Dans ce chapitre nous allons découvrir les « expressions rationnelles » aussi connues sous le nom de regex (de l’anglais « regular expressions » parfois traduit en « expressions régulières ») et comment les utiliser en Python.
- Problématique
- Une histoire d'automates
- Module re
- Syntaxe des regex
- Quelques exercices
- Options
- Limitations
Problématique
On sait demander à Python de résoudre des problèmes simples sur des chaînes de caractères comme :
- récupère-moi les N premiers caractères de la chaîne (
my_string[:N]) ; - teste si telle chaîne commence par tel préfixe (
my_string.startswith(prefix)) ; - découpe-moi cette chaine en morceaux selon les espaces (
my_string.split(' ')) ; - etc.
Mais comment pourrions-nous procéder pour des problèmes plus complexes comme « est-ce que ma chaîne de caractères représente un nombre » ?1
Une solution évidente serait de tenter une conversion float(my_string) et voir si elle réussit ou elle échoue.2
Mais intéressons-nous ici à une autre solution qui consisterait à analyser notre chaîne caractère par caractère afin d’identifier si oui ou non elle correspond à un nombre.
La chaîne pourrait commencer par un + ou un -, suivraient une série de chiffres potentiellement suivis d’un . et d’une nouvelle série de chiffres.
def is_number(my_string):
# On traite notre chaîne comme un itérateur pour simplifier les traitements
it = iter(my_string)
first_char = next(it, '')
# On ignore le préfixe + ou -
if first_char in {'+', '-'}:
first_char = next(it, '')
# On vérifie que la chaîne contient au moins un caractère et commence par un chiffre
if not first_char.isdigit():
return False
for char in it:
if char == '.':
# Si on tombe sur un point, on sort de la boucle pour traiter la partie décimale
# On vérifie cependant que la partie décimale contient au moins un caractère
# et commence par un chiffre
next_char = next(it, '')
if not next_char.isdigit():
return False
break
elif not char.isdigit():
# Si le caractère n'est pas un chiffre, la chaîne ne peut pas représenter un nombre
return False
# On recommence pour la partie décimale (optionnelle)
for char in it:
if not char.isdigit():
return False
# On est arrivé jusqu'au bout, la chaîne représente un nombre
return True
>>> is_number('123')
True
>>> is_number('123.45')
True
>>> is_number('-123.45')
True
>>> is_number('+12000')
True
>>> is_number('abc')
False
>>> is_number('12c4')
False
>>> is_number('.5')
False
>>> is_number('10.')
False
>>> is_number('.')
False
>>> is_number('')
False
Cette solution est un peu fastidieuse mais nous verrons par la suite qu’il y a plus simple grâce aux regex.
- Nous ne nous intéresserons ici qu’aux notations simples pour des nombres décimaux comme
42,+12.5ou encore-18000, exit les nombres complexes ou les notations sans partie entière telles que.3ou à base d’exposants comme1e10.↩ - Ce qui ne remplit pas à 100% la demande puisque l’expression reconnaît les formes
.3,1e10et mêmeinfqui ne nous intéressent pas ici.↩
Une histoire d'automates
Ce processus que nous venons de réaliser avance pas à pas dans notre chaîne de caractères, identifiant à chaque étape s’il peut continuer ou s’il doit s’arrêter. On peut le représenter comme un ensemble d’états (les caractères ou motifs attendus dans la chaîne) reliés par des transitions/liens selon quand il est possible de passer d’un état à l’autre.
Voici ainsi une représentation schématique de notre fonction is_number, on l’appelle un automate fini.

is_number — image générée par regexperCette représentation nous montre que pour qu’une chaîne soit reconnue comme valide, il faut pouvoir trouver un chemin reliant l’état Start of line à l’état End of line en parcourant les caractères de la chaîne.
Chaque état traversé consomme un caractère et un état peut être traversé plusieurs fois si les transitions le permettent, formant ainsi une boucle.
Un automate fini est un modèle de calcul qui parcourt des données séquentiellement (notre chaîne caractère par caractère) afin d’identifier des motifs, le tout sans utiliser de mémoire pour se souvenir des caractères précédents.
L’ensemble des motifs (ou mots) qui peuvent être identifiés par un automate forme ce qu’on appelle un langage.
Dans notre exemple le langage est formé des représentations de nombres de la forme 123 et 4.56 pouvant être préfixés d’un + ou d’un -.
Il est d’usage de représenter un automate sous la forme d’un graphe montrant les relations entre les états comme précédemment.
Un état correspond à l’avancée dans la chaîne de caractères, en consommant les caractères qui correspondent au motif.
On part de l’état initial (à gauche) et on avance vers la droite tant qu’une transition correspond au caractère lu dans notre chaîne (plusieurs chemins sont possibles).
Si l’on atteint l’état final (à droite) alors c’est que le motif est reconnu dans la chaîne.
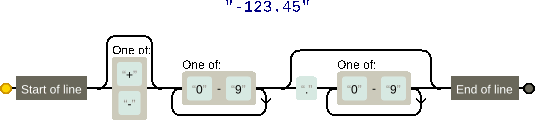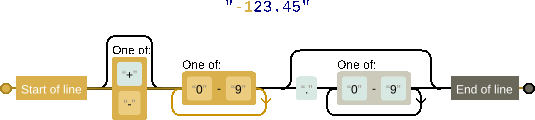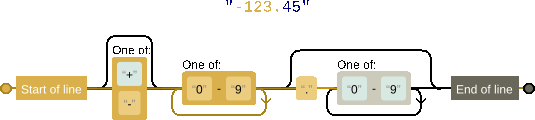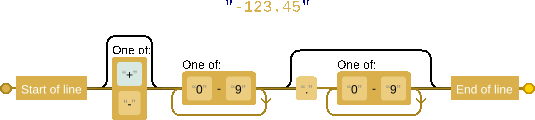
-123.45Il existe plusieurs types d’automates, les automates finis étant les plus simples d’entre eux. On dit d’un langage formé de mots reconnaissables par un automate fini qu’il est rationnel, d’où le terme d’expression rationnelle.
Le graphe ci-dessus illustre donc une expression rationnelle pour reconnaître les chaînes représentant des nombres. Mais nous allons tout de suite voir une manière plus formelle de la décrire.
Module re
En effet le graphe qui précède est bien joli, mais comment l’intégrer à notre programme pour pouvoir l’utiliser ?
Ce graphe n’est qu’une représentation de l’expression rationnelle comme il en existe d’autres (notre fonction is_number en est une elle aussi).
Le plus souvent, on va représenter ces expressions sous la forme de chaînes de caractères, où des caractères spéciaux permettront de décrire des motifs (comme des boucles).
Il existe plusieurs standards pour cela, les plus connus étant POSIX et PCRE (Perl-Compatible Regular Expressions).
Le standard POSIX est celui que l’on retrouvera dans des outils tels que grep ou sed.
En Python, c’est plutôt le standard PCRE qui est utilisé avec le module re.
Ce module regroupe les opérations permettant de travailler avec des expressions rationnelles, offrant différentes fonctions pour plusieurs usages (rechercher un motif, découper selon un motif, etc.).
Utilisation
On va y aller pas à pas pour construire une expression correspondant à notre besoin.
Nous allons tout d’abord importer le module re et nous intéresser à la fonction re.fullmatch.
C’est une fonction qui reçoit l’expression rationnelle (en premier argument) et le texte à analyser (en second) et qui renvoie un objet résultat ou None suivant si le texte correspond à l’expression ou non.
L’expression rationnelle peut être une chaîne de caractères toute simple (par exemple '123') et la fonction va alors simplement vérifier que les caractères correspondent un à un.
>>> import re
>>> re.fullmatch('123', '123')
<re.Match object; span=(0, 3), match='123'>
>>> re.fullmatch('123', '124')
On considère dans ce cas que la regex se compose de motifs (1, 2, 3) qui ne peuvent chacun identifier qu’un seul caractère.
On voit dans l’objet re.Match renvoyé par la fonction la zone qui a été identifiée dans le texte (la valeur span qui indique que le motif a été identifié entre les caractères 0 et 3) et l’extrait correspondant dans le texte (match, le texte complet dans notre cas).
Mais l’expression peut aussi contenir des caractères particuliers pour exprimer des motifs plus évolués. Ces motifs pouvant correspondre à plusieurs caractères dans notre texte.
Par exemple le caractère . utilisé dans une regex signifie « n’importe quel caractère » (comme un joker).
>>> re.fullmatch('12.', '123')
<re.Match object; span=(0, 3), match='123'>
>>> re.fullmatch('12.', '124')
<re.Match object; span=(0, 3), match='124'>
>>> re.fullmatch('12.', '134')
Un autre caractère particulier est le + qui indique que le motif qui précède peut être répété indéfiniment.
La regex 'a+' permet ainsi de reconnaître les suites de caractères a (minuscule, on note au passage que les regex sont sensibles à la casse par défaut).
>>> re.fullmatch('a+', 'a')
<re.Match object; span=(0, 1), match='a'>
>>> re.fullmatch('a+', 'aaaa')
<re.Match object; span=(0, 4), match='aaaa'>
>>> re.fullmatch('a+', 'aaab')
>>> re.fullmatch('a+', 'A')
Il est tout à fait possible de combiner nos motifs spéciaux, ainsi .+ identifie une suite de n’importe quels caractères : '123', 'aaa', 'abcd', etc.
>>> re.fullmatch('.+', '123')
<re.Match object; span=(0, 3), match='123'>
>>> re.fullmatch('.+', 'aaa')
<re.Match object; span=(0, 3), match='aaa'>
>>> re.fullmatch('.+', 'abcd')
<re.Match object; span=(0, 4), match='abcd'>
Dans le même genre que + on trouve aussi ? pour indiquer un motif optionnel.
Un motif suivi d’un ? peut donc être présent zéro ou une fois.
>>> re.fullmatch('a?b', 'ab')
<re.Match object; span=(0, 2), match='ab'>
>>> re.fullmatch('a?b', 'b')
<re.Match object; span=(0, 1), match='b'>
>>> re.fullmatch('a?b', 'a')
On peut utiliser des parenthèses comme en mathématiques pour gérer les priorités : (ab)? correspondra ainsi à la chaîne 'ab' ou à la chaîne vide, tandis que ab? correspond à 'a' ou 'ab'.
Dans notre cas initial, on cherche à pouvoir identifier des suites de chiffres. Pour cela il va nous falloir utiliser des classes de caractères : ce sont des motifs qui peuvent correspondre à plusieurs caractères bien précis (ici des chiffres).
On définit une classe de caractères à l’aide d’une paire de crochets à l’intérieur de laquelle on fait figurer tous les caractères possibles.
Par exemple [0123456789] correspond à n’importe quel chiffre.
Pour simplifier, il est possible d’utiliser un - pour définir un intervalle de caractères à l’intérieur de la classe : la syntaxe précédente devient alors équivalente à [0-9].
>>> re.fullmatch('[0-9]', '5')
<re.Match object; span=(0, 1), match='5'>
>>> re.fullmatch('[0-9]+', '123')
<re.Match object; span=(0, 3), match='123'>
is_number
Nous avons maintenant toutes les clefs en main pour recoder notre fonction is_number… ou presque !
En effet, dans notre nombre nous voulons pouvoir identifier un caractère ., mais nous savons que ce caractère est un motif particulier dans une regex qui fait office de joker.
Comment alors faire en sorte de n’identifier que le caractère . et lui seul ?
Il nous faut pour cela l’échapper, en le faisant précéder d’un antislash (\).
>>> re.fullmatch('\.', '.')
<re.Match object; span=(0, 1), match='.'>
>>> re.fullmatch('\.', 'a')
Reprenons maintenant le graphe de notre automate et décomposons-le.
is_number — image générée par regexperIl commence par un état Start of line, c’est-à-dire le début de la ligne.
re.fullmatch s’occupe déjà de rechercher un motif au début du texte donné, donc nous n’avons pas à en tenir compte ici.
L’état suivant est optionnel puisqu’il existe un chemin qui le contourne, il teste si le caractère est un + ou un -.
Cela correspond donc au motif [+-]? (à l’intérieur d’une classe de caractères, le + perd son statut de caractère spécial, de même pour - qui n’a pas de statut spécial s’il n’est pas suivi d’un autre caractère dans la classe).
On voit que l’état suivant forme une boucle : il y a en effet un chemin qui part de la droite de l’état pour revenir à sa gauche, qui permet de le répéter indéfniment.
Cette boucle correspond au symbole + que nous avons vu plus haut, qui signifie « au moins une fois ».
L’état en lui-même détaille que le caractère doit être entre 0 et 9, soit [0-9].
La regex correspondant à ce motif est donc [0-9]+.
Les deux états qui suivent peuvent-être court-circuités pour arriver directement à la fin, cela veut dire qu’ils forment un groupe optionnel (...)?.
Le premier état est un simple point (\.) et le second est une nouvelle suite de chiffres ([0-9]+).
Le groupe s’exprime donc sous la forme (\.[0-9]+)?.
Enfin, l’état End of line est lui aussi déjà géré par la fonction fullmatch.
En mettant tous ces extraits bout à bout, on forme la regex finale qui identifie nos nombres : [+-]?[0-9]+(\.[0-9]+)?.
>>> pattern = '[+-]?[0-9]+(\.[0-9]+)?'
>>> re.fullmatch(pattern, '123.456')
<re.Match object; span=(0, 7), match='123.456'>
>>> re.fullmatch(pattern, '-42')
<re.Match object; span=(0, 3), match='-42'>
>>> re.fullmatch(pattern, '100')
<re.Match object; span=(0, 3), match='100'>
>>> re.fullmatch(pattern, '0.0')
<re.Match object; span=(0, 3), match='0.0'>
>>> re.fullmatch(pattern, '.123')
>>> re.fullmatch(pattern, '123.')
>>> re.fullmatch(pattern, '.')
>>> re.fullmatch(pattern, 'abc')
La fonction is_number peut donc simplement être réécrite comme suit.
import re
def is_number(my_string):
result = re.fullmatch('[+-]?[0-9]+(\.[0-9]+)?', my_string)
return result is not None
Autres fonctions du module
D’autres fonctions sont aussi proposées par le module re pour réaliser d’autres opérations.
re.search
re.search est une fonction similaire à re.fullmatch à la différence qu’elle permet de trouver un motif n’importe où dans la chaîne.
>>> re.search('[0-9]+', 'abc123def')
<re.Match object; span=(3, 6), match='123'>
On remarque que les valeurs span et match du résultat correspondent à la zone où notre motif a été identifié dans le texte.
Cette valeur match est d’ailleurs récupérable en accédant au premier élément ([0]) de l’objet résultat.
>>> result = re.search('[0-9]+', 'abc123def')
>>> result[0]
'123'
Nous verrons par la suite que ce résultat peut en effet contenir plusieurs éléments.
Sachez qu’il existe les caractères spéciaux ^ et $ pour reproduire le comportement de fullmatch avec search : un motif débutant par ^ signifie que le motif doit être trouvé au début du texte et un motif finissant par $ signifie que le motif doit être trouvé à la fin.
>>> re.search('^[0-9]+', 'abc123')
>>> re.search('^[0-9]+', '123abc')
<re.Match object; span=(0, 3), match='123'>
>>> re.search('[0-9]+$', '123abc')
>>> re.search('[0-9]+$', 'abc123')
<re.Match object; span=(3, 6), match='123'>
En combinant les deux, re.search('^...$', ...) est alors équivalent à re.fullmatch('...', ...).
>>> re.search('^[0-9]+$', 'abc123def')
>>> re.search('^[0-9]+$', '123')
<re.Match object; span=(0, 3), match='123'>
On note qu’il existe aussi la fonction re.match qui recherche un motif au début du texte.
Elle est ainsi équivalente à re.search avec un ^ systématique.
re.findall
Cette fonction est un peu plus intéressante : elle permet de trouver toutes les occurrences d’un motif dans le texte. Elle renvoie la liste des extraits de texte ainsi trouvés.
>>> re.findall('[0-9]+', "Nous sommes le 31 mars 2022 et il fait 10°C")
['31', '2022', '10']
Si le motif n’est jamais trouvé, la fonction renvoie simplement une liste vide.
>>> re.findall('[0-9]+', "C'est bientôt le week-end")
[]
Dans la même veine, on trouve la fonction re.finditer qui ne renvoie pas une liste mais un itérateur pour parcourir les résultats.
Elle évite ainsi de parcourir le texte en entier dès le début et de constuire une liste.
>>> for result in re.finditer('[0-9]+', "Nous sommes le 31 mars 2022 et il fait 10°C"):
... print(result)
...
<re.Match object; span=(15, 17), match='31'>
<re.Match object; span=(23, 27), match='2022'>
<re.Match object; span=(39, 41), match='10'>
re.sub
Cette fonction permet d’opérer des remplacements (ou comme son nom l’indique des substitutions) sur un texte, remplaçant chaque occurrence du motif par la valeur précisée.
Elle prend donc en arguments la regex, la valeur par laquelle remplacer le motif, et le texte sur lequel opérer.
Et elle renvoie le texte après substitution.
>>> re.sub('[0-9]+', '?', "Nous sommes le 31 mars 2022 et il fait 10°C")
'Nous sommes le ? mars ? et il fait ?°C'
Si le motif n’est pas trouvé, alors le texte est renvoyé inchangé.
>>> re.sub('[0-9]+', '?', "C'est bientôt le week-end")
"C'est bientôt le week-end"
La valeur par laquelle remplacer le motif peut aussi prendre la forme d’une fonction. C’est alors cette fonction qui sera appelée pour chaque occurrence du motif, avec l’objet match en argument, et qui devra renvoyer le texte par lequel le remplacer.
>>> def replace_func(match_obj):
... return f'_{match_obj[0]}_'
...
>>> re.sub('[0-9]+', replace_func, "Nous sommes le 31 mars 2022 et il fait 10°C")
'Nous sommes le _31_ mars _2022_ et il fait _10_°C'
re.split
re.split est plus ou moins équivalente à la méthode split des chaînes de caractères, qui permet de découper la chaîne selon un séparateur, sauf qu’ici le séparateur est spécifié sous la forme d’une regex.
>>> re.split('[ ,.?!:]+', 'Alors : ça décoiffe, hein ?')
['Alors', 'ça', 'décoiffe', 'hein', '']
On constate qu’une chaîne vide est renvoyée dans le résultat si le texte termine par un séparateur. Mais on peut facilement la filtrer si elle ne nous intéresse pas.
>>> [s for s in re.split('[ ,.?!:]+', 'Alors : ça décoiffe, hein ?') if s]
['Alors', 'ça', 'décoiffe', 'hein']
re.compile
On notera enfin la présence de la fonction re.compile qui permet de créer un objet regex.
Cette fonction reçoit l’expression rationnelle sous forme d’une chaîne et renvoie un objet avec des méthodes fullmatch, search, finditer, split, etc.
Cela peut être plus pratique si l’on est amené à réutiliser plusieurs fois une même expression.
>>> pattern = re.compile('[0-9]+')
>>> pattern.findall('3 + 5 = 8')
['3', '5', '8']
>>> pattern.sub('?', '3 + 5 = 8')
'? + ? = ?'
Syntaxe des regex
Maintenant que nous connaissons les fonctions du module, voyons voir quelques autres éléments de syntaxe des regex.
Chaînes brutes (raw strings)
Il est d’usage, pour représenter des expressions rationnelles, de ne pas utiliser des chaînes de caractères telles quelles mais d’utiliser ce qu’on appelle des chaînes brutes (ou raw strings).
On les reconnaît au caractère r qui les préfixe.
>>> r'abc'
'abc'
Celles-ci ne forment pas un type particulier, on voit d’ailleurs que l’objet évalué est une chaîne de caractère tout à fait normale.
Non la différence se trouve au niveau de l’analyse de l’entrée par l’interpréteur, la façon dont il interprète les caractères écrits pour former l’objet str.
On le sait, les chaînes de caractères permettent d’utiliser des séquences d’échappement telles que \t ou \n pour représenter des caractères spéciaux.
>>> print('abc\tdef\nghi')
abc def
ghi
Ce comportement est rendu possible par l’interpréteur qui quand il lit la séquence de caractères \t dans le code la transforme en caractère « tabulation ».
Mais il ne le fait pas pour les chaînes brutes, qui conservent alors toutes les séquences d’échappement sans les interpréter comme des caractères spéciaux.
>>> print(r'abc\tdef\nghi')
abc\tdef\nghi
Pour les regex, on préfère ainsi utiliser des chaînes brutes pour ne pas générer de conflits avec des motifs qui pourraient être interprétés comme des séquences d’échappement.
>>> re.fullmatch(r'[0-9]+', '1234')
<re.Match object; span=(0, 4), match='1234'>
Syntaxe des motifs
On a déjà vu de nombreux motifs dans le début du chapitre, mais laissez-moi ici vous les présenter de façon plus détaillée.
Échappement (\)
L’antislash utilisé devant un caractère spécial du motif permet de lui faire perdre son aspect spécial et de l’utiliser comme un caractère normal. \+ identifie le caractère +.
>>> re.match(r'\.\+\$', '.+$')
<re.Match object; span=(0, 3), match='.+$'>
>>> re.match(r'\.\+\$', 'toto')
>>> re.match(r'.+$', 'toto')
<re.Match object; span=(0, 4), match='toto'>
Joker (.)
. est le caractère joker, il correspond à n’importe quel caractère du texte (hors retours à la ligne).
Il correspond toujours à un et un seul caractère.
>>> re.match(r'.', 'a')
<re.Match object; span=(0, 1), match='a'>
>>> re.match(r'.', '@')
<re.Match object; span=(0, 1), match='@'>
>>> re.match(r'.', '')
>>> re.match(r'.', 'ab')
<re.Match object; span=(0, 1), match='a'>
Par défaut, le caractère de retour à la ligne (\n) n’est pas reconnu par ce motif mais on verra avec l’option DOTALL comment y remédier.
>>> re.match(r'.', '\n')
Classes de caractères ([...])
Les crochets identifient les classes de caractères, une classe pouvant alors correspondre à n’importe lequel des caractères qu’elle contient. [abc] pourra correspondre aux caractères a, b ou c (toujours un et un seul).
Il est possible de préciser dans cette classe des intervalles de chiffres ou de lettres à l’aide d’un tiret (-).
[0-9] identifie ainsi un chiffre et [0-0A-Za-z] un caractère alphanumérique.
Pour contenir le caractère - en lui-même, il est possible de l’échapper (le précéder d’un \) ou le placer au tout début ou à la fin de la classe : [0-91-Za-z_-] identifie un caractère alphanumérique, un caractère de soulignement (_) ou un tiret (-).
Un ^ placé en début de classe fait office de négation, ainsi la classe [^0-9] reconnaît les caractères qui ne sont pas des chiffres.
Les autres symboles que nous avons pu voir perdent leur signification spéciale à l’intérieur d’une classe de caractères.
Seul le caractère ] a besoin d’être échappé pour éviter de fermer la classe prématurément.
Quantificateurs (?, +, *, {...})
Les quantificateurs sont différents symboles qui s’appliquent au motif qui précède afin d’en préciser la quantité attendue.
?rend le motif optionnel. Il s’agit alors d’un quantificateur 0 ou 1 fois.+permet de répéter le motif. Il s’agit alors d’un quantificateur 1 fois ou plus.*est un quantificateur 0 ou plus, il combine alors?et+.
Les accolades ({...}) permettent d’appliquer un quantificateur personnalisé au motif qui précède.
On précise à l’intérieur de ces accolades le nombre de répétitions voulues, ou l’intervalle de répétitions acceptées (sous forme de deux nombres séparés d’une virgule).
Par exemple x{3} identifie la chaîne xxx et x{2,4} correspond aux chaînes xx, xxx et xxxx.
Il est possible d’omettre l’une ou l’autre des bornes de l’intervalle. {,n} sera alors équivalent à {0,n} et {n,} signifiera un motif répété au moins n fois.
Groupes ((...))
Les parenthèses permettent de prioriser une sous-expression mais aussi de former un groupe de capture.
Lors d’un appel valide à re.fullmatch par exemple, l’objet re.Match renvoyé donne accès aux différentes valeurs des groupes capturés.
Chaque groupe est identifié par un nombre correspondant à sa position dans l’expression, et le groupe 0 correspond à la chaîne entière.
>>> match = re.fullmatch('([0-9]+)\+([0-9]+)=([0-9]+)', '13+25=38')
>>> match[0]
'13+25=38'
>>> match[1]
'13'
>>> match[2]
'25'
>>> match[3]
'38'
L’objet re.Match possède aussi une méthode groups pour renvoyer tous les groupes capturés dans le texte.
>>> match.groups()
('13', '25', '38')
Pour bénéficier de la priorisation des parenthèses sans créer de groupe de capture, il est possible d’utiliser un ?: à l’intérieur des parenthèses ((?:...)), Python comprendra alors que ces parenthèses ne correspondent pas à un groupe.
>>> re.fullmatch('(ab)+', 'ababab')
<re.Match object; span=(0, 6), match='ababab'>
>>> _.groups()
('ab',)
>>> re.fullmatch('(?:ab)+', 'ababab')
<re.Match object; span=(0, 6), match='ababab'>
>>> _.groups()
()
Unions (|)
Les quantificateurs nous permettent de représenter un choix entre plusieurs alternatives suivant le nombre de fois qu’un motif est répété. Cette notion de choix est au cœur des automates finis puisqu’ils représentent les différents chemins qui partent d’un même nœud.
Pour représenter un choix simple, on utilise l’opérateur d’union (|), celui-ci offrant deux possibilités pour évaluer la chaîne : soit le motif de gauche, soit celui de droite.
Ainsi l’expression ab|cd correspond aux deux chaînes 'ab' et 'cd'.
>>> re.fullmatch(r'ab|cd', 'ab')
<re.Match object; span=(0, 2), match='ab'>
>>> re.fullmatch(r'ab|cd', 'cd')
<re.Match object; span=(0, 2), match='cd'>
>>> re.fullmatch(r'ab|cd', 'abcd')
L’opérateur d’union a une priorité plus faible que l’ensemble des autres opérateurs, à l’exception des parenthèses qui permettent donc de prioriser une union.
L’expression a(b|c)d correspond alors aux chaînes 'abd' et 'acd'.
>>> re.fullmatch(r'a(b|c)d', 'abd')
<re.Match object; span=(0, 3), match='abd'>
>>> re.fullmatch(r'a(b|c)d', 'acd')
<re.Match object; span=(0, 3), match='acd'>
>>> re.fullmatch(r'a(b|c)d', 'ab')
Un quantificateur peut évidemment être appliqué à une union, deux choix possibles seront alors à opérer à chaque répétition du motif.
(ab|ba)+ représente une chaîne comprenant une suite de mots ab ou ba.
>>> re.fullmatch('(ab|ba)+', 'ababab')
<re.Match object; span=(0, 6), match='ababab'>
>>> re.fullmatch('(ab|ba)+', 'baba')
<re.Match object; span=(0, 4), match='baba'>
>>> re.fullmatch('(ab|ba)+', 'abba')
<re.Match object; span=(0, 4), match='abba'>
>>> re.fullmatch('(ab|ba)+', 'abbb')
Enfin, il est possible d’utiliser plusieurs | successifs pour représenter un choix entre plus de deux motifs.
ab|bc|cd identifie le motif ab, bc ou cd.
<re.Match object; span=(0, 2), match='ab'>
>>> re.fullmatch('ab|bc|cd', 'bc')
<re.Match object; span=(0, 2), match='bc'>
>>> re.fullmatch('ab|bc|cd', 'cd')
<re.Match object; span=(0, 2), match='cd'>
>>> re.fullmatch('ab|bc|cd', 'ac')
On note que les unions permettent de représenter différemment des motifs que l’on connaissait déjà.
Par exemple X|XY est équivalent à XY? et a|b|c est équivalent à [abc].
Marqueurs d’extrémités (^ et $)
Les caractères ^ et $ permettent respectivement d’identifier le début et la fin du texte (ou de la ligne suivant le mode, voir les options plus bas).
Ces marqueurs n’ont pas d’intérêt avec re.fullmatch qui les ajoute implicitement mais s’avèrent utiles pour les autres fonctions du module.
Un motif débutant par ^ indique qu’il doit se trouver au début du texte, tandis qu’un motif se terminant par $ indique qu’il doit se trouver à la fin du texte.
>>> re.search(r'^a', 'bac')
>>> re.search(r'^a', 'abc')
<re.Match object; span=(0, 1), match='a'>
>>> re.search(r'a$', 'bac')
>>> re.search(r'a$', 'bca')
<re.Match object; span=(2, 3), match='a'>
Ces marqueurs sont moins prioritaires que l’union, il est donc parfaitement possible par exemple de représenter l’ensemble des chaînes qui commencent par « zeste » ou terminent par « savoir » avec ^zeste|savoir$.
>>> re.search(r'^zeste|savoir$', 'zeste de savoir')
<re.Match object; span=(0, 5), match='zeste'>
>>> re.search(r'^zeste|savoir$', 'concentré de savoir')
<re.Match object; span=(13, 19), match='savoir'>
>>> re.search(r'^zeste|savoir$', 'zeste de citron')
<re.Match object; span=(0, 5), match='zeste'>
>>> re.search(r'^zeste|savoir$', 'concentré de citron')
On remarque que lorsque les deux motifs d’une union correspondent au texte, c’est celui de gauche qui l’emporte (« zeste de savoir » matche sur ^zeste avant savoir$).
Séquences spéciales
On trouve aussi quelques séquences d’échappement particulières pour représenter facilement certaines classes de caractères.
Ainsi, \d identifie un chiffre (à la manière de [0-9] mais en plus large car identifie tous les caractères reconnus comme tels par le standard Unicode).
>>> re.fullmatch(r'\d+', '123')
<re.Match object; span=(0, 3), match='123'>
>>> re.fullmatch(r'\d+', 'abc')
>>> re.fullmatch(r'\d+', '١٢٣')
<re.Match object; span=(0, 3), match='١٢٣'>
À l’inverse, \D identifie ce qui n’est pas un chiffre.
>>> re.fullmatch(r'\D+', '123')
>>> re.fullmatch(r'\D+', 'abc')
<re.Match object; span=(0, 3), match='abc'>
La séquence \w correspond aux caractères alphanumériques unicodes (chiffres, lettres et caractères de soulignement comme _).
Là encore, \W (notez la majuscule) identifie le motif inverse, soit les caractères non alphanumériques.
>>> re.fullmatch(r'\w+', 'Ab_12')
<re.Match object; span=(0, 5), match='Ab_12'>
>>> re.fullmatch(r'\w+', 'Àƀ_١٢')
<re.Match object; span=(0, 5), match='Àƀ_١٢'>
>>> re.fullmatch(r'\w+', '.?')
>>> re.fullmatch(r'\W+', '.?')
<re.Match object; span=(0, 2), match='.?'>
La séquence \s identifie un caractère d’espacement, et \S un caractère qui n’est pas un espacement.
>>> re.fullmatch(r'\s', ' ')
<re.Match object; span=(0, 1), match=' '>
>>> re.fullmatch(r'\s', '\n')
<re.Match object; span=(0, 1), match='\n'>
>>> re.fullmatch(r'\s', '\t')
<re.Match object; span=(0, 1), match='\t'>
>>> re.fullmatch(r'\s', 'x')
>>> re.fullmatch(r'\S', 'x')
<re.Match object; span=(0, 1), match='x'>
Motif de remplacement
Nous avons vu la fonction re.sub qui permet de trouver et remplacer toutes les occurrences d’un motif dans un texte.
La chaîne de remplacement passée à sub peut elle aussi contenir des séquences spéciales, pour faire référence aux groupes capturés dans le texte.
Ainsi \1 dans la chaîne de remplacement correspondra au premier groupe capturé, \2 au second, etc.
>>> re.sub(r'([0-9]+)', r'-\1', '3 + 5 = 8')
'-3 + -5 = -8'
Il est aussi possible d’utiliser la syntaxe \g<N> selon vos préférences.
>>> re.sub(r'([0-9]+)', r'-\g<1>', '3 + 5 = 8')
'-3 + -5 = -8'
D’autres motifs et séquences d’échappement ne sont pas abordés ici et je vous invite à les retrouver dans la documentation du mode re.
Quelques exercices
Je vous propose maintenant de nous entraîner à construire des regex pour résoudre différents problèmes.
Pour vous aider, vous pouvez utiliser des sites web tels que regex101 ou regexr afin de tester et voir en temps réel comment sont interprétées vos regex.
Reconnaître un nombre pair
On veut ici identifier un nombre pair (en représentation décimale).
Qu’est-ce qu’un nombre pair ? Un nombre qui se termine par un chiffre pair.
Afficher/Masquer le contenu masqué
>>> pattern = re.compile(r'[+-]?[0-9]*[02468]')
>>> pattern.fullmatch('42')
<re.Match object; span=(0, 2), match='42'>
>>> pattern.fullmatch('-108')
<re.Match object; span=(0, 4), match='-108'>
>>> pattern.fullmatch('0')
<re.Match object; span=(0, 1), match='0'>
>>> pattern.fullmatch('17')
>>> pattern.fullmatch('abc')
Reconnaître un identifiant Python
On sait qu’un identifiant (nom de variable ou fonction) en Python est composé de lettres, de chiffres et de caractères _, et que le premier caractère ne peut pas être un chiffre.
Afficher/Masquer le contenu masqué
>>> pattern = re.compile(r'[a-z_][a-z0-9_]*', re.IGNORECASE)
>>> pattern.fullmatch('foo')
<re.Match object; span=(0, 3), match='foo'>
>>> pattern.fullmatch('BAR')
<re.Match object; span=(0, 3), match='BAR'>
>>> pattern.fullmatch('item1')
<re.Match object; span=(0, 5), match='item1'>
>>> pattern.fullmatch('1item')
Cette solution ne reconnaît cependant pas certains identifiants valides comme prénom, mais nous ne souhaitons pas traiter ce cas ici comme ce nom n’est pas recommandé en Python.
>>> pattern.fullmatch('prénom')
Découper les mots d’une chaîne
Nous voulons maintenant découper tous les mots d’une chaîne de caractère, en considérant les mots comme des suites de lettres/chiffres et en ignorant tout le reste.
Afficher/Masquer le contenu masqué
On serait tenté d’utiliser la méthode findall avec une regex r'\w+' mais \w ne reconnaît pas seulement les chiffres et les lettres, il inclut aussi le caractère de soulignement (_).
>>> pattern = re.compile(r'\w+')
>>> pattern.findall("Et sous la pluie _I feel sorry_")
['Et', 'sous', 'la', 'pluie', '_I', 'feel', 'sorry_']
On peut alors penser à une regex du genre r'[a-zA-Z0-9]+ mais on perdrait l’usage des caractères accentués.
Au final la meilleure solution est de prendre le problème à l’envers : on veut exclure tous les caractères qui ne sont ni des chiffres ni des lettres. On sait que \W identifie tout ce qui n’est pas chiffre/lettre/underscore, il suffit alors d’ajouter explicitement le _ et de prendre la négation (avec ^) de la classe de caractères.
On trouve ainsi r'[^\W_]+'.
>>> pattern = re.compile(r'[^\W_]+')
>>> pattern.findall("Et sous la pluie _I feel sorry_")
['Et', 'sous', 'la', 'pluie', 'I', 'feel', 'sorry']
>>> pattern.findall("Adieu l'Émile je t'aimais bien.")
['Adieu', 'l', 'Émile', 'je', 't', 'aimais', 'bien']
>>> pattern.findall("Regarde ta montre il est déjà 8h !")
['Regarde', 'ta', 'montre', 'il', 'est', 'déjà', '8h']
Mettre des mots en évidence
Ensuite on aimerait passer en majuscules tous les mots (lettres/chiffres/underscores) contenant la lettre « t » dans un texte.
Afficher/Masquer le contenu masqué
>>> def upperize(match_obj):
... return match_obj[0].upper()
...
>>> pattern = re.compile(r'\w*[tT]\w*')
>>> pattern.sub(upperize, "Quand tu traverses la pièce, en silence que tu passes devant moi")
'Quand TU TRAVERSES la pièce, en silence que TU passes DEVANT moi'
Identifier un palindrome
Enfin on voudrait utiliser une regex pour reconnaître un palindrome, c’est-à-dire un mot qui peut se lire dans les deux sens comme « ressasser ».
Vous ne trouvez pas ? C’est normal : les regex ne disposant pas de mémoire, il n’est pas possible de se souvenir du début de la chaîne quand on en analyse la fin. Nous verrons cela plus en détails dans les limitations des regex.
Options
Les fonctions de recherche du module re acceptent un argument flags qui permet de préciser des options sur la recherche, que je vais vous décrire ici.
re.IGNORECASE (ou re.I)
Cette option permet simplement d’ignorer la casse des caractères de la chaîne à analyser, ainsi le motif ne fera pas de différence entre caractères en minuscules ou en capitales.
>>> re.match('[a-z]+', 'ToTo', re.IGNORECASE)
<re.Match object; span=(0, 4), match='ToTo'>
>>> re.match('[a-z]+', 'ToTo')
re.ASCII (re.A)
Par défaut les regex en Python expriment des motifs unicode, c’est-à-dire qu’elles gèrent les caractères accentués et spéciaux.
Comme on l’a vu, le motif \w permet par exemple de reconnaître des chiffres et des lettres quelle que soit leur forme (différents alphabets, différents diacritiques).
Mais il est possible de restreindre ces motifs à la seule table des caractères ASCII (cf le tableau dans le chapitre dédié aux bytes) avec l’option ASCII et ainsi n’accepter par exemple que les lettres de l’alphabet latin.
>>> re.match('\w+', 'été', re.ASCII)
>>> re.match('\w+', 'ete', re.ASCII)
<re.Match object; span=(0, 3), match='ete'>
>>> re.match('\w+', 'été')
<re.Match object; span=(0, 3), match='été'>
re.DOTALL (re.S)
On a vu précédemment que le motif joker (.) ne reconnaissait pas le caractère de retour à la ligne dans le mode par défaut.
Il est possible de changer ce comportement à l’aide de l’option DOTALL.
>>> re.match(r'.', '\n', re.DOTALL)
<re.Match object; span=(0, 1), match='\n'>
>>> re.match(r'.', '\n')
re.MULTILINE (re.M)
Enfin, l’option MULTILINE est une option qui permet de gérer différemment les textes sur plusieurs lignes.
Par défaut, une chaîne de caractères contenant des retours à la ligne (\n) est gérée comme les autres chaînes, sans traitement particulier pour les sauts de ligne.
Cette option permet de différencier les lignes les unes des autres et d’avoir un traitement adapté.
Ainsi les marqueurs ^ et $ n’identifieront plus seulement le début et la fin du texte mais aussi le début et la fin de chaque ligne.
>>> re.findall(r'^.+$', 'abc\ndef\nghi', re.MULTILINE)
['abc', 'def', 'ghi']
>>> re.findall(r'^.+$', 'abc\ndef\nghi')
[]
Le traitement n’est pas le même qu’avec l’option DOTALL qui elle ne reconnaît simplement pas les sauts de ligne comme des caractères spéciaux.
>>> re.findall(r'^.+$', 'abc\ndef\nghi', re.DOTALL)
['abc\ndef\nghi']
Composition d’options
Les options ne sont pas exclusives et peuvent être composées les unes avec les autres.
On utilise pour cela la notation d’union afin d’assembler différentes options entre elles.
>>> re.findall(r'^[a-z]\w+', 'abc\nDEF\nghî', re.ASCII | re.MULTILINE | re.IGNORECASE)
['abc', 'DEF', 'gh']
Ainsi le code qui précède permet de faire une recherche ascii multiligne ignorant la casse.
On pourra bien sûr enregistrer ces options dans une variable si on est amenés à les réutiliser.
>>> flags = re.ASCII | re.IGNORECASE
>>> re.fullmatch(r'zds_\w+', 'zds_foo', flags)
<re.Match object; span=(0, 7), match='zds_foo'>
>>> re.fullmatch(r'zds_\w+', 'ZDS_BAR', flags)
<re.Match object; span=(0, 7), match='ZDS_BAR'>
>>> re.fullmatch(r'zds_\w+', 'zds_été', flags)
L’ordre des opérandes autour des | n’a pas d’importance, puisqu’il s’agit d’une union de tous les éléments.
On remarque d’ailleurs que l’ordre n’est pas conservé dans le résultat de l’union.
>>> re.MULTILINE | re.ASCII
re.ASCII|re.MULTILINE
Limitations
De par leur construction (automates finis) les expressions rationnelles sont normalement assez limitées en raison de l’absence de mémorisation : elles ne permettent de reconnaître que des langages rationnels.
Il s’agit du type de langage le plus simple dans la hiérarchie de Chomsky, on ne peut pas les utiliser pour décrire des structures récursives par exemple.
Mais le moteur de regex de Python permet d’aller au-delà de certaines limitations (au prix de l’efficacité et de la lisibilité) en fournissant des fonctionnalités supplémentaires :
-
Le look-ahead qui permet de regarder ce qui suit une expression.
>>> # trouve toutes les lettres suivies d'un "b" >>> re.findall(r'\w(?=b)', 'ab cd eb') ['a', 'e'] >>> # ou celles qui ne sont pas suivies d'une espace >>> re.findall(r'\w(?! )', 'ab cd eb') ['a', 'c', 'e', 'b'] -
Le look-behind pour regarder ce qui précède.
>>> # trouve toutes les lettres précédées d'un "a" >>> re.findall(r'(?<=a)\w', 'ab de ac') ['b', 'c'] >>> # ou celles qui ne sont pas précédées d'une espace >>> re.findall(r'(?<! )\w', 'ab de ac') ['a', 'b', 'e', 'c'] -
Les back-references pour référencer une expression déjà capturée.
>>> # trouve les motifs doublés >>> re.findall(r'(\w+)(\1)', 'toto tutu tati') [('to', 'to'), ('tu', 'tu')] >>> # reconnaît N occurrences de "a" suivies d'un "b" et de N nouvelles occurences de "a" >>> re.fullmatch(r'(a+)b(\1)', 'aba') <re.Match object; span=(0, 3), match='aba'> >>> re.fullmatch(r'(a+)b(\1)', 'aaabaaa') <re.Match object; span=(0, 7), match='aaabaaa'> >>> re.fullmatch(r'(a+)b(\1)', 'abaaa')
Cependant, même avec ces fonctionnalités supplémentaires certaines choses restent impossibles.
Par exemple on ne peut pas écrire de motif pour reconnaître N occurrences de « a » suivies de N occurrences de « b ».
De même qu’une expression arithmétique (3 * (1 + 2 * 5)), par sa nature récursive, ne peut pas être reconnue par une regex, même étendue.
On notera enfin que les fonctionnalités étendues présentées ici ne sont pas standards et ne seront pas reconnues par les moteurs de regex « purs »1, je vous recommande donc de les éviter autant que possible (ainsi que pour des questions de lisibilité et de performances) et de préférer des algorithmes plus classiques pour résoudre vos problèmes complexes.
Pour des informations plus complètes sur les regex en Python, je vous renvoie bien sûr à la documentation du module re.