Actuellement notre jeu de combat se joue à deux joueurs. C’est très bien, mais que diriez vous de pouvoir y jouer en solo ?
Pour cela il va nous falloir réaliser une « intelligence artificielle », très basique. Et pour arriver à nos fins et rendre le tout moins prédictible, on va y insérer des comportements aléatoires.
Comment gérer de l’aléatoire sur une machine aussi déterministe qu’un ordinateur ? C’est ce que nous allons voir ici.
Le module random
La bibliothèque standard de Python comprend un module random dédié aux opérations aléatoires.
Nous sommes sur un ordinateur et l’aléatoire n’est pas réellement possible1 mais il existe une astuce. Cette astuce ce sont les générateurs pseudo-aléatoires.
Ces générateurs sont des outils produisant des suites de nombres qui semblent aléatoirement tirés.
Pour cela ils s’appuient sur des paramètres extérieurs tels que le temps ou le statut des périphériques afin d’initialiser leur état, puis sur des opérations mathématiques pour générer un nombre en fonction des précédents.
En pratique ça fonctionne bien, mais attention : deux générateurs qui seraient initialisés avec la même valeur produiraient exactement les mêmes nombres.
Certains langages vous demandent d’initialiser le générateur pseudo-aléatoire avant de commencer à faire des tirages, mais Python le fait pour nous lors de l’import du module random, et est donc directement utilisable.
>>> import random
Le module propose de nombreuses fonctions, mais nous n’allons nous intéresser qu’à certaines d’entre elles.
Nombres aléatoires
Premièrement, le plus simple, les fonctions pour tirer un nombre entier aléatoire, tel un lancer de dé.
Il y en a deux, randrange et randint.
La première reçoit entre 1 et 3 arguments, comme la fonction range, formant donc un intervalle avec une valeur de début (0 si omise), de fin et un pas (1 si omis).
Elle renvoie un nombre aléatoire compris dans cet intervalle (pour rappel, la valeur de fin est exclue de l’intervalle).
Voici par exemple des tirages de nombres entre 1 et 6 (inclus).
>>> random.randrange(1, 7)
5
>>> random.randrange(1, 7)
4
>>> random.randrange(1, 7)
2
Ce qui est d’ailleurs strictement équivalent à :
>>> random.randrange(6) + 1
3
>>> random.randrange(6) + 1
2
(bien sûr, vous n’obtiendrez pas nécessairement les mêmes résultats que les exemples)
Si l’on ne souhaitait tirer que des valeurs de dé impaires, on pourrait ajouter un pas à notre appel.
>>> random.randrange(1, 7, 2)
5
>>> random.randrange(1, 7, 2)
1
>>> random.randrange(1, 7, 2)
3
La fonction randint est un peu similaire si ce n’est qu’elle prend deux arguments (ni plus ni moins) et qu’elle retourne un nombre de cet intervalle, bornes incluses.
Ainsi, notre tirage de dé se ferait comme suit.
>>> random.randint(1, 6)
6
>>> random.randint(1, 6)
4
Opérations aléatoires
Mais tirer un nombre aléatoire ce n’est pas tout, et le module propose d’autres opérations aléatoires intéressantes.
Par exemple, la fonction choice permet de sélectionner aléatoirement un élément dans une liste.
>>> actions = ['manger', 'dormir', 'aller au ciné']
>>> random.choice(actions)
'manger'
>>> random.choice(actions)
'aller au ciné'
Je parle de liste, mais tout objet se comportant comme une liste2 est aussi accepté, les range par exemple.
Ainsi, random.choice(range(1, 7)) est équivalent à random.randrange(1, 7).
>>> random.choice(range(1, 7))
3
Si vous souhaitez tirer plusieurs valeurs sans remise, choice ne sera pas adaptée, vous risqueriez de tirer plusieurs fois la même.
>>> random.choice(actions)
'manger'
>>> random.choice(actions)
'manger'
Dans ce cas orientez-vous vers sample, qui prend en argument le nombre de valeurs à tirer en plus de la liste.
>>> random.sample(actions, 2)
['dormir', 'manger']
Enfin, la fonction shuffle permet de simplement trier aléatoire la liste (elle modifie la liste reçue en paramètre).
>>> random.shuffle(actions)
>>> actions
['aller au ciné', 'manger', 'dormir']
>>> random.shuffle(actions)
>>> actions
['dormir', 'aller au ciné', 'manger']
C’est utile pour mélanger un paquet de cartes ou d’autres opérations du genre, et avoir ensuite un tirage sans remise.
>>> cards = ['as de pique', '3 de trèfle', '7 de carreau', 'dame de cœur']
>>> random.shuffle(cards)
>>> cards.pop()
'3 de trèfle'
>>> cards.pop()
'7 de carreau'
Distributions
Lois de distribution
Voilà pour ce qui est des tirages dit discrets (on a un ensemble de valeurs connues et on veut tirer une valeur dans celles-ci) mais il est aussi possible de tirer des nombres dans des intervalles continus.
Par exemple, très simple, la fonction random va renvoyer un nombre flottant entre 0 et 1 (1 étant exclu de l’intervalle).
>>> random.random()
0.9294919627802888
>>> random.random()
0.47588843177000617
Le tirage de ce nombre est uniforme, grossièrement cela veut dire qu’on a autant de chances de tirer un nombre n’importe où dans l’intervalle.
Une fonction est spécifiquement dédiée au tirage uniforme entre deux nombres flottants, il s’agit de la fonction uniform.
>>> random.uniform(0, 10)
1.4017486291855232
>>> random.uniform(0, 10)
5.926447309804371
Suivant les arrondis, la borne supérieure peut être inclue ou non dans l’intervalle, mais cela a peu d’importance : il est pratiquement impossible de tomber sur ce nombre précis, puisqu’il y en a une infinité1.
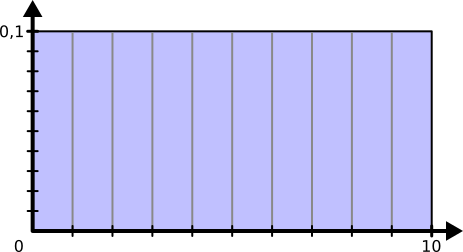
On a l’habitude de présenter une distribution par sa densité de probabilité, la fonction qui montre quelles zones de l’intervalle ont plus de chances d’être sollicitées.
Dans le cas d’une distribution uniforme, cette densité est constante.
D’autres distributions sont possibles pour les tirages de nombres flottants.
Il y a par exemple la distribution triangulaire accessible via la fonction triangular, qui prend en argument les deux bornes de l’intervalle.
On parle de distribution triangulaire car sa densité représente un triangle entre les deux bornes.
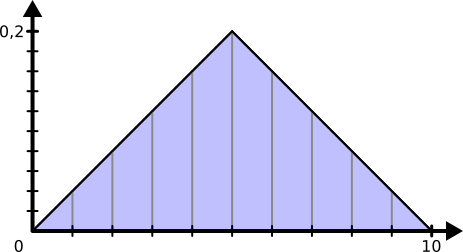
Ainsi, les valeurs autour du sommet du triangle auront plus de probabilité d’être tirées que celles aux extrémités.
>>> random.triangular(0, 10)
4.0479535343895865
Un troisième argument optionnel, le mode, permet de spécifier la valeur du sommet du triangle (par défaut il s’agit du milieu de l’intervalle, 5 dans notre exemple).
>>> random.triangular(0, 10, 2)
2.4400405218007473
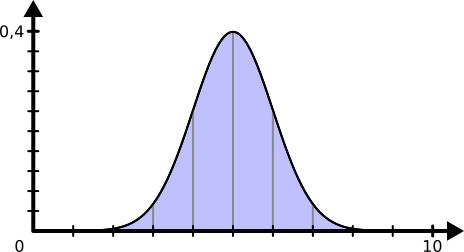
On trouve aussi la distribution normale, qui représente la distribution naturelle autour d’une moyenne avec un certain écart type.
La moyenne et l’écart type sont les deux arguments de la fonction normalvariate.
>>> random.normalvariate(5, 1)
4.655500829738334
>>> random.normalvariate(5, 1)
5.808402224132684
Sa densité de probabilité prend la forme d’une cloche centrée autour de la moyenne. Plus on s’éloigne de la moyenne, moins les valeurs ont de chance d’être tirées.
Pondération
Un autre point important à propos des tirages aléatoires concerne la pondération. En effet, les tirages discrets que nous avons effectués jusqu’ici étaient tous uniformes : chaque valeur avait autant de chance que les autres de tomber.
Avec random.randint(1, 6), chaque valeur a une probabilité de d’être tirée.
On peut d’ailleurs le vérifier en simulant un très grand nombre de tirages et en calculant le nombre d’occurrences de chaque valeur pour en déterminer la fréquence.
Si le tirage est bien uniforme, chaque valeur est censée être équitablement présente.
>>> from collections import Counter
>>> occurrences = Counter()
>>> N = 10000
>>> for _ in range(N):
... val = random.randint(1, 6)
... occurrences[val] += 1
...
>>> for val, occ in sorted(occurrences.items()): # sorted pour afficher selon l'ordre des clés
... print(f'{val}: {occ / N}')
...
1: 0.1649
2: 0.1638
3: 0.1687
4: 0.1695
5: 0.1654
6: 0.1677
On voit que chaque fréquence est proche de 0,1666.
Mais parfois on souhaiterait pouvoir pondérer notre tirage, affecter un poids différent à chaque valeur.
Une manière de faire serait d’utiliser un choice et d’y mettre plusieurs fois les valeurs selon l’importance que l’on souhaite leur donner.
choices = [1, 2, 3, 4, 4, 5, 5, 6, 6, 6]
Ici, 6 a une probabilité de 0,3 () d’être tiré, 4 et 5 en ont une de 0,2 et les autres sont de 0,1.
>>> occurrences = Counter()
>>> for _ in range(N):
... val = random.choice(choices)
... occurrences[val] += 1
...
>>> for val, occ in sorted(occurrences.items()):
... print(f'{val}: {occ / N}')
...
1: 0.0982
2: 0.1021
3: 0.0968
4: 0.1982
5: 0.1985
6: 0.3062
Mais j’ai choisi un exemple facile, il est généralement assez compliqué de déterminer combien de valeurs on souhaite metre en fonction de la probabilité que l’on veut leur donner, et cela peut amener à des listes de valeurs assez grandes.
Heureusement, Python a pensé à nous et propose une fonction qui prend directement en compte la pondération, il s’agit de la fonction random.choices.
Par défaut la fonction est sembable à choice, attribuant le même poids à chaque valeur, sauf qu’elle renvoie la valeur tirée sous forme d’une liste.
>>> random.choices(range(1, 7))
[6]
C’est parce qu’il est possible de lui demander de tirer plusieurs valeurs (avec remise) en utilisant le paramètre k.
>>> random.choices(range(1, 7), k=3)
[1, 1, 6]
Mais l’intérêt de cette fonction se situe dans son deuxième argument qui est une liste de poids, correspondant donc aux valeurs données en premier argument. Notre tirage de tout à l’heure pourrait se réécrire de la façon suivante :
>>> weights = [0.1, 0.1, 0.1, 0.2, 0.2, 0.3]
>>> random.choices(range(1, 7), weights)
[5]
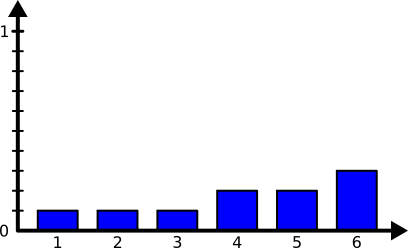
Encore une fois, on peut le vérifier en calculant les fréquences d’apparition.
>>> occurrences = Counter()
>>> for _ in range(N):
... val = random.choices(range(1, 7), weights)[0] # Attention, choices renvoie une liste
... occurrences[val] += 1
...
>>> for val, occ in sorted(occurrences.items()):
... print(f'{val}: {occ / N}')
...
1: 0.0995
2: 0.1008
3: 0.1008
4: 0.2018
5: 0.2
6: 0.2971
J’ai utilisé ici des fréquences comme poids, mais il est possible d’utiliser n’importe quels nombres, Python calculera la fréquence en fonction de la somme des poids.
>>> weights = [1, 1, 1, 2, 2, 3]
>>> random.choices(range(1, 7), weights)
[2]
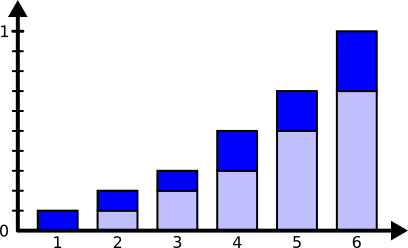
Enfin, il est aussi possible d’utiliser des poids cumulés pour le tirage.
Dans ce cas, la fonction prend un paramètre cum_weights définissant ces poids.
Les poids cumulés peuvent être vus comme une réglette graduée entre 0 et 1, chaque valeur se voyant attribuer une graduation. Un nombre est tiré entre 0 et 1, et c’est la valeur située juste à droite de cette graduation qui sera sélectionné.
Notre tirage précédent peut alors s’écrire comme suit.
>>> cum_weights = [0.1, 0.2, 0.3, 0.5, 0.7, 1]
>>> random.choices(range(1, 7), cum_weights=cum_weights)
[5]
Je vous laisse calculer la fréquence des tirages pour le vérifier.
- Pas exactement puisque la représentation d’un flottant est finie, mais vous comprenez l’idée.↩