de l'objetHttpServletResponse. - Par défaut, l'encodage de la réponse envoyée au client est initialisé à ISO-8859-1. Si vous faites quelques recherches au sujet de cet encodage, vous apprendrez qu'il permet de gérer sans problème les caractères de notre alphabet, mais qu'il ne permet pas de manipuler les caractères asiatiques, les alphabets arabes, cyrilliques, scandinaves ainsi que d'autres caractères plus exotiques. Afin de permettre une gestion globale d'un maximum de caractères différents, il est recommandé d'utiliser l'encodage UTF-8 à la place. Voilà pourquoi nous modifions l'encodage par défaut en réalisant un appel à la méthode
setCharacterEncoding()de l'objetHttpServletResponse. Par ailleurs, c'est également pour cette raison que je vous ai fait modifier les encodages par défaut lors de la configuration d'Eclipse !
Si vous regardez la documentation de cette méthode, vous découvrirez qu'il est également possible de s'en passer et d'initialiser l'encodage de la réponse directement via un appel à la méthode setContentType( "text/html; charset=UTF-8").
- Nous récupérons ensuite un objet
PrintWriterqui va nous permettre d'envoyer du texte au client, via la méthodegetWriter()de l'objetHttpServletResponse. Vous devrez donc importerjava.io.PrintWriterdans votre servlet. Cet objet utilise l'encodage que nous avons défini précédemment, c'est-à-dire UTF-8. - Nous écrivons alors du texte dans la réponse via la méthode
println()de l'objetPrintWriter.
Enregistrez, testez et vous verrez enfin la page s'afficher dans votre navigateur : ça y est, vous savez maintenant utiliser une servlet et transmettre des données au client.
Rien que pour reproduire ce court et pauvre exemple, il nous a fallu 10 appels à out.println() ! Lorsque nous nous attaquerons à des pages web un peu plus complexes que ce simple exemple, allons-nous devoir écrire tout notre code HTML à l'intérieur de ces méthodes println() ?
Non, bien sûr que non ! Vous imaginez un peu l'horreur si c'était le cas ?! Si vous avez suivi le topo sur MVC, vous vous souvenez d'ailleurs que la servlet n'est pas censée s'occuper de l'affichage, c'est la vue qui doit s'en charger ! Et c'est bien pour ça que je ne vous ai rien fait envoyer d'autre que cette simple page d'exemple HTML… Toutefois, même si nous ne procéderons plus jamais ainsi pour la création de nos futures pages web, il était très important que nous découvrions comment cela se passe.
Pour le moment, voici à la figure suivante ce que nous avons réalisé.
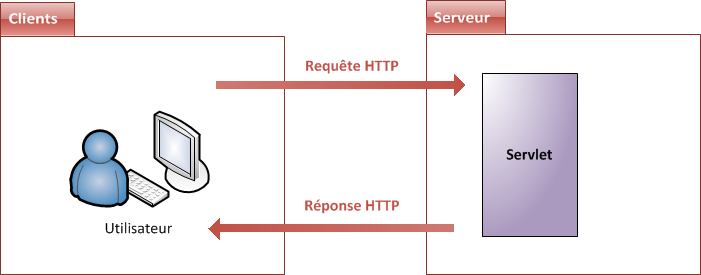
Note : dorénavant et afin d'alléger les schémas, je ne représenterai plus le serveur HTTP en amont du conteneur. Ici, le bloc intitulé "Serveur" correspond en réalité au conteneur de servlets.
Pour information, nous nous resservirons plus tard de cette technique d'envoi direct de données depuis une servlet, lorsque nous manipulerons des fichiers.
La leçon à retenir en cette fin de chapitre est claire : le langage Java n'est pas du tout adapté à la rédaction de pages web ! Notre dernier exemple en est une excellente preuve, et il nous faut nous orienter vers quelque chose de plus efficace.
Il est maintenant grand temps de revenir au modèle MVC : l'affichage de contenu HTML n'ayant rien à faire dans le contrôleur (notre servlet), nous allons créer une vue et la mettre en relation avec notre servlet.
- Le client envoie des requêtes au serveur grâce aux méthodes du protocole HTTP, notamment GET, POST et HEAD.
- Le conteneur web place chaque requête reçue dans un objet
HttpServletRequest, et place chaque réponse qu'il initialise dans l'objetHttpServletResponse. - Le conteneur transmet chaque couple requête/réponse à une servlet : c'est un objet Java assigné à une requête et capable de générer une réponse en conséquence.
- La servlet est donc le point d'entrée d'une application web, et se déclare dans son fichier de configuration web.xml.
- Une servlet peut se charger de répondre à une requête en particulier, ou à un groupe entier de requêtes.
- Pour pouvoir traiter une requête HTTP de type GET, une servlet doit implémenter la méthode
doGet(); pour répondre à une requête de type POST, la méthodedoPost(); etc. - Une servlet n'est pas chargée de l'affichage des données, elle ne doit donc pas s'occuper de la présentation (HTML, CSS, etc.).