Y'a une différence entre "quelle donnée est disponible à travers une API" i.e. "quelle donnée est fournie par ZdS" et "quelle donnée est afffichée ou non dans l'UI".
Javier
Une donnée fournie par l'API de ZdS devrait être fournie dans une UI (certaines peut être moins visibles que d'autres), pour la simple et bonne raison qu'une fois que c'est disponible dans l'API tu ne peut pas interdire à un client tiers de l'afficher ailleurs. Pour rester cohérent il faudra donc que ce que donne l'API finisse sur le site d'une manière ou d'une autre.
Pour le reste, je laisse les avis s'exprimer sur la visibilité de la métrique.
Boarf. Avec l'API membre je peux savoir quels membres ont choisi de recevoir des notifs par mails mais je ne le vois pas sur le profil des membres. Manifestement ça pose pas de soucis particuliers
Bon, les problèmes récent de serveurs (et la défaite cuisante du PSG), m'ont empêché de trouver le temps d'avancer ici. Avec un peu de retard donc voici de quoi nous permettre d'avancer sur le sujet.
Comment allons nous stocker les informations ?
Pour répondre à cette question, je vous propose les modèles de stockage suivants. Si vous avez des avis sur un modèle en particulier, ou si vous avez de meilleures idées, c'est le moment d'en parler.
Un modèle full relationnel
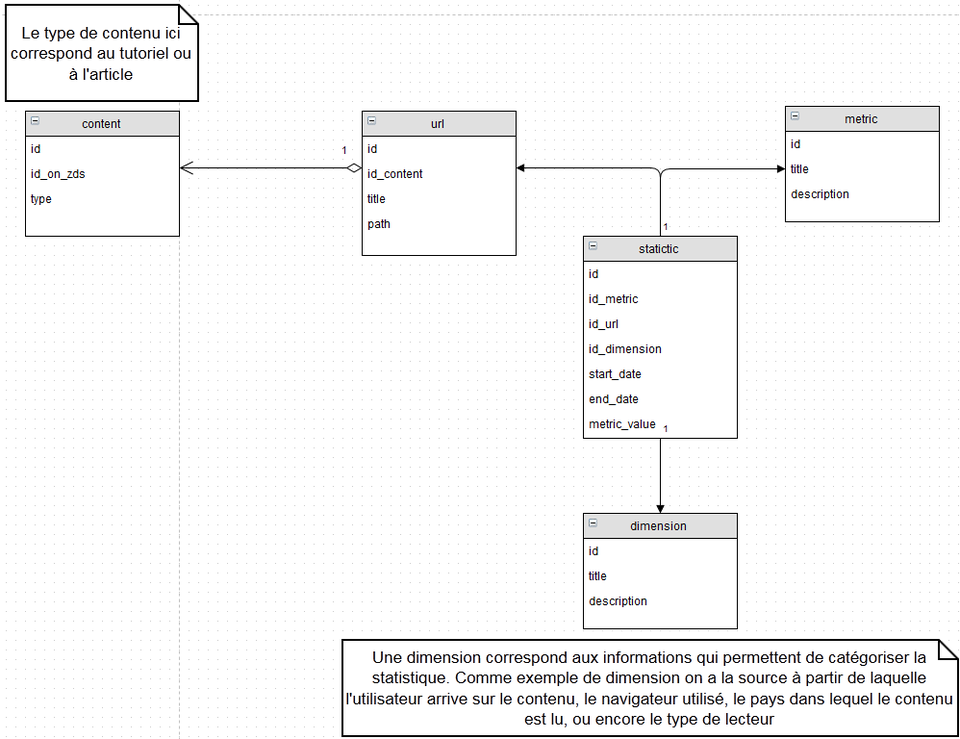
Modèle pleinement relationnel
Ici on stocke dans une base de donnée relationnelle les informations correspondants aux statistiques. On a donc un contenu (article, tutoriel, partie, chapitre) qui peut être rattaché à une ou plusieurs url (un tutoriel ), chaque url, dans une période précise, en fonction d'une métrique et de la dimension choisie est valorisée. Un exemple serait de dire que le tutoriel Symfony2 à reçu, du 17/04/2015 au 18/04/2015 (la période), 41 visites (la métrique), provenant de Twitter (la dimension).
Avantage
Ce modèle est très flexible et théoriquement simple à manipuler
Inconvénient
Ce modèle demande la création de plusieurs table, et étant donné notre objectif, chaque requête demande une jointure sur toutes tables.
Un modèle semi-relationnel
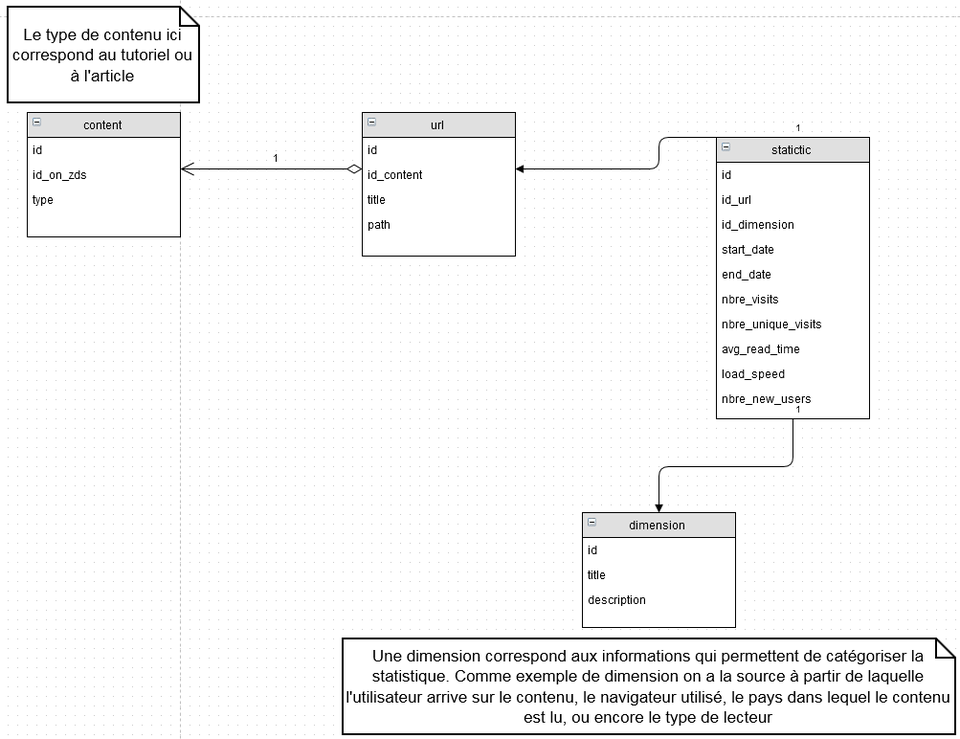
Modèle semi-relationnel
Sa différence par rapport au modèle du dessus, est qu'on réduit le nombre de tables (on passe de 5 à 4) pour la simple et bonne raison qu'étant donné que l'on sait quelle métrique il nous faut on peut directement les dénormaliser dans la table des statistiques.
Avantages
Par rapport au modèle précédent, on limite le nombre de jointures. De meilleures perfs en lecture donc.
Inconvénient
Même si on reste quand même assez flexible, il ne faudra pas qu'on rajoute beaucoup de métriques par la suite. La table statistique a gagné en colonnes, et si demain on a envie de plus de métriques, ça fera des colonnes en plus, ce qui commencerait à devenir embêtant pour les requêtes.
Un modèle full dénormalisé
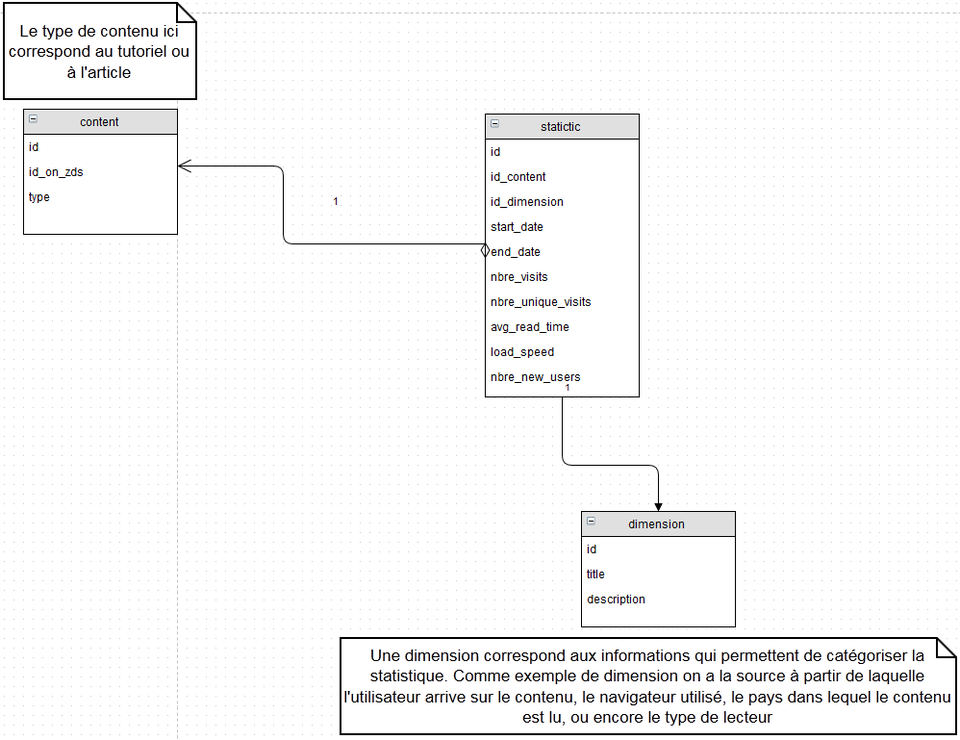
Ce modèle met de coté certaines formes normales pour tout (ou presque) balancer dans la table des statistiques.
NB : comme vous le voyez, on ne peut pas vraiment mettre les dimensions en tant que colonne de la table des statistiques, on se retrouverai avec un produit cartésien immonde.
Avantages
Moins de table à jointurer pour les requêtes. Pour un outil de statistiques, il faut que la requête d'interrogation soit la plus rapide possible. On s'en fou presque du temps d'écriture.
Inconvénients
En plus des inconvénient de la solution précédente, on casse des formes normales, donc on se traine des doublons dans les tables, ce qui n'est pas forcément génial en terme d'espace de stockage.
Un modèle document
J'ai un peu simplifié, pour donner une idée générale de représentation. Je détaillerai si nécessaire.
Ce modèle consiste à stocker chaque contenu (tutoriel, article, chapitre, etc.) sous forme de document, à enregistrer dans une base de donnée Not Only SQL.
Avantages
Le besoin étant un besoin en lecture rapide (pour les stats), on s'affranchit des contrainte d'intégrité, et de la gestion transactionnelle/concurrentielle. Les propriétés ACID d'une base relationnelle n'ont aucun intérêt ici, le NoSQL permet de s'en affranchir et de délivrer des performances au dessus des solutions précédentes.
inconvénients
Les documents (indexés) prennent de la place non négligeable sur un disque (avec un bon choix de techno, c'est la même volumétrie que la solution précédente en terme d'espace occupé).
Un modèle Clé valeur
Il s'agit d'enregistrer toutes nos statistiques sous formes de clé-valeurs. La clé étant l'identifiant du contenu.
Personnellement, je n'ai pas détaillé plus que ça la solution, car elle ne me parait pas envisageable étant donné l'espace (mémoire et disque) immonde qu'elle nécessitera.
J'ai un peu de mal a comprendre tes start_date et end_date, pour moi on allait récupérer les infos journalières (niveau de précision largement suffisant) donc on a juste besoin de stocker la journée concerné. Ça simplifiera aussi considérablement la lecture si on sait qu'on a une seul valeur par jour : faire un graph sur le mois -> on récupere toutes les valeurs qui sont compris dans l'intervalle, "moyenne sur 7 jours glissant" -> idem, "Moyenne des mardi" -> on récupère tous les mardis, etc.
Si tu commence a mélanger dans ta base des donénes sur plusieurs intervales de durées différentes, ça va être la misère : "la moyenne de vue un mardi" -> Impossible tu n'a les données que par paquet de 2 jours, oblige a agréger avant de moyenner si les données sont sur un intervalle plus court.
Donc je propose qu'on stocke pour chaque contenu les données de chaque jour indépendamment. D'autant que vers minuit le serveur est globalement au calme.
Tu fais comment si le mec qui consulte les stats est au Québec et qu'il demande "les mardis" ? Tu vas lui mentir avec ton système.
Si on se rend compte "qu'un jour" c'est pas convenable comme unité de temps (trop court, trop long), faut revoir tout le modèle de stockage.
Si tu choisis une nouvelle fenêtre d'échantillonnage plus grande (2 jours au lieu d'un) t'as un script de migration de données à écrire, chiant, mais faisable, mais pas de script de migration de schéma.
Si tu choisis une nouvelle fenêtre d'échantillonnage plus petite, t'es niqué, dans les deux cas.
La solution de firm1 (sur ce point) me semble quand même plus souple. Même si 1 jour est effectivement la bonne plage de temps.
Si ça ne tenais qu'a moins je stockerai par heure MAIS on risque d'exploser notre quota d'appel à l'API.
Ce qui est proposé par firm1 est plus souple MAIS va grandement compliqué toute l'exploitation. Les métriques calculables ne pourront être définit qu'a l’exécution et ça va demander un paquet de code spaghetti pour agréger ça correctement avant même le moment de faire les calculs correct.
Donc je maintiens, peut être que la journée n'est pas le meilleur intervalle mais un intervalle fixe simplifierait et le stockage et l'exploitation des données
Le couple start_date/end_date est là surtout pour marquer la période. C'est la solution, qui peu le plus et donc plus flexible, comme le mentionne Javier.
Je ne pense pas que ça complexifie tant que ça, pour la simple raison que l'API est là pour mapper les choses dans le bon sens, et délivrer quelque chose d'adapté.
Quoiqu'il en soit on s'accorde tous à dire que la bonne période est la journée, c'est déjà un bon point.
D'ailleurs je vais mettre à jour le premier topic pour noter les points qui sont validés au fur et a mesure de la ZEP et les questions en suspens.
Sinon, en ce qui concerne le modèle de stockage, la forme de document me semble être le plus efficace compte tenu de nos besoins. C'est très certainement la solution qui offre les meilleures performances en lecture (notre besoin primordial pour ce module). Je suis d'avis de partir là dessus, sauf s'il y'a des avis contraire ?
Tu fais comment si le mec qui consulte les stats est au Québec et qu'il demande "les mardis" ? Tu vas lui mentir avec ton système.
Javier
C'est un faux argument, à mon sens. D'après nos stats, plus de 90 % des visites viennent de France ou de pays dans le même fuseau horaire. Le trafic généré un mardi, c'est le trafic généré pendant un de nos mardis, pas un mardi du Québec. Et si tu lui présentes les données effectivement générées pendant son mardi, elles n'auront pas de sens, car la moitié aura été créée par une dynamique, et la moitié par une autre.
Pour prendre un exemple plus clair, si tu ne cadres pas les données sur notre découpage circadiaire, un Québécois aura l'impression que le dimanche et le vendredi ont tous les deux une fréquentation moyenne, seul le samedi étant vraiment bas, parce que cela correspondra respectivement à une moitié d'un de nos dimanches et une moitié d'un lundi, et pareil un demi-vendredi et un demi-samedi.
Firm1 : ca dépend. Généralement on prend des intervales inférieur a ceux d'étude. Typiquement l'idéal pour nous serait les heures. Mais j'imagine que c'est pas possible a cause du nombre de requête api
@Kje : je pense que tout le monde est d'accord pour dire qu'un intervalle fixe est la meilleure solution. Et que les données ne devraient pas être disparates.
Simplement, pour modéliser cet intervalle de temps, plutôt que de dire "le jour machin", il vaudrait mieux donner son timestamp de début et son timestamp de fin.
Notamment parce que si tu te rends compte que un jour c'est trop, et qu'il faut passer sur deux jours, tu vas pouvoir migrer toutes les données sans changer le modèle.
Il n'est pas question de stocker des données disparates, elles doivent, je pense être fixes. Mais ça me semble moins "dangereux" de partir sur start<->end au cas où du jour on passerait à deux jours, (dans l'autre sens, je répète, on est cuit).
OUI pour l'ensemble, et OUI pour le détail de chaque chapitre s'il s'agit d'un big tuto ; ça permet de voir quels chapitres intéressent le plus (ou le moins) les lecteurs
2
OUI ; et idem qu'au dessus, le temps sur chaque chapitre, sans ça je trouve que cette métrique est inutile
3
POURQUOI PAS
4
NON
5
NON
6
NON
7
NON
8
POURQUOI PAS
9
NON ; on n'est pas là pour savoir qui a la plus grosse
10
OUI ; très intéressant pour ceux qui veulent faire un peu de SEO
Concernant le débat pour ou contre afficher uniquement à l'auteur d'un cours, je préfère que ce soit affiché pour tout le monde.
Concernant le système de stockage, est-il envisageable de coupler une BDD avec un NOSQL ?
Tous les jours à 02h00 du mat (enfin la nuit quoi !), les stats sont enregistrées en BDD ; dès que c'est fait, une partie des stats est recalculée (en ajoutant juste les nouvelles valeurs, pas en recalculant tout) et stockée en NOSQL (type Redis). Ça permet de récupérer très rapidement les stats « classiques » genre le nombre de visites ou les mots clés. Et si quelqu'un veut les stats pour un jour en particulier, la BDD prend le relai.
Ça permet a priori d'avoir un cache de données pas trop lourd car globales mais accessibles rapidement.
Concernant le débat pour ou contre afficher uniquement à l'auteur d'un cours, je préfère que ce soit affiché pour tout le monde.
Ce point de vue semble être celui partagé par le plus grand nombre, je vais donc le placarder dans le premier post.
Concernant le système de stockage, est-il envisageable de coupler une BDD avec un NOSQL ?
Tous les jours à 02h00 du mat (enfin la nuit quoi !), les stats sont enregistrées en BDD ; dès que c'est fait, une partie des stats est recalculée (en ajoutant juste les nouvelles valeurs, pas en recalculant tout) et stockée en NOSQL (type Redis). Ça permet de récupérer très rapidement les stats « classiques » genre le nombre de visites ou les mots clés. Et si quelqu'un veut les stats pour un jour en particulier, la BDD prend le relai.
Ça permet a priori d'avoir un cache de données pas trop lourd car globales mais accessibles rapidement.
John
Si j'ai bien compris cette conception, ça revient à utiliser une BD relationnelle avec un système de cache de certaines données (les données cachés étant stockées dans un NoSQL). C'est une solution hybride, mais qui a aussi ses inconvénients dans le sens ou l'API doit pointer sur toutes les données (classiques ou non). Étant donné qu'on ne sait pas quelle sera l'utilisation de l'API, si elle est utilisée pour faire des courbes au delà des données classiques, les données en questions ne seront pas forcément dans le cache.
C'est pourquoi, tout stocker dans un NoSQL me semble avantageux pour une mise à disposition à la fois scalable et performante des données.
Je trouve ça également plus avantageux de tout stocker en NoSQL.
Pour l'API, ça ne poserait pas vraiment de soucis ; ça fait deux traitements différents parce que deux manières de stocker mais ça ne me semble pas être un gros problème.
ça m'a l'air bien tout ça, j'ai mis à jour le premier post, et visiblement il ne reste plus que deux questions en suspens (on arrive bientôt au bout de cette spec ).
La question du jour est la suivante
Qu'est-ce qu'on choisi comme technologie de stockage NoSQL ?
Pour assurer ce rôle on pourrait penser aux SGBD suivants :
Solr : Opensource, écrit en Java. C'est avant tout un moteur d'indexation avant d'être un SGBD. J'en parle parce qu'il fait déjà parti de la stack applicative de ZdS et qu'il pourrait remplir ce rôle. Cependant, je poserai quand même un bémol car l'outil n'as pas de module de sécurité et son principal avantage est la recherche full text, chose dont on a pas besoin pour des statistiques.
CouchDB : Opensource, écrit en Erlang. C'est un SGBD orienté document, qui se veut scalable et se prêterait bien aux besoins de ZdS.
MongoDB : Opensource, écrit en C++. Lui aussi un SGBD orienté document, scalable, performant, avec une bonne communauté et un système de mise à jour correct. Tout indiqué lui aussi pour répondre à nos besoins. Il a l'avantage d'offrir une syntaxe de requêtage proche du populaire SQL.
Cassandra : Opensource, écrit en Java. Je ne l'ai jamais utilisé, donc j'aurai du mal à parler de ses facultés. Mais de ce que j'en pu en lire, il est très bon dans la gestion des bases de données multi-site.
Si je devais choisir, je partirai bien sur du MongoDB parce qu'il est simple a mettre en place et que je connais assez bien.
Cassandra: ultra complexe à installer puis à administrer, déjà que node tue Spacefox à petit feu, si on lui impose un cassandra par derrière on va l'achever
CouchDB : simple d'utilisation mais force le paradigme map/reduce dès que tu veux faire des sélections un peu plus poussées. J'ai bien aimé m'en servir mais j'ai trouvé le binding python un peu grade.
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte








 ).
).