Les structures de données que nous avons vu jusqu'ici (tableaux, listes, piles, files) sont linéaires, dans le sens où elles stockents les éléments les uns à la suite des autres : on peut les représenter comme des éléments placés sur une ligne, ou des oiseaux sur un fil électrique.
Au bout d'un moment, les oiseaux se lassent de leur fil électrique : chaque oiseau a deux voisins, et c'est assez ennuyeux, pas pratique pour discuter. Ils peuvent s'envoler vers des structures plus complexes, à commencer par les arbres.
- Définition
- Quelques algorithmes sur les arbres
- Parcours en profondeur
- Parcours en largeur
- Comparaison des méthodes de parcours
Définition
Un arbre est une structure constituée de noeuds, qui peuvent avoir des enfants (qui sont d'autres noeuds). Sur l'exemple, le noeud B a pour enfant les noeuds D et E, et est lui-même l'enfant du noeud A.
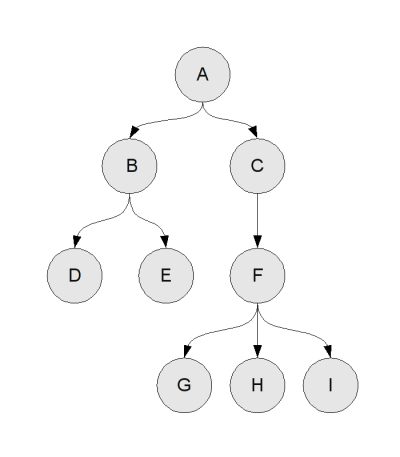
Deux types de noeuds ont un statut particulier : les noeuds qui n'ont aucun enfant, qu'on appelle des feuilles, et un noeud qui n'est l'enfant d'aucun autre noeud, qu'on appelle la racine. Il n'y a forcément qu'une seule racine, sinon cela ferait plusieurs arbres disjoints. Sur l'exemple, A est la racine et D, E, G, H, I sont les feuilles.
Bien sûr, on ne s'intéresse en général pas seulement à la structure de l'arbre (quelle est la racine, où sont les feuilles, combien tel noeud a d'enfants, etc.), mais on veut en général y stocker des informations. On considérera donc des arbres dont chaque noeud contient une valeur (par exemple un entier, ou tout autre valeur représentable par votre langage de programmation préféré).
Comme pour les listes, on peut définir les arbres récursivement : "un arbre est constitué d'une valeur et d'une liste d'arbre (ses enfants)". Vous pouvez remarquer qu'avec cette description, le concept d'"arbre vide" n'existe pas : chaque arbre contient au moins une valeur. C'est un détail, et vous pouvez choisir une autre représentation permettant les arbres vides, de toute manière ce ne sont pas les plus intéressants pour stocker de l'information 
Exercice : essayer de représenter l'arbre donné en exemple dans le langage de votre choix. Vous aurez peut-être besoin de définir une structure ou un type pour les arbres.
Solutions : Solution en C :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #include <stdlib.h> typedef struct arbre Arbre; typedef struct list List; struct arbre { int val; List *enfants; }; struct list { Arbre *node; List *next; }; List *cons(Arbre *arbre, List *liste) { List *elem; if ((elem = malloc(sizeof *elem)) == NULL) return NULL; elem->node = arbre; elem->next = liste; return elem; } int main(void) { Arbre G = {'G', NULL}, H = {'H', NULL}, I = {'I', NULL}; Arbre F = {'F', cons(&G, cons(&H, cons(&I, NULL)))}; Arbre D = {'D', NULL}, E = {'E', NULL}; Arbre C = {'C', cons(&F, NULL)}; Arbre B = {'B', cons(&D, cons(&E, NULL))}; Arbre A = {'A', cons(&B, cons(&C, NULL))}; return 0; } |
L'utilisation de la liste n'est pas très pratique ici : les cons allouent de la mémoire, qu'il faudrait libérer ensuite.
Pour simplifier la situation (les listes chaînées ne sont pas très agréables à manipuler), les programmeurs C utilisent en général une représentation différente. Au lieu de donner à chaque noeud la liste de ses enfants, on lie les enfants entre eux : chaque enfant a un lien vers son frère, et un noeud a donc juste un lien vers le premier de ses fils. Pour parcourir les autres, il suffit ensuite de passer de frère en frère.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | typedef struct arbre Arbre; struct arbre { int val; Arbre *frere; Arbre *enfant; }; int main(void) { Arbre I = {'I', NULL, NULL}; Arbre H = {'H', &I, NULL}; Arbre G = {'G', &H, NULL}; Arbre F = {'F', NULL, &G}; Arbre E = {'E', NULL, NULL}; Arbre D = {'D', &E, NULL}; Arbre C = {'C', NULL, &F}; Arbre B = {'B', &C, &D}; Arbre A = {'A', NULL, &B}; return 0; } |
C'est une manière d'intégrer la liste chainée au sein des noeuds de l'arbre qui la rend plus facile à manipuler en C.
Solution en Caml :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 | type 'a arbre = Arbre of 'a * 'a arbre list let exemple = let feuille lettre = Arbre (lettre, []) in Arbre ("A", [Arbre ("B", [feuille "D"; feuille "E"]); Arbre ("C", [Arbre ("F", [feuille "G"; feuille "H"; feuille "I"])])]) |
Solution en PHP :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <?php function arbre($val, $enfants) { return array('val' => $val, 'enfants' => $enfants); } $arbre = arbre('A', array( arbre('B', array( arbre('D', array()), arbre('E', array()))), arbre('C', array( arbre('F', array( arbre('G', array()), arbre('H', array()), arbre('I', array()))))))); ?> |
Vous pouvez remarquer qu'on a choisi ici d'utiliser un tableau pour stocker les enfants. Dans ce chapitre, nous manipulerons les arbres comme des structures statiques, sans ajouter ou enlever d'enfants à un noeud particulier, donc ça ne sera pas un problème.
Solution en Java :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | class Tree<T> { T val; Tree<T>[] enfants; Tree(T val) { this.val = val; this.enfants = new Tree[0]; } Tree(T val, Tree<T>[] enfants) { this.val = val; this.enfants = enfants; } public static void main(String[] args) { Tree d = new Tree('D'); Tree e = new Tree('E'); Tree g = new Tree('G'); Tree h = new Tree('H'); Tree i = new Tree('I'); Tree[] enfants_de_f = { g, h, i }; Tree f = new Tree('F', enfants_de_f); Tree[] enfants_de_b = { d, e }; Tree b = new Tree('B', enfants_de_b); Tree[] enfants_de_c = { f }; Tree c = new Tree('C', enfants_de_c); Tree[] enfants_de_a = { b , c }; Tree a = new Tree('A', enfants_de_a); System.out.println(a.taille()); } } |
Vous pouvez remarquer qu'on a choisi ici d'utiliser un tableau pour stocker les enfants. Dans ce chapitre, nous manipulerons les arbres comme des structures statiques, sans ajouter ou enlever d'enfants à un noeud particulier, donc ça ne sera pas un problème.
Remarque : on utilise très souvent en informatique des arbres comportant des restrictions supplémentaires : nombre d'enfants, lien entre les enfants et les parents, etc. En particulier les arbres binaires, où chaque noeud a deux enfants au plus, sont très courants. Pour faire la différence on parle parfois d'arbres n-aires pour les arbres généraux que je présente ici, mais le nom n'est pas très bon et je préfère garder "arbre".
Quelques algorithmes sur les arbres
Pour s'habituer à cette nouvelle structure, on va essayer de formuler quelques algorithmes répondant à des questions simples que l'on peut se poser sur des arbres.
Taille
On cherche à savoir combien un arbre contient de noeuds. Le raisonnement est très simple : un arbre, c'est un noeud et la liste de ses fils, donc sa taille est un (le noeud), plus la taille des arbre partant de chaque fils :
1 2 | taille(arbre) = 1 + la somme de la taille des fils |
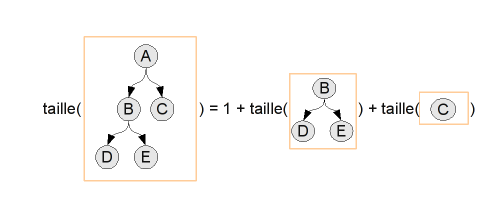
Voici quelques implémentations de cette fonction dans différents langages. N'hésitez pas à essayer de la coder vous-même avant de regarder une solution !
C :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 8 | int taille(Arbre *noeud) { List *enfants; int compteur = 1; for (enfants = noeud->enfants; enfants != NULL; enfants = enfants->next) compteur += taille(enfants->node); return compteur; } |
Ou bien, avec les liens frère-frère :
1 2 3 4 5 6 7 8 | int taille(Arbre *noeud) { Arbre *enfant; int compteur = 1; for (enfant = noeud->enfant; enfant != NULL; enfant = enfant->frere) compteur += taille(enfant); return compteur; } |
OCaml :
Afficher/Masquer le contenu masqué1 2 | let rec taille (Arbre (_, enfants)) = List.fold_left (+) 1 (List.map taille enfants) |
PHP :
Afficher/Masquer le contenu masqué1 2 3 4 5 6 7 8 | <?php function taille($arbre) { $count = 1; foreach($arbre['enfants'] as $enfant) $count += taille($enfant); return $count; }?> |
Java :
Afficher/Masquer le contenu masquéMéthode à rajouter à la classe Tree
1 2 3 4 5 6 | public int taille() { int compteur = 1; for (Tree<?> enfant : enfants) compteur += enfant.taille(); return compteur; } |
Hauteur
On voudrait maintenant connaître la hauteur de l'arbre. La hauteur d'une arbre est la plus grande distance qui sépare un noeud de la racine. La distance d'un noeud à la racine (la hauteur de ce noeud) est le nombre de noeuds sur le chemin entre les deux.
On a l'algorithme suivant :
1 2 | hauteur(arbre) = 1 + la plus grande des hauteurs des fils (ou 0 s'il n'y en a pas) |
Remarque : avec cette définition, la hauteur d'un arbre à un seul élément (juste la racine) est 1; cela ne colle pas vraiment à notre définition de "distance entre le noeud et la racine", puisque la distance de la racine à la racine est logiquement 0. C'est un détail de la définition qui peut changer selon les gens, et qui n'est pas vraiment important de toute façon : on ne fait pas dans la dentelle.
Remarque : on parle parfois de profondeur plutôt que de hauteur : cela dépend de si vous imaginez les arbres avec la racine en haut et les feuilles en bas, ou (ce qui est plus courant dans la nature) la racine en bas et les branches vers le haut.
Liste des éléments
Une dernière question à se poser est "quels sont les éléments présents dans mon arbre ?". Si vous êtes tombés amoureux des listes et des tableaux, vous aimeriez peut-être avoir accès à ces éléments sous forme de liste ou de tableau. Un tableau ne serait pas très pratique ici, parce qu'il faudrait commencer par calculer la taille de l'arbre; je vais plutôt vous demander d'écrire ici l'algorithme pour obtenir la liste des éléments d'un arbre.
Indice : Vous pouvez utiliser deux fonctions sur les listes :
reunir_listes(LL), qui prend une liste de listes et forme une seule liste, la réunion de toutes les petites listes. Par exemple reunir_listes([ [1;3]; []; [2]; [5;1;6] ]) = [1;3;2;5;1;6]. Pour coderreunir_liste, la fonctionconcat(L1,L2)du chapitre précédent, qui met deux listes bout à bout, vous sera utile.- si votre langage le permet, une autre fonction très utile est
map(F, L), qui applique la fonctionFà tous les éléments de la listeLet renvoie la liste résultat; par exemplemap(ajoute_1, [1;5]) = [2;6]. Sinon, si votre langage ne permet pas de passer des fonctions en argument d'une autre fonction, ou si vous ne savez pas le faire, vous n'aurez qu'à le faire à la main.
Remarque : Il existe plusieurs manières de construire la liste des éléments de l'arbre, et on peut obtenir plusieurs listes différentes, avec les mêmes éléments mais placés dans un ordre différent.
Correction : Voici un schéma d'algorithme :
Afficher/Masquer le contenu masqué1 2 3 | liste_elements(arbre) = soit elements_enfants = map(liste_elements, enfants) renvoyer cons(element, reunir_listes(elements_enfants)) |
Parcours en profondeur
Les trois algorithmes précédents visitent l'arbre : ils répondent en interrogeant chaque noeud, un par un. Ils ont un point commun, l'ordre dans lequel ils visitent les noeuds de l'arbre est le même à chaque fois. Cet ordre correspond à une méthode de parcours de l'arbre qu'on appelle le parcours en profondeur; pour chaque noeud :
- on fait quelque chose avec (demander sa valeur, par exemple)
- on parcourt chacun de ses enfants, récursivement
- on fait quelque chose pour réunir les résultats après le parcours (somme, maximum,
reunir_listes)
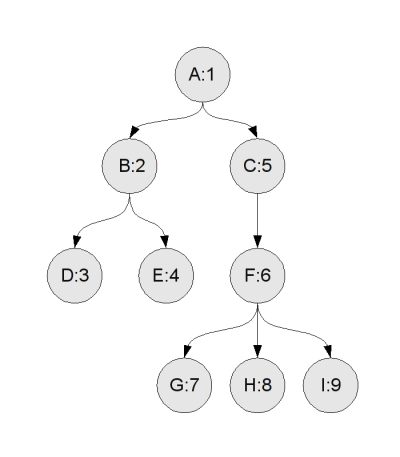
Pourquoi parle-t-on de parcours en profondeur ? Cela vient de l'ordre dans lequel sont parcourus les noeuds. Imaginons un de ces parcours sur l'arbre ci-dessous : on l'appelle sur la racine, A, qui lance le parcours sur chacun de ses enfants, en commençant par B (on suppose que l'ordre des enfants dans la liste est l'ordre de gauche à droite sur le dessin). Pour fournir un résultat, B doit interroger ses propres enfants, donc il commence par lancer le parcours sur son premier fils, D. Ainsi, on voit que le parcours va "en profondeur" en commençant par descendre dans l'arbre le plus possible.
Pour visualiser tout le parcours, on peut numéroter les noeuds dans l'ordre dans lequel ils sont parcourus :
Parcours en largeur
La méthode de parcours en profondeur est simple, mais l'ordre dans lequel les noeuds sont parcourus n'est pas forcément très intuitif. En faisait un peu attention (par exemple en essayant de suivre le parcours du doigt), vous serez capable de vous y habituer, mais on pourrait espérer faire quelque chose qui paraisse plus "naturel" à un humain. Et si, par exemple, on voulait parcourir notre arbre dans l'ordre alphabétique : A, B, C, D, E.. ?
Si cet ordre vous paraît "logique", c'est parce que j'ai nommé mes sommets par "couche" : on commence par la racine (A), puis on donne un nom à tous les noeuds de "première génération" (les enfants de la racine) B et C, puis à tous les noeuds de "deuxième génération" (les enfants des enfants de la racine), etc.
Remarque : l'algorithme de parcours en largeur est un peu plus compliqué que les algorithmes que j'ai présenté jusqu'ici. Si vous avez des difficultés à comprendre ce qui suit, c'est normal. Essayez de bien faire les exercices, de bien relire les parties qui vous posent problème, et n'hésitez pas à aller demander sur les forums d'aide si vous pensez avoir un vrai problème de compréhension. Vous y arriverez, c'est ce qui compte.
En mettant des couches
Je cherche maintenant un algorithme qui permet de parcourir les noeuds "par couche" de la même manière. On appelle ça le parcours en largeur : on parcourt couche par couche, et dans chaque couche on parcourt toute la "largeur" de l'arbre.
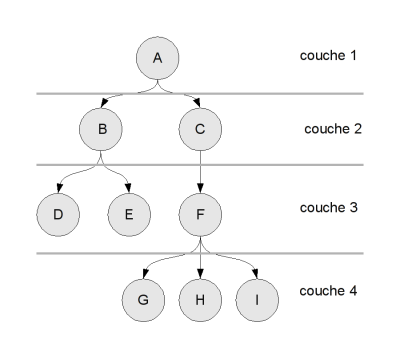
On va partir de l'idée suivante : pour parcourir l'arbre "par couche", il faut essayer de stocker les noeuds dans des couches. Plus précisément, on va maintenir pendant le parcours deux couches : la "couche courante", qui contient les noeuds que l'on est en train de parcourir, et la "couche des enfants", où on met les enfants de la couche courante.
Un peu plus précisément, on a l'algorithme suivant :
- au départ, on met la racine dans la couche courante, on prend une liste vide pour la couche des enfants
- ensuite, on parcours les noeuds de la couche courante, en ajoutant leurs enfants dans la couche des enfants
- quand on a terminé le parcours, on change les couches : on prend la couche des enfants comme nouvelle couche courante, et on recommence le parcours.
Quand, à la fin du parcours de la couche courante, on obtient une couche des enfants vide, l'algorithme s'arrête. En effet, s'il n'y a pas d'enfants dans la couche des enfants, cela veut dire qu'aucun des noeuds de la couche qui vient d'être parcourue n'avaient d'enfants : ce n'était que des feuilles, donc on est arrivé à la fin de l'arbre (dans notre exemple la couche G, H, I).
Remarque : j'ai parlé d'utiliser des "listes" pour représenter les couches. En réalité, on n'utilise vraiment que deux opérations : ajouter un noeud dans une couche, retirer un noeud de la couche (pour le parcours). Les files et les piles sont donc des structures adaptées pour ces opérations (si vous utilisez une simple liste, ça se comportera comme une pile). Le choix d'une file ou d'une pile va changer l'ordre dans lequel les sommets sont parcourus, mais la propriété du parcours en largeur est évidemment conservée dans les deux cas : les noeuds près de la racine sont toujours parcourus avant les noeuds plus loin de la racine, et c'est ce qui est important ici.
Exercice : mettre en place l'algorithme avec le noeud donné en exemple (mettre la lettre 'A' comme valeur du noeud A, et ainsi de suite) : parcourir l'arbre en largeur, en affichant la valeur de chaque noeud rencontré. Essayer avec des files et des piles pour représenter les couches : quelle est la différence ? Vérifier que l'ordre des couches est toujours respecté.
Avec une file
Avec notre algorithme, on stocke les noeuds dans deux structures séparées : les noeuds appartenant à la couche courante, que l'on va bientôt parcourir, et les noeuds de la couche des enfants, que l'on va parcourir plus tard. Est-il possible de conserver ce sens de parcours, en utilisant une seule structure au lieu de deux ?
On peut obtenir une réponse à cette question en considérant les deux structures comme une seule : on considère qu'un noeud "entre" dans nos structures quand on l'ajoute à la couche des enfants, et qu'il en "sort" quand on le prend dans la couche courante pour le parcourir. Pour que notre parcours soit correct, il faut que l'ordre des couches soit respecté : un noeud d'une couche doit entrer avant les noeuds de la couche suivante, et sortir avant tous les noeuds de la couche suivante. Cela correspond donc à une forme de premier entré, premier sorti : première couche entrée, première couche sortie.
Ça ne vous rappelle pas quelque chose ? Normalement, si : premier entré, premier sorti, c'est le comportement des files. On peut donc utiliser une file pour stocker les noeuds, car l'ordre de la file respectera l'ordre des couches.
On obtient donc l'algorithme suivant :
- au départ, on commence avec une file vide, dans laquelle on ajoute la racine
- tant que la file n'est pas vide, on enlève le premier noeud de la file, on le parcourt et on ajoute tous ses enfants dans la file.
Exercice : implémenter cet algorithme de parcours, et vérifier que la propriété de parcours en largeur est bien respectée.
Comparaison des méthodes de parcours
Remarque : les programmeurs utilisent souvent la terminologie anglosaxonne pour décrire ces parcours : on parle de DFS (Depth First Search, parcours en profondeur d'abord) et de BFS (Breadth first search, parcours en largeur d'abord).
Une symétrie assez surprenante
Vous avez sûrement remarqué que les files et les piles sont des structures très proches, qui proposent le même genre d'opérations (ajouter et enlever des éléments). Il est donc naturel de se demander : que se passe-t-il quand, dans l'algorithme de parcours en largeur avec une file, on remplace la file par une pile ?
On passe alors d'un régime premier entré, premier sorti à un régime dernier entré, premier sorti. Imaginez qu'on vient de parcourir un noeud : on a ajouté tous ses enfants à la pile, et maintenant on passe au noeud suivant à parcourir. Quel est le noeud suivant qui sera pris ? C'est le dernier noeud entré sur la pile, donc un des enfants du noeud précédent. On se retrouve avec un parcours où, quand on a parcouru un noeud, on parcourt ensuite ses enfants. Ça ne vous rappelle rien ? Si (ou alors vous n'avez pas été asssez attentif) : c'est le parcours en profondeur !
On peut donc implémenter le parcours en profondeur exactement comme le parcours en largeur, en remplaçant la file par une pile. Cela montre que les deux parcours sont très proches, et qu'il y a des liens très forts entre les algorithmes et les structures de données.
Choix de l'implémentation
Nous avons donc vu deux implémentations de chaque parcours : le parcours en profondeur récursif, le parcours en largeur avec deux couches, le parcours en largeur avec une file et le parcours en profondeur avec une pile. En général, on choisit les algorithmes les plus pratiques : quand on veut faire un parcours en profondeur, on utilise la méthode récursive (qui est plus simple à concevoir et à mettre en oeuvre), et quand on veut faire un parcours en largeur on utilise la méthode avec une file (parce qu'une structure, c'est plus simple que deux). Quand les gens parlent du "parcours en largeur", ils font (quasiment) toujours référence à l'implémentation avec une file.
Il est quand même utile de connaître les autres implémentations. Tout d'abord, la symétrie entre le parcours en largeur à file et le parcours en profondeur à pile est très jolie (obtenir deux algorithmes différents en changeant juste deux fonctions, c'est quand même assez fort). Ensuite, certains langages (dont je pense le plus grand mal) ne supportent pas bien la récursion, dans ce cas le parcours en profondeur avec une pile peut être un bon choix d'implémentation. Enfin, la méthode de parcours en largeur avec deux couches a un avantage : il est facile de savoir à quelle couche appartient un élément, et donc de mesurer sa "distance" au noeud facilement et efficacement. Quand on utilise une file, la distinction entre les deux couches se brouille (on sait que tout arrive dans le bon ordre, mais on ne sait plus exactement où est la coupure entre les couches), et si on a besoin de cette information il faut la maintenir par d'autres méthodes (par exemple en la stockant dans la file avec le noeud, ou dans une structure à part).
Exercice : Implémenter un algorithme de parcours en largeur qui affiche la valeur de chaque noeud, ainsi que la distance de ce noeud à la racine.
Analyse de complexité
Les deux parcours ont une complexité en temps linéaire en la taille de l'arbre (son nombre de noeuds) : en effet, on parcourt chaque noeud une seule fois, et on effectue avant et après quelques opérations (entrée et sortie d'une structure) qui sont en temps constant. Si on a N noeuds dans l'arbre c'est donc du O(N).
Pour ce qui est de la complexité mémoire, il faut faire un peu plus attention. Le parcours en profondeur conserve les chemins par lequel il est "en train de passer". J'ai donné l'exemple du début du parcours où on passe par les noeuds A, C puis D. Vers la fin du parcours, on sera en train de passer par les noeuds A, C, F puis I. Ces noeuds sont bien présents en mémoire : c'est facile à voir dans la version avec une pile, c'est juste le contenu de la pile; c'est aussi le cas dans la version récursive, car chaque paramètre passé à un appel récursif de la fonction doit être conservé quelque part (pour en savoir plus, vous pouvez lire la description de la pile d'appel dans le tutoriel sur la récursivité, mais ce n'est pas un point important ici). La complexité mémoire du parcours en profondeur est donc en O(H), où H est la profondeur maximale des noeuds de l'arbre, c'est à dire la hauteur de l'arbre.
Pour le parcours en largeur, c'est un peu différent : à un instant donné on stocke une partie de la couche courante (ceux qui n'ont pas encore été parcourus), et une partie de la couche des enfants (ceux qui ont déjà été ajoutés). Cela se voit bien dans la version avec deux couches, mais on stocke exactement la même quantité de noeuds dans la version avec pile. La complexité mémoire est donc en O(L) où L est la plus grande largeur d'une couche de l'arbre.
Je parle de O(H) et O(L) ici, mais ça ne vous apporte pas grand chose : un arbre à N éléments, c'est parlant, mais comment avoir une idée des valeurs de H et L ? Si vous ne connaissez pas les arbres qu'on va vous donner, c'est difficile de le savoir. Une approximation pessimiste est de se dire que H et L sont toujours inférieurs à N, le nombre de noeuds de l'arbre. En effet, dans le "pire cas" pour H, chaque noeud a un seul enfant, et sa hauteur est donc N (vous pouvez remarquer que cela correspond exactement à une liste). Dans le "pire cas" pour H, la racine a N-1 enfants, donc H = N-1 = O(N).
On peut donc dire que les complexités mémoires des parcours d'arbres sont en O(N). Si j'ai tenu à vous parler de H et L, c'est parce que dans la plupart des cas on peut avoir des estimations plus précises de leurs valeurs. En particulier, on verra plus tard que H est souvent nettement plus petit que N.
Utilisation en pratique
Dans quels cas utiliser plutôt un parcours ou l'autre ? Le parcours en profondeur est le plus simple à implémenter (par la récursivité), donc si vous avez besoin de parcourir tout l'arbre c'est un bon choix; par exemple, on peut coder la fonction "taille d'un arbre" en utilisant un parcours en largeur (il suffit d'incrémenter un compteur à chaque noeud parcouru), mais c'est nettement plus compliqué (et donc sans doute un peu plus lent) et ça n'apporte rien.
De même, si on veut trouver "tous les noeuds qui vérifient la propriété donnée" (par exemple "leur valeur est supérieure à 100" ou "ils représentent une salle du labyrinthe qui contient un trésor"), les deux méthodes de parcours sont aussi bien, et il vaut mieux utiliser le parcours en profondeur qui est plus simple. Si on cherche "un noeud qui vérifie la propriété donnée", les deux parcours sont tous les deux aussi bien.
Il y a un cas cependant où le parcours en largeur est le bon choix : quand on a besoin de la propriété de "distance à la racine" du parcours en largeur. Pour développer mon exemple précédent, imaginez que l'arbre décrit le plan d'un labyrinthe : l'entrée est à la racine, et quand vous êtes dans la salle correspondant à un noeud, vous pouvez vous rendre dans les salles enfant (ou remonter dans la salle parent). Certains noeuds contiennent des trésors; vous voulez que votre algorithme vous donne, pas la liste des trésors, pas une seule salle qui contient un trésor, mais le trésor le plus proche de l'entrée (qui est aussi la sortie). Alors il faut utiliser un parcours en largeur : il va visiter les cases les plus proches de la racine en premier. Dès que vous aurez trouvé un trésor, vous savez que c'est le trésor le plus proche de l'entrée, ou en tout cas un des trésors les plus proches : il y a peut-être d'autres trésors dans la même couche. Un parcours en profondeur ne permet pas cela : le premier trésor qu'il trouve peut être très profond dans l'arbre, très loin dans la racine (imaginez sur notre exemple qu'il y a un trésor en E et en C).
Pour résumer, le parcours en profondeur est très bien pour répondre aux questions du style "le nombre total de …", "la liste des …", "le plus long chemin qui …", et le parcours en largeur pour les questions du style "le plus court chemin qui ..", "le noeud le plus proche qui …", "la liste des .. en ordre de distance croissante".