Les cartes graphiques normales ne peuvent pas toujours éliminer les pixels cachés par des zones opaques de manière précoce. Si la détection des pixels masqués s'effectue dans les ROP, de nombreux pixels inutiles seront calculés par les pixels shaders, coloriés, éclairés, et j'en passe. Or, la profondeur d'un pixel est connue dès la fin de l'étape de rasterisation. On peut ainsi déterminer plus ou moins facilement si un fragment sera ou non calculé.
On peut penser que comparer les valeurs de profondeur en sortie du rasterizer serait une bonne chose. Mais cela ne marcherait pas aussi bien que prévu. Sur les cartes graphiques normales, l'ordre de soumission des triangles est relativement aléatoire : un objet peut en cacher un autre sans que ces deux objets soient rendus consécutivement.
Sur les cartes graphiques normales, on est obligé d'utiliser un Z-Buffer pour toute l'image : effectuer un test de profondeur précoce ne fonctionne que si les objets soumis à la carte graphique sont triés par leur valeur de profondeur, ce qui n'est jamais le cas. Il faudrait donc trier ces objets pour obtenir un résultat correct, et obtenir le rendu souhaité. Effectuer le tri des objets avant d'effectuer un test de profondeur serait nettement plus lent que d'effectuer le test de profondeur après l'application des textures et shaders.
Mais il existe des solutions alternatives. On peut adapter les cartes graphiques usuelles avec quelques optimisations, ou repenser totalement l'architecture des cartes graphiques. Dans ce chapitre, nous allons voir les deux solutions en détail.
Tiled rendering
Dans ce tutoriel, nous avons abordé les cartes graphiques 3D usuelles. Mais il existe une classe de carte 3D légèrement différente, qui calcule les images à afficher d'une manière relativement différente. Sur ces architectures, l'écran/image à rendre est découpé en rectangles, rendus indépendamment, uns par uns : ces rectangles sont appelés des tiles. C'est pour cela que ces architectures sont nommées des architectures à tiles.
Le principe de ces architectures est de ne rendre que les pixels visible à l'écran, et de ne pas calculer les pixels cachés, situés trop loin, etc. On en déduit donc que l'élimination des pixels et triangles cachés s'effectue dès que la profondeur est disponible, c'est à dire à l'étape de rasterization.
Sur ces architectures, le rendu d'une image s'effectue en plusieurs étapes :
- la géométrie est calculée et le résultat est mémorisé dans une mémoire tampon ou en mémoire vidéo ;
- chaque tile se voit attribuer la liste des triangles qu'elle contient : cette liste est appelée la Display List, et elle est enregistrée en mémoire vidéo ;
- par la suite, il suffit de rasterizer, placer les textures et exécuter les shaders chaque tile, avant d'envoyer le tout aux ROP.
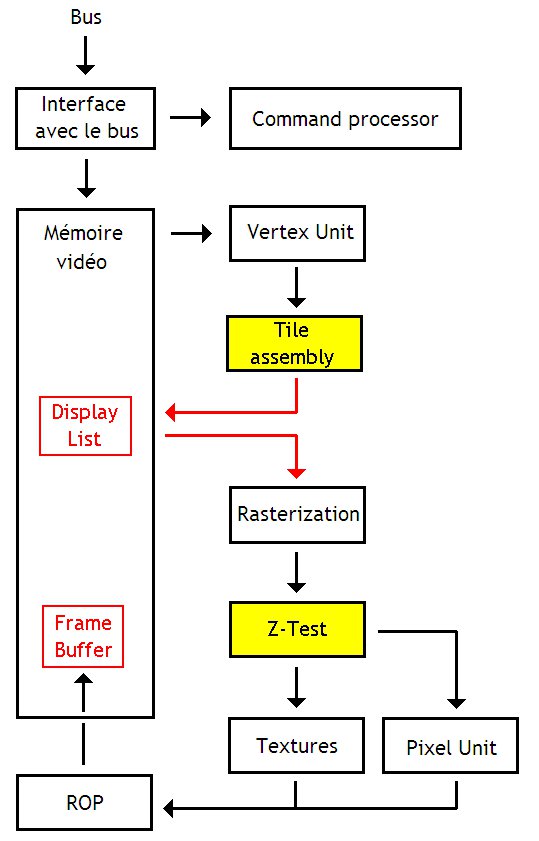
Chaque étape est prise en charge par une unité spécialisée :
- la gestion de la géométrie est réalisée par les unités de vertex, qui ne changent pas ;
- la seconde étape est prise en charge par une nouvelle unité, qui remplace le rasterizer : le Tile Accelerator ;
- l’élimination des pixels cachés est réalisée par une nouvelle unité : l'Image Synthesis Processor, ou ISP ;
- on retrouve les unités de texture et les processeurs de shaders ;
- et l'écriture en mémoire vidéo est effectuée par les ROPs.
Le rasterizer se voit ajouter un nouveau rôle : décider dans quelle tile se trouve un triangle. Pour cela, le rasterizer va calculer le rectangle qui contient un triangle (souvenez-vous le chapitre sur la rasterization), et va vérifier das quelle tile celui-ci est inclus : cela demande de faire quelques comparaison entre les sommets du rectangle, et les sommets des tiles.
L'Image Synthesis Processor remplace en quelque sorte le Z-Buffer et les circuits d'élimination des pixels cachés. Sur une architecture normale, on devrait utiliser un z-buffer pour l'image entière. Une architecture à tile a juste besoin d'un Z-Buffer pour la tile en cours de traitement. De plus, les tiles sont tellement petites que l'on peut stocker tout le Z-Buffer dans une petite mémoire tampon integrée dans l'ISP.
Cette mémoire tampon réduit fortement les besoins en bande passante et en débit mémoire, ce qui rend inutile de nombreuses optimisations. Par exemple, le Z-Buffer n'a pas besoin d'être compressé. Idem pour le color buffer. En fait, une grande partie des accès à la mémoire vidéo disparait purement et simplement (même si une partie est remplacée par l'enregistrement des listes de triangles).
Les ROPs sont modifiés : ils ne gèrent que l'alpha blending et la la gestion de l'antialiasing. La gestion du Z-Buffer n'est plus prise en charge par les ROPs, mais est gérée par l'Image Synthesis Processor.
De plus, une mémoire tampon est généralement ajoutée aux ROP. En effet, les tiles étant relativement petites, on peut placer le résultat final dans une petite mémoire tampon au lieu d'écrire le tout dans la mémoire vidéo directement. Cette mémoire tapon permet d'accumuler le morceau d'image qui correspond à la tile, et de l'écrire d'un seul bloc en mémoire vidéo. Au lieu d'effectuer les écritures pixels par pixel, on peut y aller par blocs, ce qui est bien plus efficace.
Early-Z
Les architectures à base de Tiles ne sont pas la seule solution pour éviter le calcul des pixels cachés. Les concepteurs de cartes graphiques usuelles (sans tiled rendering) ont inventé des moyens pour détecter une partie des pixels qui ne seront pas visibles, avant que ceux-ci n'entrent dans l'unité de texture. Ces techniques sont des techniques d'early-Z.
Avec ces techniques, la carte graphique doit faire en sorte de gérer les situations où les shaders peuvent bidouiller la profondeur ou la transparence d'un pixel. Pour éliminer tout problème, les drivers de la carte graphique doivent analyser les shaders et décider si le test de profondeur précoce peut être effectué ou non. Selon le résultat de l'analyse des shaders, l'Early-Z est activé ou non, afin de garder un résultat correct à l'écran.
En somme, les techniques d'Early-Z sont assez conservatives : elles vont éliminer un pixel quand il est certain que celui-ci n'est pas affiché. Au moindre doute, les techniques d'Early-Z laissent passer le pixel. Utiliser une élimination précoce des pixels n'est donc pas sans dommages, si le test de profondeur n'est pas refait une fois les shaders calculés. Voilà qui est nettement moins performant que l'utilisation d'une Tiled Architecture…
Z-Max et Z-Min
Il existe plusieurs techniques d'early-Z, qui sont présentes depuis belle lurette dans nos cartes graphiques. Celles-ci peuvent être classées en deux catégories : le zmax, et le zmin.
Les deux techniques se basent sur une même idée : l'écran est découpé en tiles. Dans chaque tile, la carte graphique vérifie si chaque pixel est affiché ou masqué. Parmi tous les pixels affichés, il y en aura un dont la profondeur sera plus élevée ou plus petite que les autres. L'unité d'Early-Z mémorise cette profondeur maximale ou minimale. Dans le cas du zmax, c'est la profondeur la plus grande qui est mémorisé, alors que le zmin mémorise la plus petite profondeur.
Z-Max
Le Z-max consiste à vérifier si la tile à rendre est situé derrière des tiles déjà rendues : si c'est le cas, la tile est masquée et on ne la calcule pas. Pour cela, il suffit de savoir quelle est la tile la plus profonde déjà rendue. Pour optimiser le tout, il suffit de conserver la profondeur de cette tile, et de faire les vérifications de profondeur.
Le zmax consiste donc à vérifier si le triangle à rendre est situé derrière le pixel le plus profond de la tile. Si c'est le cas, cela signifie que le triangle est masqué. Pour aller plus vite et pour éviter tout problème, cette vérification se fait en utilisant le pixel du triangle le plus proche (plus précisément, sa profondeur). Si cette profondeur du sommet le plus proche est supérieure à la profondeur maximale de la tile, le triangle est masqué et n'est donc pas calculé.
Ces techniques ont un gros défaut : il faut calculer la valeur maximale des pixels de la tile. Et pour cela, il n'y a qu'une seule solution : lire toutes les profondeur de la tile, et calculer la maximum. Ce genre de chose s'effectue dans les ROPs, et demande parfois de lire les profondeurs depuis la mémoire vidéo…
La première technique de Z-Max est celle du Hierarchical Z. Dans les grandes lignes, cette technique consiste à conserver une copie basse-résolution du tampon de profondeur. Cette copie basse-résolution mémorise simplement la valeur maximale de la profondeur pour chaque tile. Cette copie basse-résolution est mise à jour par les ROPs, en même temps que le Z-Buffer. La copie basse-résolution peut tenir dans une mémoire cache de la carte graphique, ou dans la mémoire vidéo, mais sa mise à jour demande que les ROPs déterminent la profondeur maximale d'une tile : cela bouffe du circuit !
Il existe d'autres techniques qui permettent d'éliminer ce genre de problèmes, comme le Depth Filter ou le Mid-texturing.
Z-Min
Avec le zmin, on utilise la profondeur maximale des sommets du triangle dans les calculs. Cette valeur est comparée avec la valeur de profondeur minimale dans la tile. Si la profondeur du pixel à rendre est plus petite, cela veut dire que le pixel n'est pas caché et qu'il n'y a pas besoin d'effectuer de test de profondeur dans les ROPs.
Le calcul de la profondeur minimale de la tile est très simple : il suffit de mémoriser la plus petite valeur rencontrée et la mettre à jour à chaque rendu de pixel. Par besoin de lire toutes les profondeurs de la tile d'un seul coup, ou quoique ce soit d'autre, comme avec le zmax.
Cette méthode est particulièrement adaptée aux rendus dans lesquels les recouvrements de triangles sont relativement rares. Il faut dire que cette méthode ne rejette pas beaucoup de pixels comparé à la technique du zmax. En contrepartie, elle n'utilise pas beaucoup de circuits comparé au zmax : c'est pour cela qu'elle est surtout utilisée dans les cartes graphiques pour mobiles.
Hybrides
Il est parfaitement possible d'utiliser le zmax conjointement avec le zmin. On obtient alors des techniques hybrides, relativement puissantes. On pourrait citer l'exemple de l'adaptive tile depth filter.