
NOTE: Cette ZEP possède une spécification technique, située ici.
| Cartouche | |
|---|---|
| ZEP | 12 |
| Titre | refonte du principe des tutoriels et articles |
| Révision | 8 |
| Date de création | 25 juillet 2014 |
| Dernière révision | 16 septembre 2014 |
| Type | Feature |
| Statut | En production |
Cette ZEP-12 a pour but de donner les spécifications pour améliorer fortement le système d'édition de tuto zds. Pour obtenir l'état de ce qu'il se fait dans le module de tuto lors de la rédaction de la ZEP, c'est ici. Pour les discutions concernant le système de versionnage des tutoriels, c'est dans la ZEP-08.
Situation générale
Aujourd'hui, les tutoriels et articles sont considérés comme des entités séparées. Un article repose sur un seul extrait1. Concernant les tutoriels, on retrouve les mini-tutoriels, qui sont composés d'un chapitre comprenant plusieurs extrait et les big-tutoriels qui sont composés de plusieurs parties, comprenant plusieurs chapitres, comprenant plusieurs extraits.
Durant une discutions sur la possibilité de tutoriaux de longeurs intermédiaires, feature manquante à ZdS et qui semblait retenir l'attention de la communauté, ShigeruM a proposé que pour casser les barrières entre les différents niveaux de structures des tutoriaux (mini/moyen/big), on repense le système afin de mettre comme base base atomique "l'extrait". Cette ZEP reprend fortement cette idée.
L'extrait, base atomique
Dans cette nouvelle vision des choses, il faudrait que l'utilisateur puisse rédiger et assembler les extraits "comme bon lui semble" sur 4 niveaux de structures, qui définiraient ce qu'est le tutoriel/l'article :
- Extrait seul : il s'agit d'un article
- Plusieurs extrait rassemblés sous un même titre (chapitre ?) : il s'agit d'un mini-tuto
- Plusieurs chapitre rassemblé sous un même titre (partie ?) : il s'agit d'un moyen-tuto
- Plusieurs parties rassemblées sous un même titre : il s'agit d'un big-tuto
Mise en place
Il sera nécessaire d'écrire un script de migration si cette ZEP voit le jour.
Généralité :
Un document sera construit grâce à trois objets :
1 2 3 4 5 6 | Document (conteneur principal, conservé en base de donnée avec les métadonnées)
|
+-- Section (conteneur secondaire, avec titre, introduction et conclusion et
peuvent s’emboîter dans eux-même jusqu'à 3 niveaux)
|
+-- Extrait (conteneur tertiaire correspondant à un fichier de contenu et à un titre)
|
ou, de manière plus complète, comme suis :
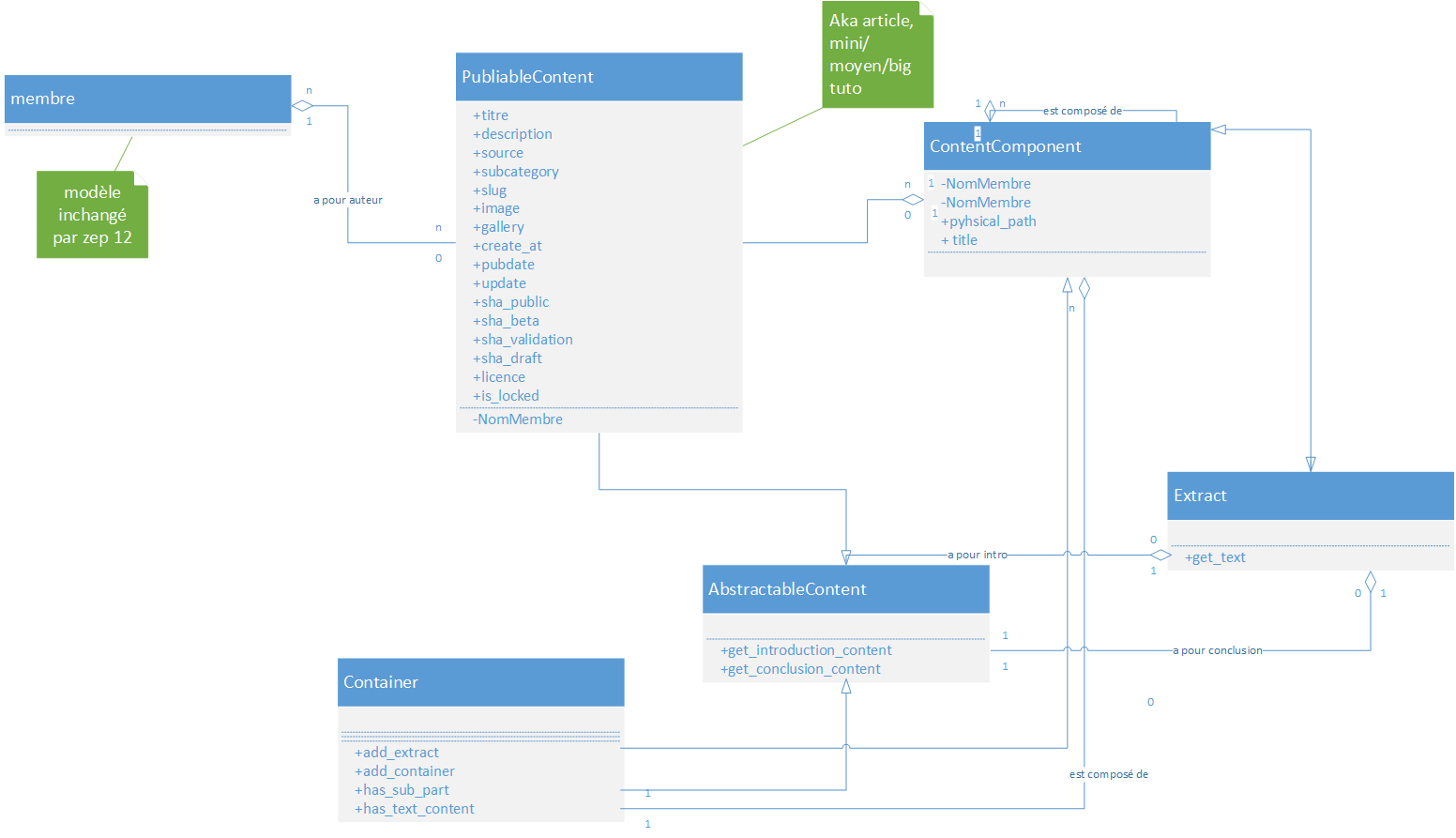
- Un Document aura pour enfant une Section, qui détermineront le titre du tutoriel, et son éventuelle introduction/conclusion
- Une Section aura pour parent soit une autre Section, soit un Document et pour enfant une liste de Sections ou une liste d'Extrait.
- Un Extrait représentera un fichier Markdown et possédera un titre.
- La liste des métadonnées associées à un tutoriel est reprise ici
La structure doit permettre une liberté dans la construction du Document, un extrait ne devant pas forcément avoir pour parent 3 Sections. Ce genre de structure doit être permises, en fonction des souhaits de l'auteur :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | Document
|
+--- Section
| |
| +--- Extrait : blabla
| +--- Extrait : blabla
| +--- Extrait : blabla
|
+--- Section
| |
| +--- Extrait : blabla
|
+--- Section
| |
| +--- Section
| | |
| | +--- Extrait : blabla
| | +--- Extrait : blabla
| | +--- Extrait : blabla
| |
| +--- Section
| |
| +--- Extrait : blabla
| +--- Extrait : blabla
| +--- Extrait : blabla
|
+--- Section
|
+--- Extrait : blabla
+--- Extrait : blabla
+--- Extrait : blabla
|
Cette structure sera écrite de manière complète dans le manifest.json, et c'est ce même fichier qui permettra la construction de la structure du document, qui ne doit donc pas être stockée en base de donnée. Ce manifest.json aura une structure qui reprendra le diagramme de classe repris ci-dessus.
En fonction de cette structure, les fichiers correspondants seront déplacés dans des dossiers.
L'auteur devra pouvoir déplacer un extrait dans n'importe quelle section du document.
Chaque Section et chaque Extrait doit présenter une clé nominale unique permettant de les différencier (et d'éviter les doublons) et de les retrouver facilement dans la structure du Document.
Visualisation :
- En fonction de la "profondeur" du "Document", le front adoptera la bonne manière de présenter les choses. Une seule template sera nécessaire à la visualisation de chaque niveau; puisqu'il ne s'agit que de visualiser un conteneur donné.
- La distinction article/tutoriel (nécessaire à la page d'accueil) se fera sur le "Document" au moment de l'exportation, sur base de la structure interne. À ce moment, s'il s'agit d'un article, il faudra que la structure soit gelée (pour qu'un article ne devienne pas un tutoriel par la suite).
- L'exportation qui est faite à la publication devrai générer un fichier HTML qui minimise au maximum la re-construction à postériori. Typiquement, il faut qu'une Section de Sections possède également un fichier HTML avec son introduction, sa conclusion et des liens vers les Conteneur enfants, et ce pour minimiser la lecture disque ainsi que le travail a effectuer par le back lors de la visualisation d'un tutoriel.
Édition :
- La méthode actuelle est conservée, la modification de la Section (ainsi que son déplacement éventuel), ce fait sur la page de ce dernier.
- Les extraits doivent pouvoir être modifié sur une page à part, comme c'est le cas aujourd'hui.
- Il est nécessaire de limiter les libertés de l'auteur afin qu'il ne puisse pas placer plus de deux extraits dans une Section de Sections ou placer une Section enfant dans une Section contenant déjà des Extraits
Proposition d'UI s'adaptant en fonction du cas
Section vierge
Ajouter une introduction
Ajouter un extrait
Ajouter une section
Ajouter une conclusion
Section ayant déjà des extraits
Ajouter une introduction
- Extrait 1
- Extrait 2
Ajouter un extrait
Ajouter une conclusion
Section ayant déjà des sections enfants
Ajouter une introduction
- Section existante
Ajouter une section
Ajouter une conclusion
Conteneur ayant déjà un conteneur et un extrait en guise d'intro
Extrait "Introduction"
Section existante
Ajouter une section
Ajouter une conclusion
Conteneur ayant déjà un conteneur et un extrait en guise d'intro et un second en guise de conclusion
Extrait "Introduction"
Section existante
Ajouter une section
- Extrait "Conclusion"
Non-régression
L'implémentation de cette ZEP devra se faire en tenant particulièrement compte des points suivants :
- Le contenu actuel du site (article, tutoriel, etc.) doit pouvoir être migrés vers le nouveau système sans perte d'historique des fichiers, ni d'url.
- On ne doit pas avoir de régression du système par rapport à l'existant, c'est à dire :
- On doit pouvoir créer deux extrait avec le même nom
- Les urls existantes doivent rester valides (SEO toussa)
- On doit pouvoir importer les fichiers .tuto et archives zip
- On doit pouvoir générer les exports (epub, pdf, etc) au moins aussi bien que maintenant
- Les pages d'un tuto et articles doivent s'afficher en moins d'une seconde
- La recherche dans les contenu doit rester stable
- Le sommaire d'un tutoriel doit être disponible sur toutes les pages dans la sidebar
- La navigation par chapitre doit continuer à fonctionner, peut être différemment, mais garder une navigation par contenu logique.
La ZEP-12 ne change pas le contenu versionné, qui est le rôle de la ZEP-08
-
un extrait possède pour sens physique un fichier contenant du texte formaté en markdown. ↩






