
S’il est une question à laquelle j’ai bien du mal à répondre depuis un an, c’est « qu’est-ce que tu fais dans la vie ? ».
Enfin, pas tout à fait, puisqu’à celle-ci je réponds fièrement que je suis release engineer chez Scality. Celle qui me donne du fil à retordre, par contre, est la question qui vient inévitablement ensuite : ça consiste en quoi ?
Que l’on se rassure : je sais très bien en quoi consiste mon travail ! Simplement, il est assez difficile de l’expliquer à n’importe qui en quelques minutes avec les mains, sans risquer de trop simplifier ou de ne pas assez en dire. Ce billet est là pour que je puisse garder sous le coude ma réponse à cette question, celle qui, au-delà de la rapide explication mondaine que personne ne retient jamais, décrit comment je vois mon métier et pourquoi il me plait.
Un "multiplicateur de force"
Pour commencer, j’emprunterai les mots que John O’Duinn (directeur de l’équipe release engineering chez Mozilla) a utilisés dans un Google TechTalk intitulé Release Engineering as Force Multiplier.
Le cas de Mozilla
Mozilla édite le célèbre navigateur web Firefox, qui compte parmi les principaux acteurs du "marché" des navigateurs web sur desktop, comme en atteste cette statistique datant de Décembre 2016 :
| Navigateur | Part d’utilisation |
|---|---|
| Google Chrome | 56.43% |
| Microsoft Internet Explorer | 7.7% |
| Mozilla Firefox | 11.1% |
| Apple Safari | 14.5% |
Maintenant, mettons cette donnée en perspective en examinant l’effectif des entreprises qui éditent ces logiciels :
| Entreprise | Nombre d’employés |
|---|---|
| Google (Alphabet) | 72 053 |
| Microsoft | 120 849 |
| Mozilla Corporation | 1000 |
| Apple | 116 000 |
Ne voyez-vous rien qui choque ? Mozilla est un David qui se bat à armes égales contre des Goliaths 72 à 120 fois plus grands que lui !
Le cas de Scality
On pourrait croire qu’il s’agit d’une simple singularité, et arguer que Firefox est lui-même un logiciel Open Source, donc que les stats précédentes ne tiennent pas compte du nombre réel de développeurs qui travaillent sur les produits, alors permettez-moi de vous montrer ce qu’il en est pour ma propre entreprise, qui édite un logiciel propriétaire de stockage objet distribué. Et commençons par le rapport Gartner d’octobre 2016 sur ce marché :
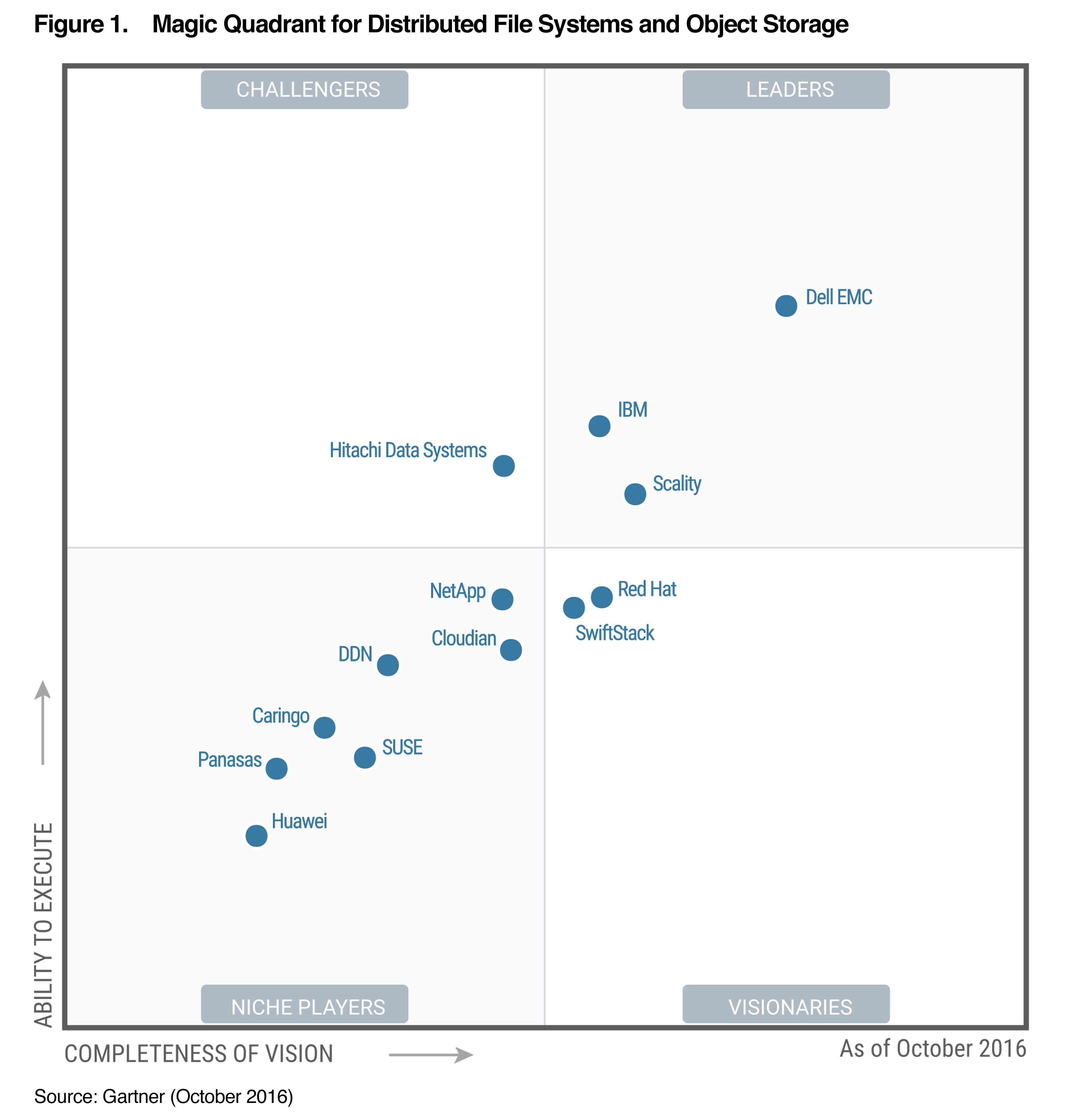
Sans équivoque markéteuse, Scality est l’un des trois leaders de ce marché, face à IBM et Dell EMC. Et en termes d’effectifs ?
| Entreprise | Nombre d’employés |
|---|---|
| Scality | 210 |
| Dell EMC | 70 000 |
| IBM | 377 257 (en 2015) |
Le moins que l’on puisse dire, c’est que Scality est dans une posture similaire à celle de Mozilla sur son marché, face à deux mastodontes qui font 350 à plus de 1000 fois sa taille !
Quel est leur secret ?
Pas de vantardise mal placée : ni les développeurs de Mozilla, ni ceux de Scality ne sont des super-héros. Par contre, ce que ces deux entreprises ont en commun et qui leur permet d’entrer (et rester) en compétition avec des produits portés par des armées d’ingénieurs, c’est une équipe de Release Engineering, dont le rôle principal est d’optimiser la capacité des équipes à livrer un produit de qualité, à un rythme aussi rapide et régulier que possible.
En somme, mon métier consiste à aborder la régularité et la qualité des releases comme un problème d’ingénierie à part entière : l’optimisation du système que constitue l’équipe de développement de mon entreprise. Ce faisant, le release engineering agit comme un levier, un multiplicateur de force, permettant à 10 personnes d’accomplir le travail d’un millier.
Cela n’a rien de nouveau ni de magique. En fait, le siècle précédent a vu le même phénomène se produire à de multiples reprises dans l’industrie, avec en particulier le Fordisme dans les années 1900, et surtout le Toyotisme dans les années 1960.
Voyons un peu comment ça se présente dans la réalité de l’édition de logiciels.
Un cas d'école
Pour bien se rendre compte des tenants et aboutissants de ce métier, examinons un cas d’école inspiré des deux dernières années d’existence de ma société. Encore une fois, je ne prétends pas couvrir la totalité des aspects du métier : ce qui suit est une vue partielle et partiale du Release Engineering. Mais j’estime qu’elle permet de bien sentir le domaine.
Identifions le problème : quand faire appel au RelEng ?
Je l’ai écrit plus haut : le release engineering est un métier d’optimisation. Si vous êtes développeur, vous connaissez probablement cette fameuse phrase que l’on attribue à Donald Knuth : premature optimization is the root of all evil. En ce sens, il ne convient d’optimiser que ce qui est optimisable : si l’optimisation n’a aucun problème à résoudre, alors elle ne sert à rien et risque même de faire plus de mal que de bien.
Pour ce qui est du release engineering, le problème qu’il cherche à résoudre est celui de la qualité et du rythme de sortie d’un logiciel. Ainsi, il convient de l’envisager dans une entreprise qui correspond à un ou plusieurs des critères suivants :
- Qui ne fait pas confiance en la qualité de ses releases, au point qu’une mise en production devient source de stress ;
- Qui subit de grosses irrégularités sur le rythme des sorties, parce que les ingénieurs qui développent le produit préfère attendre d’avoir suffisamment testé le produit pour avoir confiance en sa qualité, quitte à prendre un délai supplémentaire et imprévu par rapport à la date de sortie ;
- Qui a un rythme de livraison trop bas, parce que les nouvelles fonctionnalités prennent un temps démesurément long à intégrer.
C’était complètement le cas de Scality il y a 2 ans : en 2015, l’entreprise n’a sorti qu’une nouvelle version de son produit principal (le Scality Ring), contenant seulement deux nouvelles fonctionnalités par rapport à la version précédente. Ça, c’est ce qu’on appelle une situation problématique, et c’est la raison pour laquelle Scality a monté une équipe RelEng fin 2015.
Pas d’optimisation sans mesure !
Voilà une autre maxime que les ingénieurs expérimentés martellent à tout bout de champ : pour optimiser quelque chose, il faut OBLIGATOIREMENT le mesurer. Il faut savoir que tel bout de code est responsable de la lenteur du programme et qu’il s’exécute en 100ms, pour se donner un objectif à atteindre (par exemple, réduire son temps d’exécution à 20 ou 5ms).
Alors quand il s’agit de code, c’est facile et bien joli : on mesure le temps d’exécution ou la quantité de mémoire consommée par telle ou telle fonction, mais quand on veut optimiser le rythme de parution des nouvelles fonctionnalités d’un produit donné, que diable faut-il mesurer ?
Il n’existe aucune réponse absolue à cette question, mais voici le raisonnement que nous avons tenu dans mon équipe.
L’approche linuxienne : porter la commande top sur la vie réelle
Chez Scality, nous sommes des développeurs. Pire que ça : nous sommes des développeurs système et réseaux. On développe un produit qui tourne sous Linux, principalement en C (avec des petits bouts de Rust), et on le teste avec Python.
En bons linuxiens que nous sommes, si nous voyons qu’un système a des problèmes de performances, on ouvre un terminal et on tape cette commande : top. Ce programme nous donne une vue décortiquée du système, en nous montrant les processus qui consomment le plus de CPU ou de mémoire.
De la même façon, face à un problème de productivité d’une entreprise, nous sommes tentés de taper top dans un terminal… Sauf que ni le terminal, ni la commande top n’existent sur le système que nous sommes en train d’étudier. Dans ces conditions, si nous avons besoin d’un outil comme top pour profiler une équipe d’ingénierie, et qu’il n’existe pas, eh bien qu’à celà ne tienne : construisons notre commande équivalente irltop !
Et c’est métaphoriquement ce que nous avons fait. Nous avons cherché des indicateurs de performances dans les données que nous possédions de notre entreprise (les statistiques de notre outil de tracking et de gestion de tickets), en empruntant notre méthode au Toyotisme des années 1960.
La règle des cinq zéros
Le toyotisme était la méthode de fonctionnement mise en place par Toyota dans ses usines automobiles afin de maximiser ses gains tout en minimisant les coûts de production. L’un des pilliers de cette méthodologie est la règle des cinq zéros :
- Zéro défaut : le produit doit être d’une qualité irréprochable, parce que les problèmes de fabrication sont coûteux à gérer.
- Zéro papier : dématérialiser l’information le plus possible dans l’entreprise.
- Zéro panne : il coûte moins cher de payer des gens pour maintenir la chaîne de production que pour la réparer quand elle tombe en panne.
- Zéro stock et zéro délai : tout ce qui est produit doit être immédiatement facturé à un client. Il ne faut ni sur-produire — car le stockage est une dette, la somme de travail qui ne nous a ramené aucune valeur jusqu’à présent — ni sous-produire — car les délais d’attente sont source de mécontentement pour les clients)
Mais la chaîne de production et le stock, en ingénierie logicielle, à quoi correspondent-ils ?
Les tickets en cours (WIP) sont notre "stock"
Si l’on se fie à la définition du stock donnée plus haut, tout le travail duquel on n’a encore tiré aucune valeur est décrit chez nous dans des tickets (bug, fonctionnalité, amélioration, etc.). Chaque ticket pouvant être dans un de ces trois états :
- Nouveau,
- En cours,
- Fermé.
Si l’on compte le nombre de tickets qui sont dans l’état "En cours", on obtient une mesure relativement fidèle à la quantité de travail que l’on n’a pas encore livré. Voici un graphique qui montre le nombre de tickets en cours chez Scality de sa naissance à fin 2015.
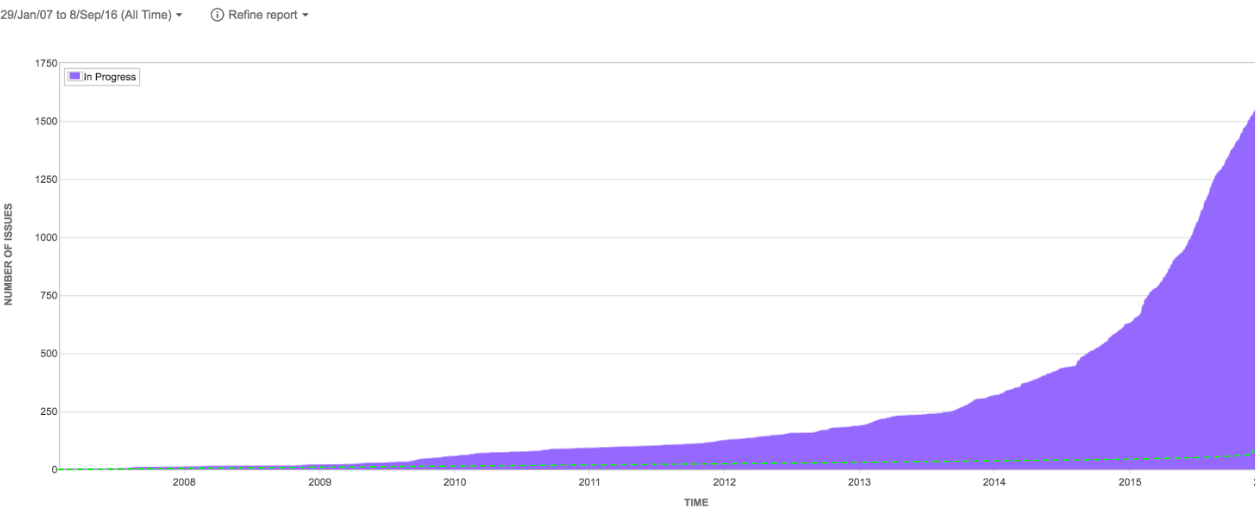
Cela saute aux yeux : le nombre de tickets en cours a grimpé de façon exponentielle, alors que le nombre de développeurs, lui, a simplement augmenté de façon linéaire.
Une telle situation, dans une usine Toyota, ressemblerait à :
- 4000 pneus à l’extérieur de l’usine, à côté d’un tas de 1000 pare-chocs avant,
- 250 voitures à moitié finies qu’on a stockées là parce qu’on attend une pièce pour faire repartir leur ligne de production,
- 170 voitures neuves dans un parking à l’extérieur, qui attendent d’être livrées aux concessionnaires.
Ça y est, nous tenons la métrique que nous cherchons. Celle que nous voulons minimiser dans notre optimisation.
Le bilan actuel
Je ne vais pas entrer dans le détail de la transformation qu’a subie l’entreprise depuis que l’on a commencé à suivre de près ce nombre de tickets en cours. Mais si je devais en résumer les traits marquants :
- Nous avons adopté la philosophie Agile : les ingénieurs travaillent aujourd’hui en suivant une méthode Agile ou une autre, en suivant un cycle d’itérations régulier et court, itérations pendant lesquelles ils développent des fonctionnalités de taille limitée, qui représentent un gain immédiat de valeur ajoutée dans le produit.
- Nous nous efforçons de pratiquer le Continuous Delivery en automatisant le plus de tâches possible, jusqu’à la livraison du logiciel.
- Nous avons formalisé un workflow sur Git, nommé GitWaterFlow, que nous avons présenté fin 2016 à une conférence internationale (article en anglais).
- Nous avons développé (et open-sourcé) Bert-E, un robot "assistant de merge", qui pilote et automatise la plus grosse partie de notre workflow (slides en anglais).
- Nous avons développé (et open-sourcé) Eve, notre système d’intégration continue basé sur le framework BuildBot, afin de passer à l’échelle sur les tests automatisés des produits de l’entreprise (slides en anglais).
Il n’est pas exclu que je consacre d’autres billets à aborder certains de ces points en détail à l’avenir, mais pour l’instant contentons nous de conclure. Toutes ces mesures nous ont aidé à optimiser le rythme de production du produit. Nous sommes passés d’une sortie par an à une nouvelle version tous les deux mois, de deux nouvelles fonctionnalités par an à plus d’une cinquantaine (plus petites).
Quant au WIP, eh bien…
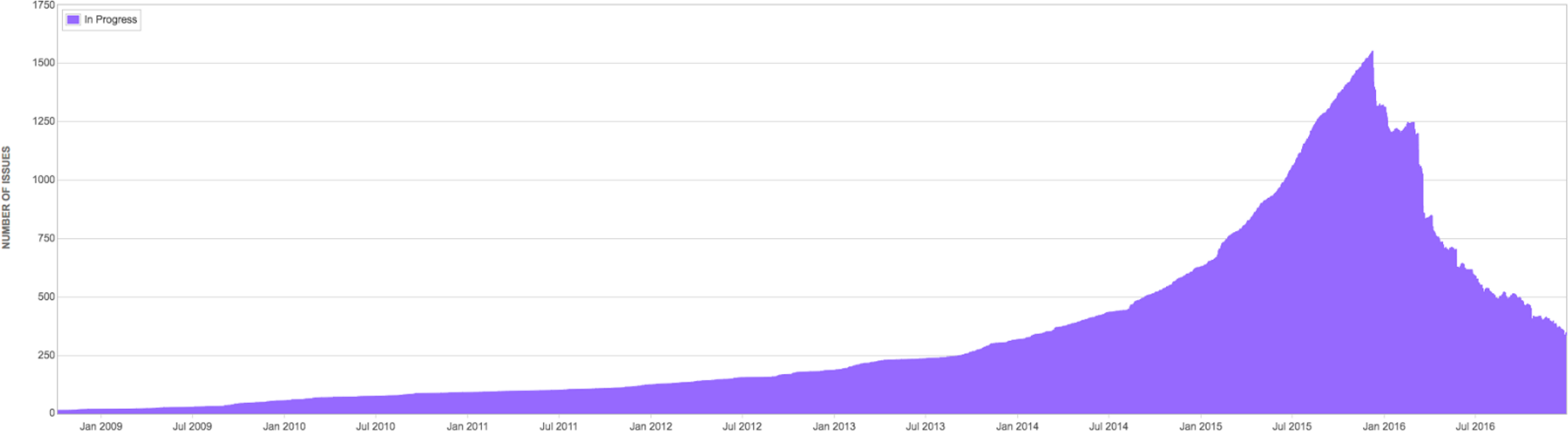
Voilà, c’est ça que je fais dans la vie.
D’autres questions ? 






