Un index est une structure qui reprend la liste ordonnée des valeurs auxquelles il se rapporte. Les index sont utilisés pour accélérer les requêtes (notamment les requêtes impliquant plusieurs tables, ou les requêtes de recherche), et sont indispensables à la création de clés, étrangères et primaires, qui permettent de garantir l'intégrité des données de la base et dont nous discuterons au chapitre suivant.
Au programme de ce chapitre :
- Qu'est-ce qu'un index et comment est-il représenté ?
- En quoi un index peut-il accélérer une requête ?
- Quels sont les différents types d'index ?
- Comment créer (et supprimer) un index ?
- Qu'est-ce que la recherche
FULLTEXTet comment fonctionne-t-elle ?
Etat actuelle de la base de données
Note : les tables de test ne sont pas reprises
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | SET NAMES utf8; DROP TABLE IF EXISTS Animal; CREATE TABLE Animal ( id smallint(6) UNSIGNED NOT NULL AUTO_INCREMENT, espece varchar(40) NOT NULL, sexe char(1) DEFAULT NULL, date_naissance datetime NOT NULL, nom varchar(30) DEFAULT NULL, commentaires text, PRIMARY KEY (id) ) ENGINE=InnoDB AUTO_INCREMENT=61 DEFAULT CHARSET=utf8; LOCK TABLES Animal WRITE; INSERT INTO Animal VALUES (1,'chien','M','2010-04-05 13:43:00','Rox','Mordille beaucoup'),(2,'chat',NULL,'2010-03-24 02:23:00','Roucky',NULL),(3,'chat','F','2010-09-13 15:02:00','Schtroumpfette',NULL), (4,'tortue','F','2009-08-03 05:12:00',NULL,NULL),(5,'chat',NULL,'2010-10-03 16:44:00','Choupi','Né sans oreille gauche'),(6,'tortue','F','2009-06-13 08:17:00','Bobosse','Carapace bizarre'), (7,'chien','F','2008-12-06 05:18:00','Caroline',NULL),(8,'chat','M','2008-09-11 15:38:00','Bagherra',NULL),(9,'tortue',NULL,'2010-08-23 05:18:00',NULL,NULL), (10,'chien','M','2010-07-21 15:41:00','Bobo',NULL),(11,'chien','F','2008-02-20 15:45:00','Canaille',NULL),(12,'chien','F','2009-05-26 08:54:00','Cali',NULL), (13,'chien','F','2007-04-24 12:54:00','Rouquine',NULL),(14,'chien','F','2009-05-26 08:56:00','Fila',NULL),(15,'chien','F','2008-02-20 15:47:00','Anya',NULL), (16,'chien','F','2009-05-26 08:50:00','Louya',NULL),(17,'chien','F','2008-03-10 13:45:00','Welva',NULL),(18,'chien','F','2007-04-24 12:59:00','Zira',NULL), (19,'chien','F','2009-05-26 09:02:00','Java',NULL),(20,'chien','M','2007-04-24 12:45:00','Balou',NULL),(21,'chien','F','2008-03-10 13:43:00','Pataude',NULL), (22,'chien','M','2007-04-24 12:42:00','Bouli',NULL),(24,'chien','M','2007-04-12 05:23:00','Cartouche',NULL),(25,'chien','M','2006-05-14 15:50:00','Zambo',NULL), (26,'chien','M','2006-05-14 15:48:00','Samba',NULL),(27,'chien','M','2008-03-10 13:40:00','Moka',NULL),(28,'chien','M','2006-05-14 15:40:00','Pilou',NULL), (29,'chat','M','2009-05-14 06:30:00','Fiero',NULL),(30,'chat','M','2007-03-12 12:05:00','Zonko',NULL),(31,'chat','M','2008-02-20 15:45:00','Filou',NULL), (32,'chat','M','2007-03-12 12:07:00','Farceur',NULL),(33,'chat','M','2006-05-19 16:17:00','Caribou',NULL),(34,'chat','M','2008-04-20 03:22:00','Capou',NULL), (35,'chat','M','2006-05-19 16:56:00','Raccou','Pas de queue depuis la naissance'),(36,'chat','M','2009-05-14 06:42:00','Boucan',NULL),(37,'chat','F','2006-05-19 16:06:00','Callune',NULL), (38,'chat','F','2009-05-14 06:45:00','Boule',NULL),(39,'chat','F','2008-04-20 03:26:00','Zara',NULL),(40,'chat','F','2007-03-12 12:00:00','Milla',NULL), (41,'chat','F','2006-05-19 15:59:00','Feta',NULL),(42,'chat','F','2008-04-20 03:20:00','Bilba','Sourde de l''oreille droite à 80%'),(43,'chat','F','2007-03-12 11:54:00','Cracotte',NULL), (44,'chat','F','2006-05-19 16:16:00','Cawette',NULL),(45,'tortue','F','2007-04-01 18:17:00','Nikki',NULL),(46,'tortue','F','2009-03-24 08:23:00','Tortilla',NULL), (47,'tortue','F','2009-03-26 01:24:00','Scroupy',NULL),(48,'tortue','F','2006-03-15 14:56:00','Lulla',NULL),(49,'tortue','F','2008-03-15 12:02:00','Dana',NULL), (50,'tortue','F','2009-05-25 19:57:00','Cheli',NULL),(51,'tortue','F','2007-04-01 03:54:00','Chicaca',NULL),(52,'tortue','F','2006-03-15 14:26:00','Redbul','Insomniaque'), (53,'tortue','M','2007-04-02 01:45:00','Spoutnik',NULL),(54,'tortue','M','2008-03-16 08:20:00','Bubulle',NULL),(55,'tortue','M','2008-03-15 18:45:00','Relou','Surpoids'), (56,'tortue','M','2009-05-25 18:54:00','Bulbizard',NULL),(57,'perroquet','M','2007-03-04 19:36:00','Safran',NULL),(58,'perroquet','M','2008-02-20 02:50:00','Gingko',NULL), (59,'perroquet','M','2009-03-26 08:28:00','Bavard',NULL),(60,'perroquet','F','2009-03-26 07:55:00','Parlotte',NULL); UNLOCK TABLES; |
- Qu'est-ce qu'un index ?
- Les différents types d'index
- Création et suppression des index
- Recherches avec FULLTEXT
Qu'est-ce qu'un index ?
Revoyons la définition d'un index.
Structure de données qui reprend la liste ordonnée des valeurs auxquelles il se rapporte.
Définition
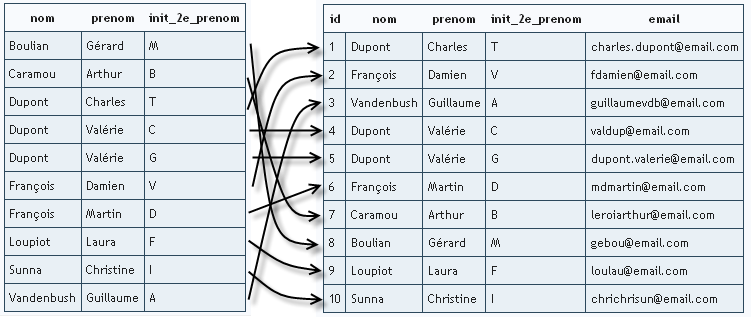
Lorsque vous créez un index sur une table, MySQL stocke cet index sous forme d'une structure particulière, contenant les valeurs des colonnes impliquées dans l'index. Cette structure stocke les valeurs triées et permet d'accéder à chacune de manière efficace et rapide. Petit schéma explicatif dans le cas d'un index sur l'id de la table Animal (je ne prends que les neuf premières lignes pour ne pas surcharger).
Pour permettre une compréhension plus facile, je représente ici l'index sous forme de table. En réalité, par défaut, MySQL stocke les index dans une structure de type "arbre" (l'index est alors de type BTREE). Le principe est cependant le même.

Les données d'Animal ne sont pas stockées suivant un ordre intelligible pour nous. Par contre, l'index sur l'id est trié simplement par ordre croissant. Cela permet de grandement accélérer toute recherche faite sur cet id.
Imaginons en effet, que nous voulions récupérer toutes les lignes dont l'id est inférieur ou égal à 5. Sans index, MyQSL doit parcourir toutes les lignes une à une. Par contre, grâce à l'index, dès qu'il tombe sur la ligne dont l'id est 6, il sait qu'il peut s'arrêter, puisque toutes les lignes suivantes auront un id supérieur ou égal à 6. Dans cet exemple, on ne gagne que quelques lignes, mais imaginez une table contenant des milliers de lignes. Le gain de temps peut être assez considérable.
Par ailleurs, avec les id triés par ordre croissant, pour rechercher un id particulier, MySQL n'est pas obligé de simplement parcourir les données ligne par ligne. Il peut utiliser des algorithmes de recherche puissants (comme la recherche dichotomique), toujours afin d’accélérer la recherche.
Mais pourquoi ne pas simplement trier la table complète sur la base de la colonne id ? Pourquoi créer et stocker une structure spécialement pour l'index ? Tout simplement parce qu'il peut y avoir plusieurs index sur une même table, et que l'ordre des lignes pour chacun de ces index n'est pas nécessairement le même. Par exemple, nous pouvons créer un second index pour notre table Animal, sur la colonne date_naissance.

Comme vous pouvez le voir, l'ordre n'est pas du tout le même.
Intérêt des index
Vous devriez avoir compris maintenant que tout l'intérêt des index est d'accélérer les requêtes qui utilisent des colonnes indexées comme critères de recherche. Par conséquent, si vous savez que dans votre application, vous ferez énormément de recherches sur la colonne X, ajoutez donc un index sur cette colonne, vous ne vous en porterez que mieux.
Les index permettent aussi d'assurer l'intégrité des données de la base. Pour cela, il existe en fait plusieurs types d'index différents, et deux types de "clés". Lorsque je parle de garantir l'intégrité de vos données, cela signifie en gros garantir la qualité de vos données, vous assurer que vos données ont du sens. Par exemple, soyez sûrs que vous ne faites pas référence à un client dans la table Commande, alors qu'en réalité, ce client n'existe absolument pas dans la table Client.
Désavantages
Si tout ce que fait un index, c'est accélérer les requêtes utilisant des critères de recherche correspondants, autant en mettre partout, et en profiter à chaque requête ! Sauf qu'évidemment, ce n'est pas si simple, les index ont deux inconvénients.
- Ils prennent de la place en mémoire
- Ils ralentissent les requêtes d'insertion, modification et suppression, puisqu'à chaque fois, il faut remettre l'index à jour en plus de la table.
Par conséquent, n'ajoutez pas d'index lorsque ce n'est pas vraiment utile.
Index sur plusieurs colonnes
Reprenons l'exemple d'une table appelée Client, qui reprend les informations des clients d'une société. Elle se présente comme suit :
|
id |
nom |
prenom |
init_2e_prenom |
|
|---|---|---|---|---|
|
1 |
Dupont |
Charles |
T |
|
|
2 |
François |
Damien |
V |
|
|
3 |
Vandenbush |
Guillaume |
A |
|
|
4 |
Dupont |
Valérie |
C |
|
|
5 |
Dupont |
Valérie |
G |
|
|
6 |
François |
Martin |
D |
|
|
7 |
Caramou |
Arthur |
B |
|
|
8 |
Boulian |
Gérard |
M |
|
|
9 |
Loupiot |
Laura |
F |
|
|
10 |
Sunna |
Christine |
I |
Vous avez bien sûr un index sur la colonne id, mais vous constatez que vous faites énormément de recherches par nom, prénom et initiale du second prénom. Vous pourriez donc faire trois index, un pour chacune de ces colonnes. Mais, si vous faites souvent des recherches sur les trois colonnes à la fois, il vaut encore mieux faire un seul index, sur les trois colonnes (nom, prenom, init_2e_prenom). L'index contiendra donc les valeurs des trois colonnes et sera trié par nom, ensuite par prénom, et enfin par initiale (l'ordre des colonnes a donc de l'importance !).
Du coup, lorsque vous cherchez "Dupont Valérie C.", grâce à l'index MySQL trouvera rapidement tous les "Dupont", parmi lesquels il trouvera toutes les "Valérie" (toujours en se servant du même index), parmi lesquelles il trouvera celle (ou celles) dont le second prénom commence par "C".
Tirer parti des "index par la gauche"
Tout ça c'est bien beau si on fait souvent des recherches à la fois sur le nom, le prénom et l'initiale. Mais comment fait-on si l'on fait aussi souvent des recherches uniquement sur le nom, ou uniquement sur le prénom, ou sur le nom et le prénom en même temps mais sans l'initiale ? Faut-il créer un nouvel index pour chaque type de recherche ?
Hé bien non ! MySQl est beaucoup trop fort : il est capable de tirer parti de votre index sur (nom, prenom, init_2e_prenom) pour certaines autres recherches. En effet, si l'on représente les index sous forme de tables, voici ce que cela donnerait pour les quatre index (prenom), (nom), (nom, prenom) et (nom, prenom, init_2e_prenom).
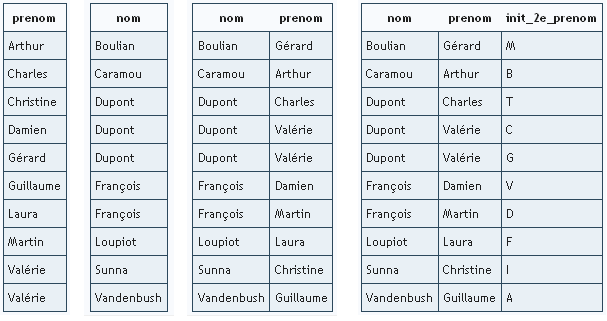
Remarquez-vous quelque chose d'intéressant ?
Oui ! Bien vu ! L'index (nom, prenom) correspond exactement aux deux premières colonnes de l'index (nom, prenom, init_2e_prenom) ; pas seulement au niveau des valeurs mais surtout au niveau de l'ordre. Et l'index (nom) correspond à la première colonne de l'index (nom, prenom, init_2e_prenom).
Or, je vous ai dit que lorsque vous faites une recherche sur le nom, le prénom et l'initiale avec l'index (nom, prenom, init_2e_prenom), MySQL regarde d'abord le nom, puis le prénom, et pour finir l'initiale. Donc, si vous ne faites une recherche que sur le nom et le prénom, MySQL va intelligemment utiliser l'index (nom, prenom, init_2e_prenom) : il va simplement laisser tomber l'étape de l'initiale du second prénom. Idem si vous faites une recherche sur le nom : MySQL se basera uniquement sur la première colonne de l'index existant.
Par conséquent, pas besoin de définir un index (nom, prenom) ou un index (nom). Ils sont en quelque sorte déjà présents.
Mais qu'en est-il des index (prenom), ou (prenom, init_2e_prenom) ? Vous pouvez voir que la table contenant l'index (prenom) ne correspond à aucune colonne d'un index existant (au niveau de l'ordre des lignes). Par conséquent, si vous voulez un index sur (prenom), il vous faut le créer. Même chose pour (prenom, init_2e_prenom) ou (nom, init_2e_prenom).
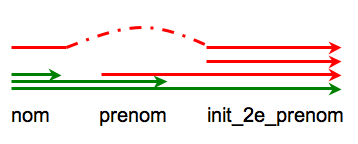
On parle d'index "par la gauche". Donc si l'on prend des sous-parties d'index existant en prenant des colonnes "par la gauche", ces index existent. Mais si l'on commence par la droite ou que l'on "saute" une colonne, ils n'existent pas et doivent éventuellement être créés.
Index sur des colonnes de type alphanumérique
Types CHAR et VARCHAR
Lorsque l'on indexe une colonne de type VARCHAR ou CHAR (comme la colonne nom de la table Client par exemple), on peut décomposer l'index de la manière suivante :
|
1e lettre |
2e lettre |
3e lettre |
4e lettre |
5e lettre |
6e lettre |
7e lettre |
8e lettre |
9e lettre |
10e lettre |
|---|---|---|---|---|---|---|---|---|---|
|
B |
o |
u |
l |
i |
a |
n |
|||
|
C |
a |
r |
a |
m |
o |
u |
|||
|
D |
u |
p |
o |
n |
t |
||||
|
D |
u |
p |
o |
n |
t |
||||
|
D |
u |
p |
o |
n |
t |
||||
|
F |
r |
a |
n |
ç |
o |
i |
s |
||
|
F |
r |
a |
n |
ç |
o |
i |
s |
||
|
L |
o |
u |
p |
i |
o |
t |
|||
|
S |
u |
n |
n |
a |
|||||
|
V |
a |
n |
d |
e |
n |
b |
u |
s |
h |
|
nom |
|---|
|
Boulian |
|
Caramou |
|
Dupont |
|
Dupont |
|
Dupont |
|
François |
|
François |
|
Loupiot |
|
Sunna |
|
Vandenbush |
En quoi cela nous intéresse-t-il ?
C'est très simple. Ici, nous n'avons que des noms assez courts. La colonne nom peut par exemple être de type VARCHAR(30). Mais imaginez une colonne de type VARCHAR(150), qui contient des titres de livres par exemple. Si l'on met un index dessus, MySQL va indexer jusqu'à 150 caractères. Or, il est fort probable que les 25-30 premiers caractères du titre suffisent à trier ceux-ci. Au pire, un ou deux ne seront pas exactement à la bonne place, mais les requêtes en seraient déjà grandement accélérées.
Il serait donc plutôt pratique de dire à MySQL : "Indexe cette colonne, mais base-toi seulement sur les x premiers caractères". Et c'est possible évidemment (sinon je ne vous en parlerais pas  ), et c'est même très simple. Lorsque l'on créera l'index sur la colonne titre_livre, il suffira d'indiquer un nombre entre parenthèses : titre_livre(25) par exemple. Ce nombre étant bien sûr le nombre de caractères (dans le sens de la lecture, donc à partir de la gauche) à prendre en compte pour l'index.
), et c'est même très simple. Lorsque l'on créera l'index sur la colonne titre_livre, il suffira d'indiquer un nombre entre parenthèses : titre_livre(25) par exemple. Ce nombre étant bien sûr le nombre de caractères (dans le sens de la lecture, donc à partir de la gauche) à prendre en compte pour l'index.
Le fait d'utiliser ces index partiels sur des champs alphanumériques permet de gagner de la place (un index sur 150 lettres prend évidemment plus de place qu'un index sur 20 lettres), et si la longueur est intelligemment définie, l'accélération permise par l'index sera la même que si l'on avait pris la colonne entière.
Types BLOB et TEXT (et dérivés)
Si vous mettez un index sur une colonne de type BLOB ou TEXT (ou un de leurs dérivés), MySQL exige que vous précisiez un nombre de caractères à prendre en compte. Et heureusement… Vu la longueur potentielle de ce que l'on stocke dans de telles colonnes.
Les différents types d'index
En plus des index "simples", que je viens de vous décrire, il existe trois types d'index qui ont des propriétés particulières. Les index UNIQUE, les index FULLTEXT, et enfin les index SPATIAL.
Je ne détaillerai pas les propriétés et utilisations des index SPATIAL. Sachez simplement qu'il s'agit d'un type d'index utilisé dans des bases de données recensant des données spatiales (tiens donc ! ), donc des points, des lignes, des polygones…
Sur ce, c'est parti !
Index UNIQUE
Avoir un index UNIQUE sur une colonne (ou plusieurs) permet de s'assurer que jamais vous n’insérerez deux fois la même valeur (ou combinaison de valeurs) dans la table.
Par exemple, vous créez un site internet, et vous voulez le doter d'un espace membre. Chaque membre devra se connecter grâce à un pseudo et un mot de passe. Vous avez donc une table Membre, qui contient 4 colonnes : id, pseudo, mot_de_passe et date_inscription.
Deux membres peuvent avoir le même mot de passe, pas de problème. Par contre, que se passerait-il si deux membres avaient le même pseudo ? Lors de la connexion, il serait impossible de savoir quel mot de passe utiliser et sur quel compte connecter le membre.
Il faut donc absolument éviter que deux membres utilisent le même pseudo. Pour cela, on va utiliser un index UNIQUE sur la colonne pseudo de la table Membre.
Autre exemple, dans notre table Animal cette fois. Histoire de ne pas confondre les animaux, vous prenez la décision de ne pas nommer de la même manière deux animaux de la même espèce. Il peut donc n'y avoir qu'une seule tortue nommée Toto. Un chien peut aussi se nommer Toto, mais un seul. La combinaison (espèce, nom) doit n'exister qu'une et une seule fois dans la table. Pour s'en assurer, il suffit de créer un index unique sur les colonnes espece et nom (un seul index, sur les deux colonnes).
Contraintes
Lorsque vous mettez un index UNIQUE sur une table, vous ne mettez pas seulement un index, vous ajoutez surtout une contrainte.
Les contraintes sont une notion importante en SQL. Sans le savoir, ou sans savoir que c'était appelé comme ça, vous en avez déjà utilisé. En effet, lorsque vous empêchez une colonne d'accepter NULL, vous lui mettez une contrainte NOT NULL.
De même, les valeurs par défaut que vous pouvez donner aux colonnes sont des contraintes. Vous contraignez la colonne à prendre une certaine valeur si aucune autre n'est précisée.
Index FULLTEXT
Un index FULLTEXT est utilisé pour faire des recherches de manière puissante et rapide sur un texte. Seules les tables utilisant le moteur de stockage MyISAM peuvent avoir un index FULLTEXT, et cela uniquement sur les colonnes de type CHAR, VARCHAR ou TEXT (ce qui est plutôt logique).
Une différence importante (très importante !!!  ) entre les index
) entre les index FULLTEXT et les index classiques (et UNIQUE) est que l'on ne peut plus utiliser les fameux "index par la gauche" dont je vous ai parlé précédemment. Donc, si vous voulez faire des recherches "fulltext" sur deux colonnes (parfois l'une, parfois l'autre, parfois les deux ensemble), il vous faudra créer trois index FULLTEXT : (colonne1), (colonne2) et (colonne1, colonne2).
Création et suppression des index
Les index sont représentés par le mot-clé INDEX (surprise !  ) ou
) ou KEY et peuvent être créés de deux manières :
- soit directement lors de la création de la table ;
- soit en les ajoutant par la suite.
Ajout des index lors de la création de la table
Ici aussi, deux possibilités : vous pouvez préciser dans la description de la colonne qu'il s'agit d'un index, ou lister les index par la suite.
Index dans la description de la colonne
Seuls les index "classiques" et uniques peuvent être créés de cette manière.
Je rappelle que la description de la colonne se rapporte à l'endroit où vous indiquez le type de données, si la colonne peut contenir NULL, etc. Il est donc possible, à ce même endroit, de préciser si la colonne est un index.
1 2 3 4 | CREATE TABLE nom_table ( colonne1 INT KEY, -- Crée un index simple sur colonne1 colonne2 VARCHAR(40) UNIQUE, -- Crée un index unique sur colonne2 ); |
Quelques petites remarques ici :
- Avec cette syntaxe, seul le mot
KEYpeut être utilisé pour définir un index simple. Ailleurs, vous pourrez utiliserKEYouINDEX. - Pour définir un index
UNIQUEde cette manière, on n'utilise que le mot-cléUNIQUE, sans le faire précéder deINDEXou deKEY(comme ce sera le cas avec d'autres syntaxes). - Il n'est pas possible de définir des index composites (sur plusieurs colonnes) de cette manière.
- Il n'est pas non plus possible de créer un index sur une partie de la colonne (les x premiers caractères).
Liste d'index
L'autre possibilité est d'ajouter les index à la suite des colonnes, en séparant chaque élément par une virgule :
1 2 3 4 5 6 7 8 9 | CREATE TABLE nom_table ( colonne1 description_colonne1, [colonne2 description_colonne2, colonne3 description_colonne3, ...,] [PRIMARY KEY (colonne_clé_primaire)], [INDEX [nom_index] (colonne1_index [, colonne2_index, ...]] ) [ENGINE=moteur]; |
Exemple : si l'on avait voulu créer la table Animal avec un index sur la date de naissance, et un autre sur les 10 premières lettres du nom, on aurait pu utiliser la commande suivante :
1 2 3 4 5 6 7 8 9 10 11 12 | CREATE TABLE Animal ( id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT, espece VARCHAR(40) NOT NULL, sexe CHAR(1), date_naissance DATETIME NOT NULL, nom VARCHAR(30), commentaires TEXT, PRIMARY KEY (id), INDEX ind_date_naissance (date_naissance), -- index sur la date de naissance INDEX ind_nom (nom(10)) -- index sur le nom (le chiffre entre parenthèses étant le nombre de caractères pris en compte) ) ENGINE=INNODB; |
Vous n'êtes pas obligés de préciser un nom pour votre index. Si vous ne le faites pas, MySQL en créera un automatiquement pour vous. Je préfère nommer mes index moi-même plutôt que de laisser MySQL créer un nom par défaut, et respecter certaines conventions personnelles. Ainsi, mes index auront toujours le préfixe "ind" suivi du ou des nom(s) des colonnes concernées, le tout séparé par des "_". Il vous appartient de suivre vos propres conventions bien sûr. L'important étant de vous y retrouver.
Et pour ajouter des index UNIQUE ou FULLTEXT, c'est le même principe :
1 2 3 4 5 6 7 8 | CREATE TABLE nom_table ( colonne1 INT NOT NULL, colonne2 VARCHAR(40), colonne3 TEXT, UNIQUE [INDEX] ind_uni_col2 (colonne2), -- Crée un index UNIQUE sur la colonne2, INDEX est facultatif FULLTEXT [INDEX] ind_full_col3 (colonne3) -- Crée un index FULLTEXT sur la colonne3, INDEX est facultatif ) ENGINE=MyISAM; |
Exemple : création de la table Animal comme précédemment, en ajoutant un index UNIQUE sur (nom, espece).
1 2 3 4 5 6 7 8 9 10 11 12 13 | CREATE TABLE Animal ( id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT, espece VARCHAR(40) NOT NULL, sexe CHAR(1), date_naissance DATETIME NOT NULL, nom VARCHAR(30), commentaires TEXT, PRIMARY KEY (id), INDEX ind_date_naissance (date_naissance), INDEX ind_nom (nom(10)), UNIQUE INDEX ind_uni_nom_espece (nom, espece) -- Index sur le nom et l'espece ) ENGINE=INNODB; |
Avec cette syntaxe, KEY ne peut être utilisé que pour les index simples et INDEX pour tous les types d'index. Bon, je sais que c'est assez pénible à retenir, mais en gros, utilisez INDEX partout, sauf pour définir un index dans la description même de la colonne, et vous n'aurez pas de problème.
Ajout des index après création de la table
En dehors du fait que parfois vous ne penserez pas à tout au moment de la création de votre table, il peut parfois être intéressant de créer les index après la table.
En effet, je vous ai dit que l'ajout d'index sur une table ralentissait l'exécution des requêtes d'écriture (insertion, suppression, modification de données). Par conséquent, si vous créez une table, que vous comptez remplir avec un grand nombre de données immédiatement, grâce à la commande LOAD DATA INFILE par exemple, il vaut bien mieux créer la table, la remplir, et ensuite seulement créer les index voulus sur cette table.
Il existe deux commandes permettant de créer des index sur une table existante : ALTER TABLE, que vous connaissez déjà un peu, et CREATE INDEX. Ces deux commandes sont équivalentes, utilisez celle qui vous parle le plus.
Ajout avec ALTER TABLE
1 2 3 4 5 6 7 8 | ALTER TABLE nom_table ADD INDEX [nom_index] (colonne_index [, colonne2_index ...]); --Ajout d'un index simple ALTER TABLE nom_table ADD UNIQUE [nom_index] (colonne_index [, colonne2_index ...]); --Ajout d'un index UNIQUE ALTER TABLE nom_table ADD FULLTEXT [nom_index] (colonne_index [, colonne2_index ...]); --Ajout d'un index FULLTEXT |
Contrairement à ce qui se passait pour l'ajout d'une colonne, il est ici obligatoire de préciser INDEX (ou UNIQUE, ou FULLTEXT) après ADD.
Dans le cas d'un index multi-colonnes, il suffit comme d'habitude de toutes les indiquer entre parenthèses, séparées par des virgules.
Reprenons la table Test_tuto, utilisée pour tester ALTER TABLE, et ajoutons-lui un index sur la colonne nom :
1 2 | ALTER TABLE Test_tuto ADD INDEX ind_nom (nom); |
Si vous affichez maintenant la description de votre table Test_tuto, vous verrez que dans la colonne "Key", il est indiqué MUL pour la colonne nom. L'index a donc bien été créé.
Ajout avec CREATE INDEX
La syntaxe de CREATE INDEX est très simple :
1 2 3 4 5 6 7 8 9 | CREATE INDEX nom_index ON nom_table (colonne_index [, colonne2_index ...]); -- Crée un index simple CREATE UNIQUE INDEX nom_index ON nom_table (colonne_index [, colonne2_index ...]); -- Crée un index UNIQUE CREATE FULLTEXT INDEX nom_index ON nom_table (colonne_index [, colonne2_index ...]); -- Crée un index FULLTEXT |
Exemple : l'équivalent de la commande ALTER TABLE que nous avons utilisée pour ajouter un index sur la colonne nom est donc :
1 2 | CREATE INDEX ind_nom ON Test_tuto (nom); |
Complément pour la création d'un index UNIQUE - le cas des contraintes
Vous vous rappelez, j'espère, que les index UNIQUE sont ce qu'on appelle des contraintes.
Or, lorsque vous créez un index UNIQUE, vous pouvez explicitement créer une contrainte. C'est fait automatiquement bien sûr si vous ne le faites pas, mais ne soyez donc pas surpris de voir apparaître le mot CONSTRAINT, c'est à ça qu'il se réfère.
Pour pouvoir créer explicitement une contrainte lors de la création d'un index UNIQUE, vous devez créer cet index soit lors de la création de la table, en listant l'index (et la contrainte) à la suite des colonnes, soit après la création de la table, avec la commande ALTER TABLE.
1 2 3 4 5 6 7 8 9 | CREATE TABLE nom_table ( colonne1 INT NOT NULL, colonne2 VARCHAR(40), colonne3 TEXT, CONSTRAINT [symbole_contrainte] UNIQUE [INDEX] ind_uni_col2 (colonne2) ); ALTER TABLE nom_table ADD CONSTRAINT [symbole_contrainte] UNIQUE ind_uni_col2 (colonne2); |
Il n'est pas obligatoire de donner un symbole (un nom en fait) à la contrainte. D'autant plus que dans le cas des index, vous pouvez donner un nom à l'index (ici : ind_uni_col).
Suppression d'un index
Rien de bien compliqué :
1 2 | ALTER TABLE nom_table DROP INDEX nom_index; |
Notez qu'il n'existe pas de commande permettant de modifier un index. Le cas échéant, il vous faudra supprimer, puis recréer votre index avec vos modifications.
Recherches avec FULLTEXT
Nous allons maintenant voir comment utiliser la recherche FULLTEXT, qui est un outil très puissant, et qui peut se révéler très utile.
Quelques rappels d'abord :
- un index
FULLTEXTne peut être défini que pour une table utilisant le moteurMyISAM; - un index
FULLTEXTne peut être défini que sur une colonne de typeCHAR,VARCHARouTEXT - les index "par la gauche" ne sont pas pris en compte par les index
FULLTEXT
Ça, c'est fait ! Nous allons maintenant passer à la recherche proprement dite, mais avant, je vais vous demander d'exécuter les instructions SQL suivantes, qui servent à créer la table que nous utiliserons pour illustrer ce chapitre. Nous sortons ici du contexte de l'élevage d'animaux. En effet, toutes les tables que nous créerons pour l'élevage utiliseront le moteur de stockage InnoDB.
Pour illustrer la recherche FULLTEXT, je vous propose de créer la table Livre, contenant les colonnes id (clé primaire), titre et auteur. Les recherches se feront sur les colonnes auteur et titre, séparément ou ensemble. Il faut donc créer trois index FULLTEXT : (auteur), (titre) et (auteur, titre).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | CREATE TABLE Livre ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, auteur VARCHAR(50), titre VARCHAR(200) ) ENGINE = MyISAM; INSERT INTO Livre (auteur, titre) VALUES ('Daniel Pennac', 'Au bonheur des ogres'), ('Daniel Pennac', 'La Fée Carabine'), ('Daniel Pennac', 'Comme un roman'), ('Daniel Pennac', 'La Petite marchande de prose'), ('Jacqueline Harpman', 'Le Bonheur est dans le crime'), ('Jacqueline Harpman', 'La Dormition des amants'), ('Jacqueline Harpman', 'La Plage d''Ostende'), ('Jacqueline Harpman', 'Histoire de Jenny'), ('Terry Pratchett', 'Les Petits Dieux'), ('Terry Pratchett', 'Le Cinquième éléphant'), ('Terry Pratchett', 'La Vérité'), ('Terry Pratchett', 'Le Dernier héros'), ('Terry Goodkind', 'Le Temple des vents'), ('Jules Verne', 'De la Terre à la Lune'), ('Jules Verne', 'Voyage au centre de la Terre'), ('Henri-Pierre Roché', 'Jules et Jim'); CREATE FULLTEXT INDEX ind_full_titre ON Livre (titre); CREATE FULLTEXT INDEX ind_full_aut ON Livre (auteur); CREATE FULLTEXT INDEX ind_full_titre_aut ON Livre (titre, auteur); |
Comment fonctionne la recherche FULLTEXT ?
Lorsque vous faites une recherche FULLTEXT sur une chaîne de caractères, cette chaîne est découpée en mots. Est considéré comme un mot : toute suite de caractères composée de lettres, chiffres, tirets bas _ et apostrophes '. Par conséquent, un mot composé, comme "porte-clés" par exemple, sera considéré comme deux mots : "porte" et "clés".
Chacun de ces mots sera ensuite comparé avec les valeurs des colonnes sur lesquelles se fait la recherche. Si la colonne contient un des mots recherchés, on considère alors qu'elle correspond à la recherche.
Lorsque MySQL compare la chaîne de caractères que vous lui avez donnée, et les valeurs dans votre table, il ne tient pas compte de tous les mots qu'il rencontre. Les règles sont les suivantes :
- les mots rencontrés dans au moins la moitié des lignes sont ignorés (règle des 50 %) ;
- les mots trop courts (moins de quatre lettres) sont ignorés ;
- et les mots trop communs (en anglais, about, after, once, under, the…) ne sont également pas pris en compte.
Par conséquent, si vous voulez faire des recherches sur une table, il est nécessaire que cette table comporte au moins trois lignes, sinon chacun des mots sera présent dans au moins la moitié des lignes et aucun ne sera pris en compte.
Il est possible de redéfinir la longueur minimale des mots pris en compte, ainsi que la liste des mots trop communs. Je n'entrerai pas dans ces détails ici, vous trouverez ces informations dans la documentation officielle.
Les types de recherche
Il existe trois types de recherche FULLTEXT : la recherche naturelle, la recherche avec booléen, et enfin la recherche avec extension de requête.
Recherche naturelle
Lorsque l'on fait une recherche naturelle, il suffit qu'un seul mot de la chaîne de caractères recherchée se retrouve dans une ligne pour que celle-ci apparaisse dans les résultats. Attention cependant au fait que le mot exact doit se retrouver dans la valeur des colonnes de l'index FULLTEXT examiné.
Voici la syntaxe utilisée pour faire une recherche FULLTEXT :
1 2 3 4 | SELECT * -- Vous mettez évidemment les colonnes que vous voulez. FROM nom_table WHERE MATCH(colonne1[, colonne2, ...]) -- La (ou les) colonne(s) dans laquelle (ou lesquelles) on veut faire la recherche (index FULLTEXT correspondant nécessaire). AGAINST ('chaîne recherchée'); -- La chaîne de caractères recherchée, entre guillemets bien sûr. |
Si l'on veut préciser qu'on fait une recherche naturelle, on peut ajouter IN NATURAL LANGUAGE MODE. Ce n'est cependant pas obligatoire puisque la recherche naturelle est le mode de recherche par défaut.
1 2 3 4 | SELECT * FROM nom_table WHERE MATCH(colonne1[, colonne2, ...]) AGAINST ('chaîne recherchée' IN NATURAL LANGUAGE MODE); |
Premier exemple : on recherche "Terry" dans la colonne auteur de la table Livre .
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(auteur) AGAINST ('Terry'); |
|
id |
auteur |
titre |
|---|---|---|
|
8 |
Terry Pratchett |
Les Petits Dieux |
|
9 |
Terry Pratchett |
Le Cinquième éléphant |
|
10 |
Terry Pratchett |
La Vérité |
|
11 |
Terry Pratchett |
Le Dernier héros |
|
12 |
Terry Goodkind |
Le Temple des vents |
Deuxième exemple : On recherche d'abord "Petite", puis "Petit" dans la colonne titre.
1 2 3 4 5 6 7 8 9 | SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('Petite'); SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('Petit'); |
Résultat de la première requête :
|
id |
auteur |
titre |
|---|---|---|
|
3 |
Daniel Pennac |
La Petite marchande de prose |
La deuxième requête (avec "Petit") ne renvoie aucun résultat. En effet, bien que "Petit" se retrouve deux fois dans la table (dans "La Petite marchande de prose" et "Les Petits Dieux"), il s'agit chaque fois d'une partie d'un mot, pas du mot exact.
Troisième exemple : on recherche "Henri" dans la colonne auteur.
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(auteur) AGAINST ('Henri'); |
|
id |
auteur |
titre |
|---|---|---|
|
16 |
Henri-Pierre Roché |
Jules et Jim |
Ici par contre, on retrouve bien Henri-Pierre Roché en faisant une recherche sur "Henri", puisque Henri et Pierre sont considérés comme deux mots.
Quatrième exemple : on recherche "Jules", puis "Jules Verne" dans les colonnes titre et auteur.
1 2 3 4 5 6 7 8 9 | SELECT * FROM Livre WHERE MATCH(auteur, titre) AGAINST ('Jules'); SELECT * FROM Livre WHERE MATCH(titre, auteur) AGAINST ('Jules Verne'); |
|
id |
auteur |
titre |
|---|---|---|
|
14 |
Jules Verne |
De la Terre à la Lune |
|
16 |
Henri-Pierre Roché |
Jules et Jim |
|
15 |
Jules Verne |
Voyage au centre de la Terre |
|
id |
auteur |
titre |
|---|---|---|
|
14 |
Jules Verne |
De la Terre à la Lune |
|
15 |
Jules Verne |
Voyage au centre de la Terre |
|
16 |
Henri-Pierre Roché |
Jules et Jim |
Ces deux requêtes retournent les mêmes lignes. Vous pouvez donc voir que l'ordre des colonnes dans MATCH n'a aucune importance, du moment qu'un index FULLTEXT existe sur ces deux colonnes. Par ailleurs, la recherche se fait bien sur les deux colonnes, et sur chaque mot séparément, puisque les premières et troisièmes lignes contiennent 'Jules Verne' dans l'auteur, tandis que la deuxième contient uniquement 'Jules' dans le titre.
Par contre, l'ordre des lignes renvoyées par ces deux requêtes n'est pas le même. Lorsque vous utilisez MATCH... AGAINST dans une clause WHERE, les résultats sont par défaut triés par pertinence.
La pertinence est une valeur supérieure ou égale à 0 qui qualifie le résultat d'une recherche FULLTEXT sur une ligne. Si la ligne ne correspond pas du tout à la recherche, sa pertinence sera de 0. Si par contre elle correspond à la recherche, sa pertinence sera supérieure à 0. Ensuite, plus la ligne correspond bien à la recherche (nombre de mots trouvés par exemple), plus la pertinence sera élevée.
Vous pouvez voir la pertinence attribuée à une ligne en mettant l'expression MATCH... AGAINST dans le SELECT.
Cinquième exemple : affichage de la pertinence de la recherche
1 2 | SELECT *, MATCH(titre, auteur) AGAINST ('Jules Verne Lune') FROM Livre; |
|
id |
auteur |
titre |
MATCH(titre, auteur) AGAINST ('Jules Verne Lune') |
|---|---|---|---|
|
1 |
Daniel Pennac |
Au bonheur des ogres |
0 |
|
2 |
Daniel Pennac |
La Fée Carabine |
0 |
|
3 |
Daniel Pennac |
La Petite marchande de prose |
0 |
|
4 |
Jacqueline Harpman |
Le Bonheur est dans le crime |
0 |
|
5 |
Jacqueline Harpman |
La Dormition des amants |
0 |
|
6 |
Jacqueline Harpman |
La Plage d'Ostende |
0 |
|
7 |
Jacqueline Harpman |
Histoire de Jenny |
0 |
|
8 |
Terry Pratchett |
Les Petits Dieux |
0 |
|
9 |
Terry Pratchett |
Le Cinquième éléphant |
0 |
|
10 |
Terry Pratchett |
La Vérité |
0 |
|
11 |
Terry Pratchett |
Le Dernier héros |
0 |
|
12 |
Terry Goodkind |
Le Temple des vents |
0 |
|
13 |
Daniel Pennac |
Comme un roman |
0 |
|
14 |
Jules Verne |
De la Terre à la Lune |
5.851144790649414 |
|
15 |
Jules Verne |
Voyage au centre de la Terre |
3.2267112731933594 |
|
16 |
Henri-Pierre Roché |
Jules et Jim |
1.4018518924713135 |
En fait, écrire :
1 | WHERE MATCH(colonne(s)) AGAINST (mot(s) recherché(s)) |
Cela revient à écrire :
1 | WHERE MATCH(colonne(s)) AGAINST (mot(s) recherché(s)) > 0 |
Donc seules les lignes ayant une pertinence supérieure à 0 (donc correspondant à la recherche) seront sélectionnées.
Recherche avec booléens
La recherche avec booléens possède les caractéristiques suivantes :
- elle ne tient pas compte de la règle des 50 % qui veut qu'un mot présent dans 50 % des lignes au moins soit ignoré ;
- elle peut se faire sur une ou des colonne(s) sur laquelle (lesquelles) aucun index
FULLTEXTn'est défini (ce sera cependant beaucoup plus lent que si un index est présent) ; - les résultats ne seront pas triés par pertinence par défaut.
Pour faire une recherche avec booléens, il suffit d'ajouter IN BOOLEAN MODE après la chaîne recherchée.
1 2 3 4 | SELECT * FROM nom_table WHERE MATCH(colonne) AGAINST('chaîne recherchée' IN BOOLEAN MODE); -- IN BOOLEAN MODE à l'intérieur des parenthèses ! |
La recherche avec booléens permet d'être à la fois plus précis et plus approximatif dans ses recherches.
- Plus précis, car on peut exiger que certains mots se trouvent ou soient absents dans la ligne pour la sélectionner. On peut même exiger la présence de groupes de mots, plutôt que de rechercher chaque mot séparément.
- Plus approximatif, car on peut utiliser un astérisque * en fin de mot, pour préciser que le mot peut finir de n'importe quelle manière.
Pour exiger la présence ou l'absence de certains mots, on utilise les caractères + et -. Un mot précédé par + devra être présent dans la ligne et inversement, précédé par - il ne pourra pas être présent.
Exemple : Recherche sur le titre, qui doit contenir "bonheur" mais ne peut pas contenir "ogres".
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('+bonheur -ogres' IN BOOLEAN MODE); |
|
id |
auteur |
titre |
|---|---|---|
|
4 |
Jacqueline Harpman |
Le Bonheur est dans le crime |
Seule une ligne est ici sélectionnée, bien que "bonheur" soit présent dans deux. En effet, le second livre dont le titre contient "bonheur" est "Le Bonheur des ogres", qui contient le mot interdit "ogres".
Pour spécifier un groupe de mots exigés, on utilise les doubles guillemets. Tous les mots entre doubles guillemets devront non seulement être présents mais également apparaître dans l'ordre donné, et sans rien entre eux. Il faudra donc que l'on retrouve exactement ces mots pour avoir un résultat.
Exemple : recherche sur titre, qui doit contenir tout le groupe de mot entre guillemets doubles.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('"Terre à la Lune"' IN BOOLEAN MODE); SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('"Lune à la Terre"' IN BOOLEAN MODE); SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('"Terre la Lune"' IN BOOLEAN MODE); |
Résultat première requête :
|
id |
auteur |
titre |
|---|---|---|
|
14 |
Jules Verne |
De la Terre à la Lune |
La première requête renverra bien un résultat, contrairement à la seconde (car les mots ne sont pas dans le bon ordre) et à la troisième (car il manque le "à" dans la recherche - ou il y a un "à" en trop dans la ligne, ça dépend du point de vue). "Voyage au centre de la Terre" n'est pas un résultat puisque seul le mot "Terre" est présent.
Pour utiliser l'astérisque, il suffit d'écrire le début du mot dont on est sûr, et de compléter avec un astérisque.
Exemple : recherche sur titre, sur tous les mots commençant par "petit".
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('petit*' IN BOOLEAN MODE); |
|
id |
auteur |
titre |
|---|---|---|
|
3 |
Daniel Pennac |
La Petite marchande de prose |
|
8 |
Terry Pratchett |
Les Petits Dieux |
"Petite" et "Petits" sont trouvés.
Exemple : recherche sur titre et auteur, de tous les mots commençant par "d".
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre, auteur) AGAINST ('d*' IN BOOLEAN MODE); |
|
id |
auteur |
titre |
|---|---|---|
|
1 |
Daniel Pennac |
Au bonheur des ogres |
|
2 |
Daniel Pennac |
La Fée Carabine |
|
3 |
Daniel Pennac |
La Petite marchande de prose |
|
13 |
Daniel Pennac |
Comme un roman |
|
4 |
Jacqueline Harpman |
Le Bonheur est dans le crime |
|
11 |
Terry Pratchett |
Le Dernier héros |
|
8 |
Terry Pratchett |
Les Petits Dieux |
|
5 |
Jacqueline Harpman |
La Dormition des amants |
Chacun des résultats contient au moins un mot commençant par "d" dans son titre ou son auteur ("Daniel", "Dormition"…). Mais qu'en est-il de "Voyage au centre de la Terre" par exemple ? Avec le "de", il aurait dû être sélectionné. Mais c'est sans compter la règle qui dit que les mots de moins de quatre lettres sont ignorés. "De" n'ayant que deux lettres, ce résultat est ignoré.
Pour en finir avec la recherche avec booléens, sachez qu'il est bien sûr possible de mixer ces différentes possibilités. Les combinaisons sont nombreuses.
Exemple : recherche sur titre, qui doit contenir un mot commençant par "petit", mais ne peut pas contenir le mot "prose".
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre) AGAINST ('+petit* -prose' IN BOOLEAN MODE); -- mix d'un astérisque avec les + et - |
|
id |
auteur |
titre |
|---|---|---|
|
8 |
Terry Pratchett |
Les Petits Dieux |
Recherche avec extension de requête
Le dernier type de recherche est un peu particulier. En effet la recherche avec extension de requête se déroule en deux étapes.
- Une simple recherche naturelle est effectuée.
- Les résultats de cette recherche sont utilisés pour faire une seconde recherche naturelle.
Un exemple étant souvent plus clair qu'un long discours, passons-y tout de suite.
Une recherche naturelle effectuée avec la chaîne "Daniel" sur les colonnes auteur et titre donnerait ceci :
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre, auteur) AGAINST ('Daniel'); |
|
id |
auteur |
titre |
|---|---|---|
|
2 |
Daniel Pennac |
La Fée Carabine |
|
1 |
Daniel Pennac |
Au bonheur des ogres |
|
13 |
Daniel Pennac |
Comme un roman |
|
3 |
Daniel Pennac |
La Petite marchande de prose |
Par contre, si l'on utilise l'extension de requête, en ajoutant WITH QUERY EXPANSION, on obtient ceci :
1 2 3 4 | SELECT * FROM Livre WHERE MATCH(titre, auteur) AGAINST ('Daniel' WITH QUERY EXPANSION); |
|
id |
auteur |
titre |
|---|---|---|
|
3 |
Daniel Pennac |
La Petite marchande de prose |
|
13 |
Daniel Pennac |
Comme un roman |
|
1 |
Daniel Pennac |
Au bonheur des ogres |
|
2 |
Daniel Pennac |
La Fée Carabine |
|
4 |
Jacqueline Harpman |
Le Bonheur est dans le crime |
En effet, dans la seconde étape, une recherche naturelle a été faite avec les chaînes "Daniel Pennac", "La Petite marchande de prose", "Comme un roman", "Au bonheur des ogres" et "La Fée Carabine", puisque ce sont les résultats de la première étape (une recherche naturelle sur "Daniel"). "Le Bonheur est dans le crime" a donc été ajouté aux résultats, à cause de la présence du mot "bonheur" dans son titre ("Bonheur" étant également présent dans "Au bonheur des ogres")
Ainsi s'achève la présentation des requêtes FULLTEXT, ainsi que le chapitre sur les index.
En résumé
- Un index est une structure de données qui reprend la liste ordonnée des valeurs auxquelles il se rapporte.
- Un index peut se faire sur une ou plusieurs colonnes ; et dans les cas d'une colonne de type alphanumérique (
CHAR,VARCHAR,TEXT, etc.), il peut ne prendre en compte qu'une partie de la colonne (les x premiers caractères). - Un index permet d'accélérer les recherches faites sur les colonnes constituant celui-ci.
- Un index
UNIQUEne peut contenir qu'une seule fois chaque valeur (ou combinaison de valeurs si l'index est composite, c'est-à-dire sur plusieurs colonnes). - Un index
FULLTEXT(réservé aux tables MyISAM) permet de faire des recherches complexes sur le contenu des colonnes le constituant.