Salut les agrumes !
Le saviez-vous ? Il n’existe apparemment aucun moyen simple et standard de faire des calculs avec des nombres rationnes en Java. Il existe bien une classe Fraction chez Apache Commons qui est fonctionnelle mais très limitée, et une antique bibliothèque de sciences qui ne semble plus exister depuis des années… et un projet récent et inconnu dont je n’ai découvert l’existence qu’il y a quelques jours. Je passe sur les implémentations triviales donc très basiques qu’on trouve dans des coins du net.
C’est pourquoi je me suis mis en tête de faire ma propre bibliothèque pour ça. Plus parce que ça m’amuse et par intérêt technique (notamment ce que ça tire comme problèmes de performances) que pour vraiment l’utiliser, étant donné qu’en fait je n’en ai pas besoin.
Mon but était donc triple :
- Faire une bibliothèque qui fonctionne et utilisable par tout le monde (donc un minimum testée).
- Faire des tests de performance dessus, par curiosité.
- Implémenter des fonctions qu’on ne trouve pas sur les quelques implémentations trouvées, en particulier les puissances rationnelles et la trigonométrie. Ce qui implique de gérer des nombres approximatifs, puisque rien que
sqrt(2)est un nombre irrationnel.
L’avant-première version de tout ça est JRational (quelle originalité !) et c’est disponible sous licence Apache 2.0 sur Github.
C’est pas tout à fait une version 1.0.0 release (et donc ça n’est pas publié sur Maven Central / Sonatype), mais les jar et leurs signatures sont disponibles, tout comme la Javadoc.
Techniquement c’est du Java 11, même si rien ne s’oppose à ce que je puisse construire une version compatible Java 8 (il faut que je trouve comment faire avec ma version de Gradle qui tourne que sur Java 11+). Le code s’appuie massivement sur BigDecimal ce qui permet une précision arbitraire et virtuellement infinie (une paire d’entiers de deux milliards de nombres chacun…) mais du coup ne garantit absolument rien sur les performances.
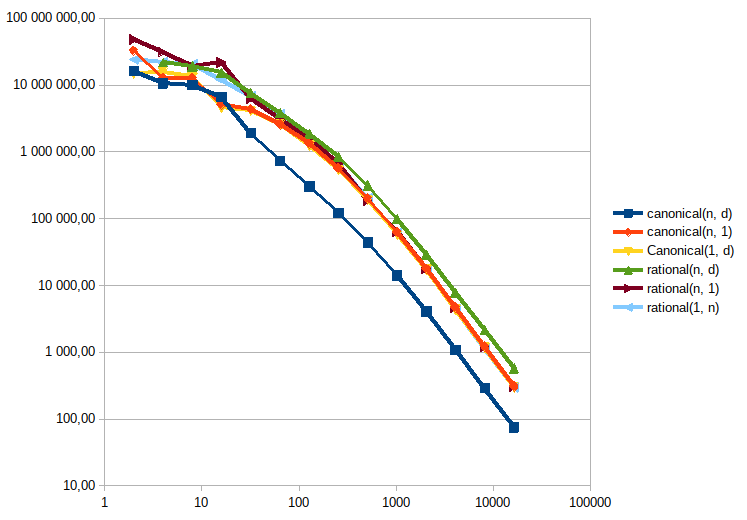
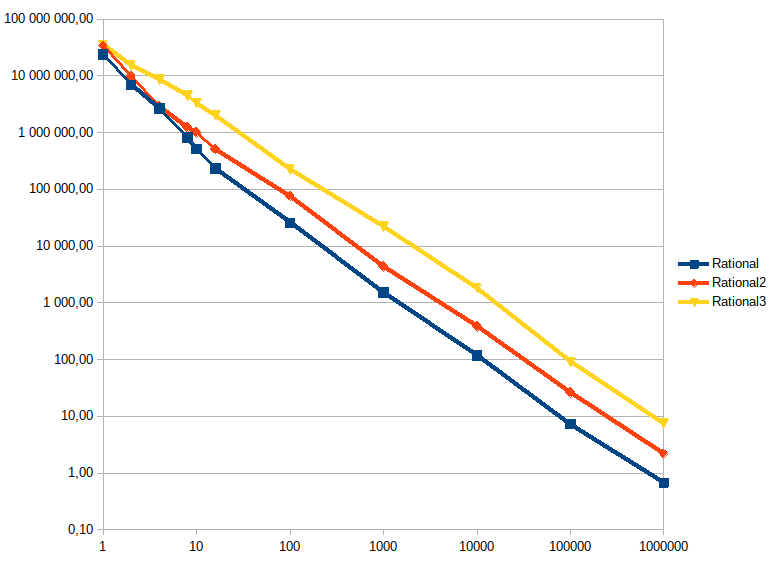
J’ai fait des tests de performance (ils sont ici, ./gradlew jmh pour les lancer, comptez plus de 3 heures pour la suite complète…). Ils montrent que les performances sont tout à fait acceptables pour des nombres de taille raisonnable (grosso modo O(1) jusqu’à 32 chiffres décimaux au total dans le rationel (numérateur + dénominateur), après quoi on est grosso modo en O(n) avec n le nombre de chiffres, en occupation mémoire comme en temps de calcul sur les opérations de base. Il y a une cassure dans la pente des performances, qui doit correspondre à un effet de la taille du cache du processeur : avant, 2x plus de chiffres = 2x plus de temps de calcul ; après, 2x plus de chiffres = 3 à 4x plus de temps de calcul (à la louche hein).
Les deux enseignement que j’en ait tiré, c’est que :
- Forcer le stockage de la forme canonique n’est pas intéressant, parce que la pénalité de performances est trop importante (le passage sous forme canonique nécessitant de calculer un PGCD, ce qui est lent).
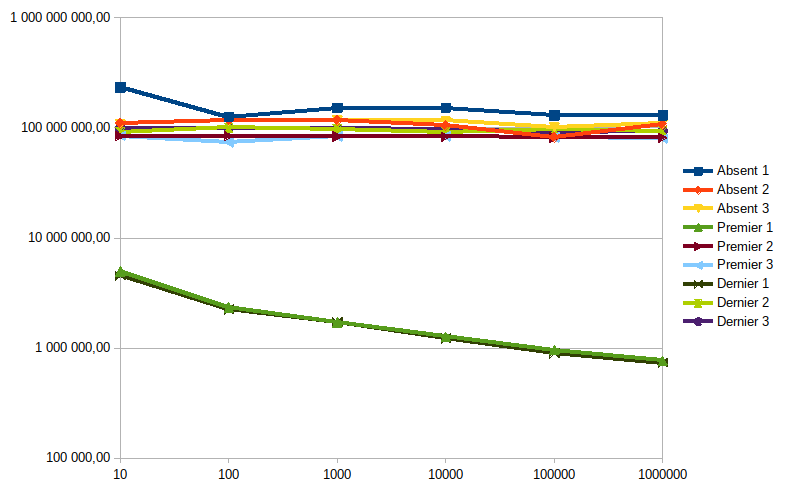
- Par contre il faut une méthode pour calculer cette forme à la demande, parce que certains algorithmes produisent des nombres avec des très grands nombres de chiffres qui sont très facilement simplifiables. Par exemple celui-ci, sans la canonicalisation, ne finit pas pour cause de nombres de plusieurs millions de chiffres ; mais avec, le calcul se fait en quelques dizaines de ms.
- Il faut aussi une méthode pour arrondir les valeurs qui deviennent trop précises pour leur propre bien (une chaine de calculs peut donner un rationnel exact, mais exprimé sous la forme de deux entiers gigantesques, de plusieurs milliers de chiffres chacun).
Bref, voilà où j’en suis aujourd’hui, je vise une v1.0.0 le WE prochain.
Je suis preneur de tous vos retours et pourquoi pas vos merge request, sur tous les sujets, y compris la gueule de l’API, les performances et les corrections d’anglais 
Ah, et merci à @Aabu, @Quentin et @KFC pour leurs articles sur les flottants sur ZdS (ici, ici et là) qui m’ont donné des idées de tests pour vérifier les intérêts et limites des calculs de rationnels par rapport aux flottants IEEE-754.
PS : dans ce qui est prévu aussi, c’est au moins une version Kotlin (et peut-être Groovy ?) qui permet d’utiliser la surcharge des opérateurs. Parce que sur des nombres, c’est quand même vachement pratique.