Mettons-nous maintenant du côté du client : comment permettre aux utilisateurs de récupérer un fichier présent sur le serveur ? Nous pourrions nous contenter de placer nos documents dans un répertoire du serveur accessible au public, et de leur donner des liens directs vers les fichiers, mais :
- c'est une mauvaise pratique, pour les raisons évoquées dans le chapitre précédent ;
- nous sommes fidèles à MVC, et nous aimons bien tout contrôler : un seul point d'entrée pour les téléchargements, pas cinquante !
C'est dans cette optique que nous allons réaliser une servlet qui aura pour unique objectif de permettre aux clients de télécharger des fichiers.
Une servlet dédiée
Les seules ressources auxquelles l'utilisateur peut accéder depuis son navigateur sont les fichiers et dossiers placés sous la racine de votre application, c'est-à-dire sous le dossier WebContent de votre projet Eclipse, à l'exception bien entendu du répertoire privé /WEB-INF. Ainsi, lorsque vous enregistrez vos fichiers en dehors de votre application web (ailleurs sur le disque dur, ou bien sur un FTP distant, dans une base de données, etc.), le client ne peut pas y accéder directement par une URL.
Une des solutions possibles est alors de créer une servlet dont l'unique objectif est de charger ces fichiers depuis le chemin en dehors du conteneur web (ou depuis une base de données, mais nous y reviendrons bien plus tard), et de les transmettre en flux continu (en anglais, on parle de streaming) à l'objet HttpServletResponse. Le client va alors visualiser sur son navigateur une fenêtre de type "Enregistrer sous…". Comment procéder ? Regardons tout cela étape par étape…
Création de la servlet
Pour commencer nous allons créer une ébauche de servlet, que nous allons nommer Download et placer dans com.sdzee.servlets :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.sdzee.servlets; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class Download extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { } } |
com.sdzee.servlets.Download
La seule action réalisée par le client sera un clic sur un lien pour télécharger un fichier, notre servlet aura donc uniquement besoin d'implémenter la méthode doGet().
Paramétrage de la servlet
Configurons ensuite l'URL d'accès à notre servlet :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ... <servlet> <servlet-name>Download</servlet-name> <servlet-class>com.sdzee.servlets.Download</servlet-class> </servlet> ... <servlet-mapping> <servlet-name>Download</servlet-name> <url-pattern>/fichiers/*</url-pattern> </servlet-mapping> ... |
/WEB-INF/web.xml
Nous faisons ici correspondre notre servlet à toute URL commençant par /fichiers/, à travers la balise <url-pattern>. Ainsi, toutes les adresses du type http://localhost:8080/pro/fichiers/fichier.ext ou encore http://localhost:8080/pro/fichiers/dossier/fichier.ext pointeront vers notre servlet de téléchargement.
Nous devons maintenant préciser à notre servlet où elle va devoir aller chercher les fichiers sur le disque.
Comment lui faire connaître ce répertoire ?
Il y a plusieurs manières de faire, mais puisque nous avions précisé ce chemin dans le fichier web.xml pour la servlet d'upload, nous allons faire de même avec notre servlet de download ! Si votre mémoire est bonne, vous devez vous souvenir d'une balise optionnelle permettant de préciser à une servlet des paramètres d'initialisation… La balise <init-param>, ça vous dit quelque chose ? 
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ... <servlet> <servlet-name>Download</servlet-name> <servlet-class>com.sdzee.servlets.Download</servlet-class> <init-param> <param-name>chemin</param-name> <param-value>/fichiers/</param-value> </init-param> </servlet> ... <servlet-mapping> <servlet-name>Download</servlet-name> <url-pattern>/fichiers/*</url-pattern> </servlet-mapping> ... |
/WEB-INF/web.xml
En procédant ainsi, nous mettons à disposition de notre servlet un objet qui contient la valeur spécifiée ! Ainsi, côté servlet il nous suffit de lire la valeur associée depuis notre méthode doGet(), vide jusqu'à présent :
1 2 3 4 | public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { /* Lecture du paramètre 'chemin' passé à la servlet via la déclaration dans le web.xml */ String chemin = this.getServletConfig().getInitParameter( "chemin" ); } |
com.sdzee.servlets.Download
Vous retrouvez ici la méthode permettant l'accès aux paramètres d'initialisation getInitParameter(), qui prend en argument le nom du paramètre ciblé.
Analyse du fichier
Maintenant que tout est précisé côté serveur, il nous faut donner au client un moyen de préciser quel fichier il souhaite télécharger. La première idée qui nous vient à l'esprit est évidemment un paramètre de requête, comme nous avons toujours fait jusqu'à présent notamment avec nos formulaires. Oui, mais nous n'allons pas procéder ainsi…
Quel est le problème avec les paramètres de requêtes ?
Le problème, c'est… Internet Explorer, entre autres. Alors que la plupart des navigateurs sont capables de détecter proprement un nom de fichier initialisé dans les en-têtes HTTP, IE ignore tout simplement ce champ et considère lors de l'affichage de la fenêtre "Enregistrer sous…" que le nom du fichier à enregistrer correspond à la fin de l'URL demandée, c'est-à-dire dans notre cas à l'URL de notre servlet de téléchargement ! Autrement dit, il va faire télécharger une page blanche à l'utilisateur. Certains navigateurs sont incapables de détecter correctement le contenu de l'en-tête Content-Type.
Bref, afin d'éviter tous ces ennuis dus aux différentes moutures des navigateurs existant, il nous reste un moyen simple et propre de faire passer notre nom de fichier : l'inclure directement dans l'URL. Autrement dit, faire en sorte qu'il nous suffise d'appeler une URL du type http://localhost:8080/pro/fichiers/test.txt pour télécharger le fichier nommé test.txt !
Pour ce faire, côté servlet nous allons utiliser une méthode de l'objet HttpServletRequest : getPathInfo(). Elle retourne la fraction de l'URL qui correspond à ce qui est situé entre le chemin de base de la servlet et les paramètres de requête. Il faut donc ajouter à notre méthode doGet() la ligne suivante :
1 2 | /* Récupération du chemin du fichier demandé au sein de l'URL de la requête */ String fichierRequis = request.getPathInfo(); |
com.sdzee.servlets.Download
Dans la documentation de la méthode getPathInfo(), nous remarquons qu'elle retourne null si aucun chemin n'existe dans l'URL, et qu'un chemin existant commence toujours par /. Nous devons donc vérifier si un chemin vide est transmis en ajoutant cette condition :
1 2 3 4 5 6 | /* Vérifie qu'un fichier a bien été fourni */ if ( fichierRequis == null || "/".equals( fichierRequis ) ) { /* Si non, alors on envoie une erreur 404, qui signifie que la ressource demandée n'existe pas */ response.sendError(HttpServletResponse.SC_NOT_FOUND); return; } |
com.sdzee.servlets.Download
Vous remarquez ici l'emploi d'une méthode de l'objet HttpServletResponse qui vous était encore inconnue jusque-là : sendError(). Elle permet de retourner au client les messages et codes d'erreur HTTP souhaités. Je vous laisse parcourir la documentation et découvrir par vous-mêmes les noms des différentes constantes représentant les codes d'erreur accessibles ; en l'occurrence celui que j'ai utilisé ici correspond à la fameuse erreur 404. Bien entendu, vous pouvez opter pour quelque chose de moins abrupt, en initialisant par exemple un message d'erreur quelconque que vous transmettez ensuite à une page JSP dédiée, pour affichage à l'utilisateur.
L'étape suivante consiste à contrôler le nom du fichier transmis et à vérifier si un tel fichier existe :
1 2 3 4 5 6 7 8 9 10 | /* Décode le nom de fichier récupéré, susceptible de contenir des espaces et autres caractères spéciaux, et prépare l'objet File */ fichierRequis = URLDecoder.decode( fichierRequis, "UTF-8"); File fichier = new File( chemin, fichierRequis ); /* Vérifie que le fichier existe bien */ if ( !fichier.exists() ) { /* Si non, alors on envoie une erreur 404, qui signifie que la ressource demandée n'existe pas */ response.sendError(HttpServletResponse.SC_NOT_FOUND); return; } |
com.sdzee.servlets.Download
Avant de créer un objet File basé sur le chemin du fichier récupéré, il est nécessaire de convertir les éventuels caractères spéciaux qu'il contient à l'aide de la méthode URLDecoder.decode(). Une fois l'objet créé, là encore si le fichier n'existe pas sur le disque, j'utilise la méthode sendError() pour envoyer une erreur 404 au client et ainsi lui signaler que la ressource demandée n'a pas été trouvée.
Une fois ces contrôles réalisés, il nous faut encore récupérer le type du fichier transmis, à l'aide de la méthode getMimeType() de l'objet ServletContext. Sa documentation nous indique qu'elle retourne le type du contenu d'un fichier en prenant pour argument son nom uniquement. Si le type de contenu est inconnu, alors la méthode renvoie null :
1 2 3 4 5 6 7 | /* Récupère le type du fichier */ String type = getServletContext().getMimeType( fichier.getName() ); /* Si le type de fichier est inconnu, alors on initialise un type par défaut */ if ( type == null ) { type = "application/octet-stream"; } |
com.sdzee.servlets.Download
Pour information, les types de fichiers sont déterminés par le conteneur lui-même. Lorsque le conteneur reçoit une requête demandant un fichier et qu'il le trouve, il le renvoie au client. Dans la réponse HTTP retournée, il renseigne alors l'en-tête Content-Type. Pour ce faire, il se base sur les types MIME dont il a connaissance, en fonction de l'extension du fichier à retourner. Ces types sont spécifiés dans le fichier web.xml global du conteneur, qui est situé dans le répertoire /conf/ du Tomcat Home. Si vous l'éditez, vous verrez qu'il en contient déjà une bonne quantité ! En voici un court extrait :
1 2 3 4 5 6 7 8 9 10 11 12 | ... <mime-mapping> <extension>jpeg</extension> <mime-type>image/jpeg</mime-type> </mime-mapping> <mime-mapping> <extension>jpg</extension> <mime-type>image/jpeg</mime-type> </mime-mapping> ... |
/apache-tomcat-7.0.20/conf/web.xml
Ainsi, il est possible d'ajouter un type inconnu au serveur, il suffit pour cela d'ajouter une section <mime-mapping> au fichier. De même, il est possible d'apporter de telles modifications sur le web.xml de votre projet web, afin de limiter l'impact des changements effectués à votre application uniquement, et non pas à toute instance de Tomcat lancée sur votre poste.
Bref, dans notre cas nous n'allons pas nous embêter : nous nous contentons de spécifier un type par défaut si l'extension du fichier demandée est inconnue.
Génération de la réponse HTTP
Après tous ces petits traitements, nous avons maintenant tout en main pour initialiser une réponse HTTP et y renseigner les en-têtes nécessaires, à savoir :
- Content-Type ;
- Content-Length ;
- Content-Disposition.
Voici donc le code en charge de l'initialisation de la réponse :
1 2 3 4 5 6 7 8 9 10 | private static final int DEFAULT_BUFFER_SIZE = 10240; // 10 ko ... /* Initialise la réponse HTTP */ response.reset(); response.setBufferSize( DEFAULT_BUFFER_SIZE ); response.setContentType( type ); response.setHeader( "Content-Length", String.valueOf( fichier.length() ) ); response.setHeader( "Content-Disposition", "attachment; filename=\"" + fichier.getName() + "\"" ); |
com.sdzee.servlets.Download
Voici quelques explications sur l'enchaînement ici réalisé :
reset(): efface littéralement l'intégralité du contenu de la réponse initiée par le conteneur ;setBufferSize(): méthode à appeler impérativement après unreset();setContentType(): spécifie le type des données contenues dans la réponse ;- nous retrouvons ensuite les deux en-têtes HTTP, qu'il faut construire "à la main" via des appels à
setHeader().
Lecture et envoi du fichier
Nous arrivons enfin à la dernière étape du processus : la lecture du flux et l'envoi au client ! Commençons par mettre en place proprement l'ouverture des flux :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | /* Prépare les flux */ BufferedInputStream entree = null; BufferedOutputStream sortie = null; try { /* Ouvre les flux */ entree = new BufferedInputStream( new FileInputStream( fichier ), TAILLE_TAMPON ); sortie = new BufferedOutputStream( response.getOutputStream(), TAILLE_TAMPON ); /* ... */ } finally { try { sortie.close(); } catch ( IOException ignore ) { } try { entree.close(); } catch ( IOException ignore ) { } } |
com.sdzee.servlets.Download
Nous pourrions ici très bien utiliser directement les flux de type FileInputStream et ServletOutputStream, mais les objets BufferedInputStream et BufferedOutputStream permettent via l'utilisation d'une mémoire tampon une gestion plus souple de la mémoire disponible sur le serveur :
- dans le flux entree, nous ouvrons un
FileInputStreamsur le fichier demandé. Nous décorons ensuite ce flux avec unBufferedInputStream, avec ici un tampon de la même taille que le tampon mis en place sur la réponse HTTP ; - dans le flux sortie, nous récupérons directement le
ServletOutpuStreamdepuis la méthodegetOutputStream()de l'objetHttpServletResponse. Nous décorons ensuite ce flux avec unBufferedOutputStream, avec là encore un tampon de la même taille que le tampon mis en place sur la réponse HTTP.
Encore une fois, je prends la peine de vous détailler l'ouverture des flux. N'oubliez jamais de toujours ouvrir les flux dans un bloc try, et de les fermer dans le bloc finally associé.
Ceci fait, il ne nous reste plus qu'à mettre en place un tampon et à envoyer notre fichier au client, le tout depuis notre bloc try :
1 2 3 4 5 6 | /* Lit le fichier et écrit son contenu dans la réponse HTTP */ byte[] tampon = new byte[TAILLE_TAMPON]; int longueur; while ( ( longueur= entree.read( tampon ) ) > 0 ) { sortie.write( tampon, 0, longueur ); } |
com.sdzee.servlets.Download
À l'aide d'un tableau d'octets jouant le rôle de tampon, la boucle mise en place parcourt le fichier et l'écrit, morceau par morceau, dans la réponse.
Nous y voilà finalement : notre servlet de téléchargement est opérationnelle ! Vous pouvez télécharger son code intégral en cliquant sur ce lien.
Vérification de la solution
Avec une telle servlet mise en place, les clients peuvent dorénavant télécharger sur leur poste les fichiers qui sont présents sous le répertoire /fichiers du disque du serveur sur lequel tourne votre application. Je vous l'ai déjà précisé dans le chapitre précédent, en ce qui me concerne, avec la configuration en place sur mon poste, ce répertoire pointe vers c:\fichiers.
Ainsi, si je veux qu'un client puisse télécharger un fichier test.txt depuis mon application, il me suffit de le placer dans c:\fichiers ! Le client devra alors saisir l'URL http://localhost:8080/pro/fichiers/test.txt dans son navigateur et obtiendra le résultat suivant si le fichier existe bien sur mon serveur (voir la figure suivante).
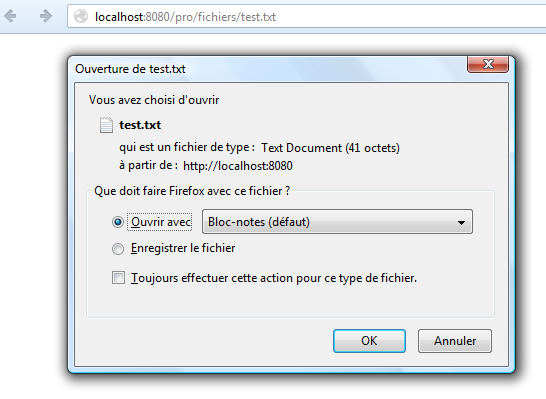
Et il obtiendra logiquement une erreur 404 si le fichier n'existe pas sur le serveur.
De même, vous pouvez vérifier qu'il obtiendra la même erreur s'il essaie d'accéder à la servlet de téléchargement sans préciser un nom de fichier, via l'URL http://localhost:8080/pro/fichiers/.
Une solution plus simple
Je vais maintenant vous faire découvrir une manière de faire, bien moins chronophage, mais qui n'existe que sur certains serveurs d'applications.
En effet, si nous utilisions le serveur GlassFish en lieu et place de Tomcat, nous n'aurions tout bonnement pas besoin d'écrire une servlet dédiée au téléchargement de fichiers placés à l'extérieur du conteneur !
Comment est-ce possible ?
Eh bien il se trouve que le serveur d'Oracle est livré avec une fonctionnalité très intéressante qui permet littéralement de "monter" un répertoire externe au conteneur dans une application web : les Alternate Document Roots.
Le principe est relativement simple : il s'agit d'un système qui permet de mettre en place une correspondance automatique entre des URL qui suivent un format particulier, et un répertoire du disque local sur lequel le serveur tourne. Par exemple, pour notre exemple il nous suffirait de définir que toute URL respectant le pattern **/pro/fichiers/ pointe vers son équivalent *c:\fichiers*. La mise en place de ce mécanisme se fait via l'ajout d'une section dans l'équivalent du fichier web.xml sous GlassFish. Si vous utilisez ce serveur et souhaitez faire le test, je vous laisse parcourir la documentation du système pour plus d'informations, elle est en anglais mais reste très accessible, même pour un débutant. 
L'état d'un téléchargement
Notre précédente servlet vous paraît peut-être un peu compliquée, mais elle ne fait en réalité qu'obtenir un InputStream de la ressource désirée, et l'écrire dans l'OutputStream de la réponse HTTP, accompagné d'en-têtes modifiés. C'est une approche plutôt simpliste, car elle ne permet pas de connaître l'état du téléchargement en cours : autrement dit, en cas de coupure côté client il est impossible de lui proposer la reprise d'un téléchargement en cours.
Pourtant, lorsqu'un utilisateur télécharge un fichier massif et subit un problème de réseau quelconque en cours de route, par exemple à 99% du fichier… il aimerait bien que nous ayons sauvegardé l'état de son précédent téléchargement, et que nous lui proposions à son retour de poursuivre là où il s'était arrêté, et de télécharger uniquement le 1% restant !
Comment proposer la reprise d'un téléchargement ?
Le principe se corse un peu dès lors qu'on souhaite proposer ce type de service. Depuis notre servlet, il faudrait manipuler au minimum trois nouveaux en-têtes de la réponse HTTP afin d'activer cette fonctionnalité.
- Accept-Ranges : cet en-tête de réponse, lorsqu'il contient la valeur "bytes", informe le client que le serveur supporte les requêtes demandant une plage définie de données. Avec cette information, le client peut alors demander une section particulière d'un fichier à travers l'en-tête de requête Range.
- ETag : cet en-tête de réponse doit contenir une valeur unique permettant d'identifier le fichier concerné. Il est possible d'utiliser le système de votre choix, il n'y a aucune contrainte : tout ce qui importe, c'est que chacune des valeurs associées à un fichier soit unique. Certains serveurs utilisent par exemple l'algorithme MD5 pour générer un hash basé sur le contenu du fichier, d'autres utilisent une combinaison d'informations à propos du fichier (son nom, sa taille, sa date de modification, etc.), d'autres génèrent un hash de cette combinaison… Avec cette information, le client peut alors renvoyer l'identifiant obtenu au serveur à travers l'en-tête de requête If-Match ou If-Range, et le serveur peut alors déterminer de quel fichier il est question.
- Last-Modified : cet en-tête de réponse doit contenir un timestamp, qui représente la date de la dernière modification du fichier côté serveur. Avec cette information, le client peut alors renvoyer le timestamp obtenu au serveur à travers l'en-tête de requête If-Unmodified-Since, ou bien là encore If-Range.
À propos de ce dernier en-tête, note importante : un timestamp Java est précis à la milliseconde près, alors que le timestamp attendu dans l'en-tête n'est précis qu'à la seconde près. Afin de combler cet écart d'incertitude, il est donc nécessaire d'ajouter une seconde à la date de modification retournée par le client dans sa requête, avant de la traiter.
Bref, vous l'aurez compris la manœuvre devient vite bien plus compliquée dès lors que l'on souhaite réaliser quelque chose de plus évolué et user-friendly ! Il n'est rien d'insurmontable pour vous, mais ce travail requiert de la patience, une bonne lecture du protocole HTTP, une bonne logique de traitement dans votre servlet et enfin une campagne de tests très poussée, afin de ne laisser passer aucun cas particulier ni aucune erreur. Quoi qu'il en soit, vous avez ici toutes les informations clés pour mettre en place un tel système !
En ce qui nous concerne, nous allons, dans le cadre de ce cours, nous contenter de notre servlet simpliste, le principe y est posé et l'intérêt pédagogique d'un système plus complexe serait d'autant plus faible. 
Réaliser des statistiques
Avec notre servlet en place, nous avons centralisé la gestion des fichiers demandés par les clients, qui passent dorénavant tous par cette unique passerelle de sortie. Si vous envisagez dans une application de réaliser des statistiques sur les téléchargements effectués par les utilisateurs, il est intuitif d'envisager la modification de cette servlet pour qu'elle relève les données souhaitées : combien de téléchargements par fichier, combien de fichiers par utilisateur, combien de téléchargements simultanés, la proportion d'images téléchargées par rapport aux autres types de fichiers, etc. Bref, n'importe quelle information dont vous auriez besoin.
Seulement comme vous le savez, nous essayons de garder nos contrôleurs les plus légers possibles, et de suivre au mieux MVC. Voilà pourquoi cette servlet, unique dans l'application, ne va en réalité pas se charger de cette tâche.
Dans ce cas, où réaliser ce type de traitements ?
Si vous réfléchissez bien à cette problématique, la solution est évidente : le composant idéal pour s'occuper de ce type de traitements, c'est le filtre ! Il suffit en effet d'en appliquer un sur le pattern /fichiers/* pour que celui-ci ait accès à toutes les demandes de téléchargement effectuées par les clients. Le nombre et la complexité des traitements qu'il devra réaliser dépendront bien évidemment des informations que vous souhaitez collecter. En ce qui concerne la manière, vous savez déjà que tout va passer par la méthode doFilter() du filtre en question…
- Le téléchargement de fichiers peut être géré simplement via une servlet dédiée, chargée de faire la correspondance entre le pattern d'URL choisi côté public et l'emplacement du fichier physique côté serveur.
- Elle se charge de transmettre les données lues sur le serveur au navigateur du client via la réponse HTTP.
- Pour permettre un tel transfert, il faut réinitialiser une réponse HTTP, puis définir ses en-têtes Content-Type, Content-Length et Content-Disposition.
- Pour envoyer les données au client, il suffit de lire le fichier comme n'importe quel fichier local et de recopier son contenu dans le flux de sortie accessible via la méthode
response.getOutputStream().