De nombreux problèmes auxquels on peut être confronté en informatique peuvent être subdivisés en sous-problèmes plus faciles à résoudre. Ce chapitre présente plusieurs cas que l'on peut résoudre efficacement.
- Gagner au jeu du 'Plus ou Moins'
- Dichotomie : Recherche dans un dictionnaire
- Calcul de la complexité
- Trouver un zéro d'une fonction
- Diviser pour régner : exponentiation rapide
Gagner au jeu du 'Plus ou Moins'
Connaissez-vous le jeu du plus ou moins ? Le Sphinx choisit un nombre entre 1 et 100 et le garde secret. Le but du joueur est de déterminer ce nombre avec le moins de tentatives possibles. À chaque proposition fausse, le joueur reçoit une indication "c'est plus" (si le nombre recherché est plus grand) ou "c'est moins".
La solution naïve consiste à énumérer les nombres les uns après les autres, sans utiliser les indications. On commence par 1, puis on poursuit avec 2, etc. Dans le pire des cas, on risque donc de compter jusqu'à 100 (on dira donc que la complexité de cet algorithme est de O(N), N étant le nombre de possibilités). Peut-on faire mieux ?
Imaginons que l'on commence par proposer 50. Quelque soit la réponse du Sphinx, on peut éliminer 50 possibilités :
- si c'est plus que 50, la solution est entre 50 et 100 ;
- si c'est moins, la solution est entre 1 et 50.
Et ainsi de suite. À chaque étape, on réduit donc le nombre de possibilités par deux. Cet algorithme est donc beaucoup plus efficace que le précédent. En effet, dans le pire des cas, sept propositions sont nécessaires (on verra comment calculer ce nombre magique plus tard).
Cet algorithme, qui paraît naturel à utiliser, porte le nom de dichotomie (du grec "couper en deux"). Il peut être utilisé dans de nombreux cas : la recherche d'un mot dans un dictionnaire, trouver la solution d'une équation, etc.
Dichotomie : Recherche dans un dictionnaire
Le dictionnaire peut être représenté sous la forme d'un tableau trié par ordre alphabétique. Pour trouver la définition d'un mot dans le dictionnaire, on utilise l'algorithme de dichotomie :
- on regarde le mot situé au milieu du dictionnaire. En fonction de sa position par rapport au mot cherché, on sait dans quelle moitié continuer la recherche : s'il est plus loin dans la liste alphabétique, il faut chercher dans la première moitié, sinon dans la deuxième ;
- on a à nouveau un demi-dictionnaire dans lequel chercher : on peut encore appliquer la même méthode.
Essayez de l'implémenter dans votre langage préféré avant de regarder la solution.
Nous, on kiffe le PHP :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <?php function find($mot, $dictionnaire, $begin, $end) { if ($begin > $end) return false; $new = floor(($begin + $end) / 2); $cmp = strcmp($dictionnaire[$new], $mot); if ($cmp == 0) return true; else if ($cmp > 0) return find($mot, $dictionnaire, $begin, $new - 1); else return find($mot, $dictionnaire, $new + 1, $end); } // exemple : $dictionnaire = array('chat', 'cheval', 'chien', 'grenouille'); echo find('chien', $dictionnaire, 0, sizeof($dictionnaire) - 1); ?> |
Remarque : pour la recherche dichotomique, on a crucialement besoin de l'accès arbitraire : tout repose sur la possibilité de pouvoir regarder directement "l'élément du milieu". On ne peut donc pas faire de recherche dichotomique sur des listes, même triées. Il existe cependant des structures de données plus évoluées qui permettent de stocker des éléments et de les retrouver aussi rapidement qu'avec une recherche dichotomique.
Calcul de la complexité
L'algorithme de dichotomie a une propriété très intéressante : à chaque étape, on effectue la moitié du travail restant (on élimine la moitié des nombres, ou on se restreint à la moitié du dictionnaire, etc.). Autrement dit, si on double la taille de l'entrée (en passant de 100 à 200, ou en ayant un dictionnaire deux fois plus gros), il suffit d'effectuer une étape de plus.
Pour tous les algorithmes qu'on a vus jusqu'à présent, on peut se demander : "comment augmente le temps d'exécution quand on double la taille de l'entrée ?". Pour un algorithme linéaire (en O(N)), on a vu que si l'on double la taille de l'entrée (par exemple la taille de la liste à parcourir), il fallait effectuer deux fois plus d'opérations. Pour un algorithme quadratique (en O(N2 )), il faut effectuer quatre fois plus d'opérations : (2N)2 = 4N2.
Dans le cas de la dichotomie, il faut effectuer une opération de plus. Cela veut dire que le nombre d'opérations croît très lentement en fonction de l'entrée. En effet, si on continue à doubler l'entrée, on rajoute très peu d'opérations : pour 4 fois l'entrée initiale, deux opérations, pour 8 fois l'entrée initiale, 3 opérations… pour 1024 fois l'entrée initiale, 10 opérations. Si on veut traiter un milliard de fois plus de données, 30 opérations supplémentaires suffisent.
Pour confirmer la lenteur de cette croissance, voici un graphe du nombre d'opérations en fonction de la taille de l'entrée, pour une recherche dichotomique :
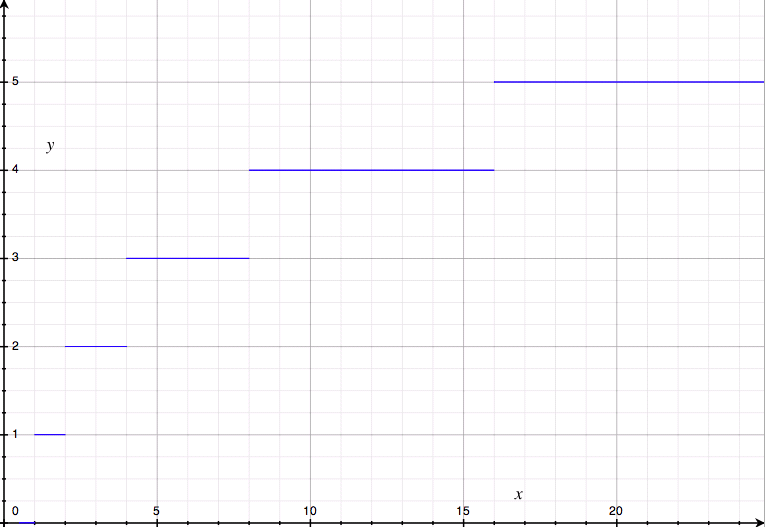
Il se trouve que c'est un comportement relativement courant. On a fait travailler des mathématiciens sur le sujet (toute la nuit, dans une cave, en ne mangeant que des carottes), et ils ont découvert une fonction mathématique qui marche presque pareil, et qui vérifie les deux propriétés qui nous intéressent : f(1) = 0 (quand on a une entrée de taille 1, on n'a aucune opération à faire pour avoir le résultat) et f(2*N) = f(N) + 1 : quand on double la quantité de données à traiter, l'algorithme fait une opération de plus.
Il s'agit de la fonction logarithme. C'est une fonction dont la définition rigoureuse demande un niveau de mathématiques assez avancé, et nous n'essaierons pas de le faire ici. Il suffit de se dire que log(n) correspond au "nombre de fois qu'on doit diviser n par 2 pour obtenir un nombre inférieur ou égal à 1".
Voici le graphe de la fonction logarithme, en rouge par dessus le graphe précédent :
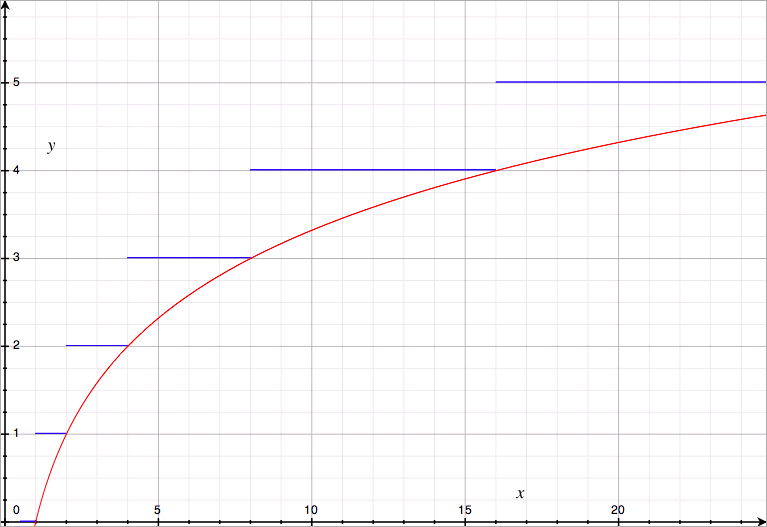
Comme vous pouvez le voir, il "colle" très bien à notre graphe précédent. C'est en général un peu en dessous, mais pas de beaucoup (au plus 1), et surtout la vitesse de croissance est globalement la même : les mathématiciens ont bien travaillé (ils ont été récompensés avec de la purée de carottes).
En réalité, ils ont même fait du zèle : il n'y a pas une seule "fonction logarithme", mais plusieurs. Par exemple il y a une fonction qui ajoute une opération à chaque fois qu'on triple la taille de l'entréee : f(3*N) = f(N) + 1. C'est une autre fonction logarithme qu'on appelle "logarithme en base 3" (et la nôtre, logarithme en base 2). Mais ce n'est pas important parce qu'ils ont prouvé dans la foulée que les différentes fonctions logarithme ne diffèrent que d'une constante multiplicative (quel que soit x, log2 (x) = k * log3 (x) avec k environ 1.58549625) : en termes de complexité, elles sont donc toutes équivalentes, puisqu'en calculant la complexité on néglige les constantes multiplicatives.
On dit donc que la recherche dichotomique a une complexité en O(log N), ou une complexité logarithmique.
Le but n'est pas de vous effrayer avec ces détails mathématiques : si vous les connaissiez déjà ou si vous les comprenez, c'est très bien, mais sinon ce n'est pas grave. L'important est de savoir reconnaître les algorithmes dont la complexité (temporelle ou spatiale - en mémoire) est logarithmique, parce que ce sont généralement de très bons algorithmes : une complexité logarithmique indique un nombre d'opérations qui croît très lentement, donc un algorithme rapide même sur une énorme quantité de données. On pourrait imaginer des complexités encore plus intéressantes, mais en pratique, à part les algorithmes en temps constant, vous ne verrez quasiment jamais mieux que des algorithmes logarithmiques.
Trouver un zéro d'une fonction
Supposons que l'on cherche à trouver une approximation de la racine carrée de 2. Cela revient (par définition de la racine carrée) à chercher la solution positive de l'équation $x^2 = 2$, ou encore $x^2 - 2 = 0$. En posant la fonction $f : x \mapsto x^2 - 2$, on cherche la racine positive de cette fonction, c'est à dire $x$ tel que $f(x) = 0$.
On est donc ramené au problème suivant : étant donné une fonction $f$ connue, dont on sait qu'elle a une racine (elle s'annule quelque part), comment obtenir une bonne approximation de la racine ?
Pour y parvenir, on choisit un intervalle [a;b] qui contient la solution (par exemple l'intervalle [0; 2]).
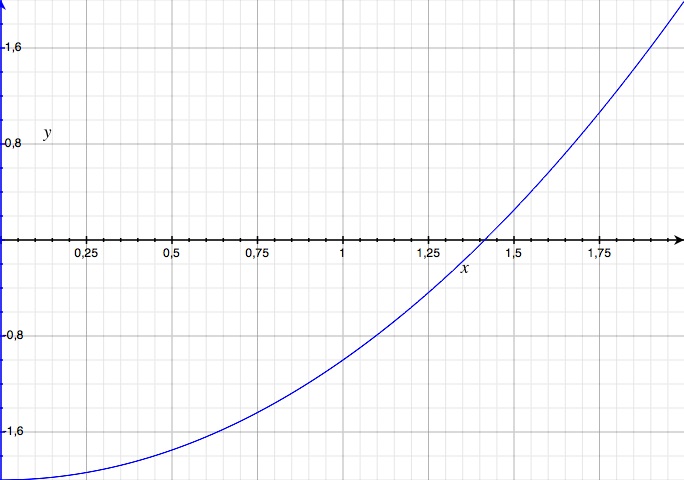
On constate que f(0) est négatif et que f(2) est positif. Comme notre fonction est continue, l'équation f(x) = 0 possède nécessairement une solution entre 0 et 2. En utilisant la dichotomie, on peut réduire l'intervalle et donc améliorer la qualité de l'approximation.
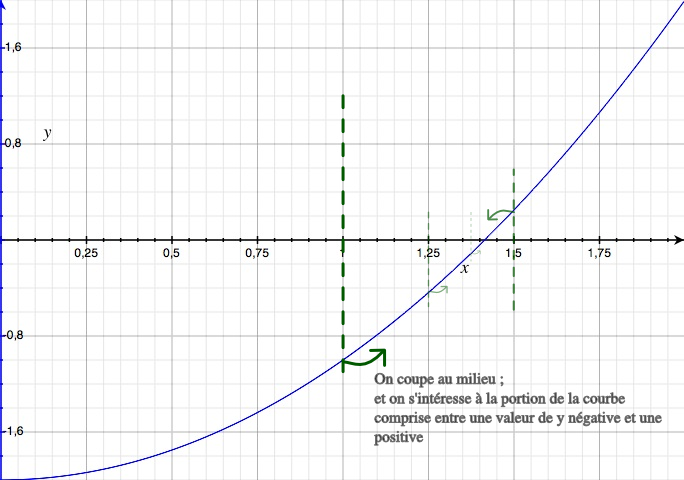
Comme pour la recherche d'un mot dans le dictionnaire, on sélectionne une nouvelle valeur m positionnée au milieu de l'intervalle [a;b]. Si f(m) est positif, on peut en déduire que la solution est comprise dans l'intervalle [a;m]; sinon, elle se trouve dans l'intervalle [m; b].
On a donc réduit l'intervalle initial de moitié, affinant ainsi la qualité de l'approximation. On continue de la sorte jusqu'à ce que la taille de l'intervalle soit considérée comme suffisamment petite.
Voici une mise en pratique, en PHP :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <?php function f($x) { return pow($x, 2) - 2; } function find_zero($a, $b, $erreur) { if (($b - $a) < $erreur) return array($a, $b); $m = ($a + $b) / 2; if (f($a) * f($m) < 0) return find_zero($a, $m, $erreur); else return find_zero($m, $b, $erreur); } // exemple : echo '<pre>'; print_r(find_zero(0, 2, 0.0001)); echo '</pre>'; ?> |
Le principe de la dichotomie est toujours le même : on divise notre problème en deux parties, et on en élimine une. La différence principale avec les codes précédents se trouve dans le test qui permet de décider si on reste dans l'intervalle [a; m] ou [m; b]. Dans le cas où f(a) et f(b) sont tous les deux positifs ou tous les deux négatifs, le produit des deux sera positif. Dans le cas où les deux valeurs ont un signe opposé, le produit sera négatif, et cela nous assure que le zéro se trouve dans cet intervalle.
Si vous n'êtes toujours pas convaincu, voici un tableau explicitant les différents cas possibles qui permet de justifier la condition que nous avons utilisée :
|
Signe de f(\$a) |
Signe de f(\$b) |
Signe de f(\$a)*f(\$b) |
|---|---|---|
|
+ |
+ |
+ |
|
- |
- |
+ |
|
- |
+ |
- |
|
+ |
- |
- |
Il existe d'autres méthodes pour rechercher les 'zéros de fonctions' (c'est-à-dire les points où les fonctions s'annulent), certaines étant encore plus efficaces dans des cas spécifiques. Cependant, la recherche dichotomique est une très bonne base parce qu'elle marche sur n'importe quelle fonction continue (si on connaît deux points dont les valeurs sont de signes opposés) et que le gain de précision est "garanti" : on sait précisément quelle approximation on aura au bout de N étapes (et c'est L/2N , où L est la longueur de l'intervalle de recherche initial).
Diviser pour régner : exponentiation rapide
La dichotomie n'est pas le seul exemple d'algorithme qui découpe les données pour les traiter séparément. La méthode générale est appelée "diviser pour régner" (ou parfois en anglais "divide and conquer", en référence aux souverains qui pensaient que séparer leurs sujets en groupes bien distincts permettait de les gouverner plus facilement - cela évitait, par exemple, qu'ils se regroupent pour demander des augmentations de salaire, ou ce genre de choses gênantes). Il est important de noter que ces algorithmes ne font pas qu'éliminer, comme la dichotomie, une partie des données, mais qu'ils peuvent profiter de la subdivison pour effectuer moins de calculs.
On peut mettre en application cette idée de façon très astucieuse pour calculer les puissances d'un nombre. Pour ceux qui ne seraient pas au courant, x à la puissance n, noté xn, vaut x multiplié par lui-même n fois : x * x * … * x , avec n termes 'x', et x0 vaut 1 (c'est une convention naturelle et pratique). Cette opération est très utile, par exemple si on se demande "quelle est la quantité de nombres différents qui ont au plus 3 chiffres ?" : la réponse est 103 ; de 0 à 999, il y a 103 = 10 * 10 * 10 = 1000 nombres.
Avec cette définition, comment calculer x8 ? Il est évident qu'une bonne réponse est : (x * x * x * x * x * x * x * x). Si l'on demande à l'ordinateur de calculer ça, il va effectuer 7 multiplications (vous pouvez compter). Plus généralement, on peut calculer xn en effectuant n-1 multiplications : c'est un algorithme linéaire, en O(n).
Exercice : implémentez cette méthode simple de calcul de la puissance d'un nombre.
Cependant, on peut faire mieux, en remarquant que x8 = x4 * x4 : si l'on calcule x4 (avec la méthode simple, x4 = x * x * x * x, cela fait 3 multiplications), il suffit de le multiplier ensuite par lui-même pour obtenir x8, en faisant seulement une opération supplémentaire, soit 4 au total. On peut faire encore mieux en utilisant le fait que x4 = x2 * x2 : on peut calculer x4 en deux multiplications, donc x8 en trois multiplications : c'est beaucoup mieux que les 7 multiplications initiales.
C'est un algorithme de "diviser pour régner", parce qu'en découpant le problème (calcul de x8) en deux sous-problèmes (deux calculs de x4), on s'est rendu compte qu'on avait énormément simplifié la question : il suffit de s'intéresser à un des sous-problèmes et le deuxième tombe avec, puisqu'on peut réutiliser le résultat du premier calcul (en faisant une multiplication supplémentaire). Vous avez peut-être déjà reconnu la configuration qui commence à être familière : pour passer de x4 à x8, donc en doublant la difficulté, il suffit de rajouter une opération (une multiplication) ; il y a du logarithme dans l'air !
Cependant, il reste un problème à résoudre : avec cette bonne idée, on peut calculer facilement x2, x4, x8, x16, x32, etc., mais comment faire pour les nombres qui sont moins "gentils" comme 7, 13 ou 51 ?
Plus généralement, on sait comment réduire efficacement le problème du calcul de xn quand n est pair : on a xn = xn/2 * xn/2. Quand n est impair, la division par 2 donne un reste, cette méthode n'est donc pas utilisable directement. Cependant, il suffit de calculer xn-1 (ce qui est facile puisque si n est impair, alors n-1 est pair), et de multiplier ensuite par x pour obtenir xn :
- x0 = 1 ;
- si n est pair, xn = xn/2 * xn/2 ;
- si n est impair, xn = x(n-1) * x.
Cet algorithme nous permet de calculer récursivement xn en très peu de multiplications. On l'appelle "exponentiation rapide", parce qu'exponentiation veut dire "mise à la puissance", et qu'il est rapide. 
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | <?php function exponentiation_rapide($x, $n) { if ($n == 0) { return 1; } else if ($n % 2 == 0) { $a = exponentiation_rapide($x, $n / 2); return $a * $a; } else { return $x * exponentiation_rapide($x, $n - 1); } } echo exponentiation_rapide(2, 10); ?> |
Une petite remarque sur le code : le cas du milieu, if ($n % 2 ==
0), est le cas important puisque c'est lui qui met en place la "bonne idée" qui permet d'aller plus vite. Ce qui fait qu'il est efficace, c'est qu'on enregistre le résultat de exponentiation_rapide($x, $n /
2) pour le calculer une seule fois. Si l'on avait écrit à la place return exponentiation_rapide($x, $n / 2) * exponentiation_rapide($x,
$n / 2); , notre algorithme aurait fait deux fois le même calcul, tuant complètement l'intérêt de cette méthode : on serait revenu à l'algorithme linéaire expliqué plus tôt, mais codé de façon plus compliquée.
Voyons maintenant sa complexité : on a montré que quand on double n, il suffit de faire une opération de plus : pour les puissances de 2, il suffit de log(n) opérations pour calculer xn. Mais cela ne fonctionne pas pour les nombres impairs : si on double n et qu'on lui ajoute 1, on obtient un nombre impair et il faut faire deux opérations de plus. Mais ce n'est pas grave, car "deux opérations" et "une opération", c'est presque la même chose : cela ne diffère qu'à un coefficient multiplicatif près. Au pire, on fait deux fois plus d'opérations (2*log(n)), mais cela conserve la même complexité : l'algorithme d'exponentiation rapide a une complexité logarithmique (autrement dit, en O(log N)).
Il faut savoir que c'est un algorithme très important parce qu'il apparaît dans des situations très diverses. En effet, on l'utilise ici pour faire des puissances de nombres réels, mais il est beaucoup plus général que ça : on peut l'utiliser sur tout un tas d'objets mathématiques divers (il suffit de pouvoir définir l'opération de "mise à la puissance" sur ces objets), et il permet alors de faire les choses les plus étranges.
Par exemple, si vous connaissez la suite de Fibonacci (ou si vous aimez vous renseigner sur Wikipédia), il existe de nombreux algorithmes permettant de calculer le n-ième terme de cette suite : un de ces algorithmes utilise l'exponentiation rapide, et il est extrêmement efficace (c'est un des plus rapides qui existe, beaucoup plus rapide que le calcul des termes de 1 à n).
Les algorithmes de la forme "diviser pour régner" sont très importants et nous en rencontrerons à plusieurs reprises dans les prochains chapitres.