Pour parler uniquement du "dans un premier temps", on peut peut-être faire un mix des deux :
on commence par servir directement GA pour les stats ;
on stocke tout de même les données dans une BDD à nous.
Comme ça, le jour où on a des devs libres pour implémenter une interface sexy et/ou un système de requêtage qui vont bien, on aura déjà les données brutes en stock, et la migration sera beaucoup plus simple.
Alors certes, ça nécessite tout de même du dev pour réaliser le système d'import…
Est-ce que l'on a un développeur qui est "chaud bouillant" pour développer ce traitement de données avancés ?
Oui, Ok cool c'est cadeau une fois la spec' fini.
Non, pourquoi pas passer la ZEP dans le pool des idées pour le GSOC1 et se contenter en attendant d'une version minimale pour faire un premier écrémage de ce que nos auteurs utilisent ou pas (ou veulent) comme données ?
Non, pourquoi pas passer la ZEP dans le pool des idées pour le GSOC et se contenter en attendant d'une version minimale pour faire un premier écrémage de ce que nos auteurs utilisent ou pas (ou veulent) comme données ?
L'idée m'a traversé l'esprit mais je ne l'ai pas proposée parce que je me suis demandé si dans le "tas" de données il n'y en avait pas certaines un peu sensibles qu'on n'aimerait pas trop diffuser (donc uniquement à un développeur de confiance, si ça a un sens).
Après si c'est possible, je serais même tenter de lui faire réaliser le système d'extraction de données GA.
GSOC + API Google, ça a une certaine logique
y'a de grosses problématique de volume, perfs, etc. qui sont quand même très enrichissantes pour un stagiste.
L'idée m'a traversé l'esprit mais je ne l'ai pas proposée parce que je me suis demandé si dans le "tas" de données il n'y en avait pas certaines un peu sensibles qu'on n'aimerait pas trop diffuser (donc uniquement à un développeur de confiance, si ça a un sens).
Je ne saurais pas confirme, mais je pense pas qu'on ai vraiment de grosse confidentialité dans les données. Tout est anonymise chez GA. Cependant le dev' aura ptet accès en lecture et écriture avec les clés API, du coup faudrait pas non plus faire n'importe quoi.
Du coup je suis très partisan de rajouter cette idée dans le pool de sujets pour le GSOC. Si ca ne gêne personne et qu'aucun dev' n'a envie absolument de prendre en charge cette ZEP, je préparerais la traduction pour rajouter ca dans le programme.
En revanche, si un/des dev (principalement front mais un peu de back aussi ?) veux faire un MVP pour déjà proposer une interface minimale aux auteurs on peut aussi faire ca (car bon le GSOC ne démarre qu'en juin et fini fin août, ca fait 6 mois d'attente pour une interface complète). Dans ce cas la je séparerais la ZEP en deux comme il a été fait pour l'API. On aura alors :
ZEP-11-A : Interface simple de consultation des statistiques des tutoriels/articles
ZEP-11-B : Interface API de consultation des données avec datahousing maison.
Bon, je vais certainement avoir du temps dans quelques semaines pour m'investir dans le dev de cette ZEP. J'aimerai donc qu'on finalise la spec d'ici là. Je m'orienterai donc vers une solution pérenne et long terme.
Nous sommes parti du principe que nous nous basons uniquement sur les données de Google Analytics, ce qui signifie que les statistiques que nous présenterons, ne prendront pas en compte tout ceux qui utilisent des services qui bloquent GA (ghostery, noscript, etc.). Je ne connais pas le pourcentage d'utilisation de ce genre d'outil par les internautes, je ne sais même pas si AdBlock(Plus) bloquent cela, donc je m'interroge (c'est une question ouverte) : Est-ce réaliste de se fier à Google Analytics ?
Je me le demande car la seule alternative au point ou nous en somme pour sortir des statistiques serait d'analyser nos logs web. Cela nous permettrait d'avoir des données sur toutes les visites. La seule information qui ne serait techniquement pas possible d'avoir parmi celles listées dans ce topic est le temps passé sur une page. Il y'a aussi le fait que si on part sur cette solution, étant donné que les logs actuels en prod ne sont conservés que pour les 3 derniers mois, on aura jamais les stats de l'année 2014 via ce biais.
Quel est votre avis ? L'utilisation de GA pour ce module en vaut vraiment la chandelle ?
Oui. GA est infiniment plus simple à utiliser et ne risque pas ne nous exploser le serveur.
D'autre part, rien ne garantit qu'on va continuer à garder 3 mois de logs d'accès sur ZdS. En fait, la conf en place est celle par défaut et si on a 3 mois aujourd'hui c'est peut-être bien parce que j'ai activé ces logs il y a 3 mois…
J'aurais dit comme SpaceFox, GA est bien assez suffisant. Et pour les utilisateurs qui bloque les trackers, il suffit de mettre un petit avertissement en bas de page pour le rappeler.
Ce qu'on pourrait faire, c'est faire une analyse one shot avec les stats GA et les stats serveurs, pour avoir une idée de la différence, et pouvoir coller un message du style "Chiffres GA, les chiffres réels sont envrion X% supérieurs".
A priori, ça ne coûte rien d'installer un truc du style Awstats ou Piwik sur le serveur (ou mieux, sur celui de pré-prod), et de lui faire analyser les logs nginx une fois par moi / semestre / an. La seule contrainte, si c'en est une, c'est de scripter un backup des logs.
L'avantage, c'est que ça ne mettra rien à genou, et ça permettra de confronter GA et visites réelles à chaque campagne de stats.
Donc mon avis :
oui pour GA en principal, on y obtient rapidement des trucs parlants et sexys ;
oui aussi pour un analyseur de logs en parallèle, qui fonctionnera en "mode campagne" uniquement (= pas d'analyse à la demande), de type Awstats ou Piwik.
D'autre part, rien ne garantit qu'on va continuer à garder 3 mois de logs d'accès sur ZdS. En fait, la conf en place est celle par défaut et si on a 3 mois aujourd'hui c'est peut-être bien parce que j'ai activé ces logs il y a 3 mois…
Dans les derniers messages, on parlait de stocker les données GA dans une base pour pouvoir en disposer comme on le veut. Si on commence à stocker les données des logs, la fameuse limite de 3 mois n'existe plus (on perd juste ce qui s'est passé avant le début du stockage).
Je me rends compte donc que l'architecture cible n'est pas encore clair. Du coup, après un petit brainstorming avec moi même voici les architectures que je dégage, n'hésitez pas à dire laquelle vous parait la plus confortable pour ZdS :
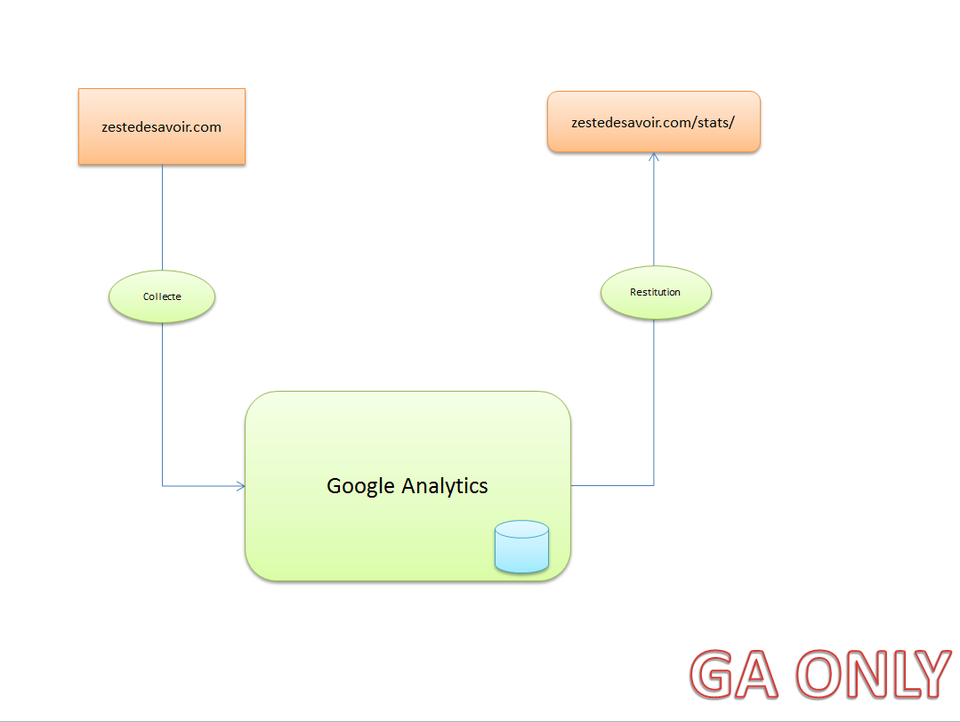
Architecture GA Only
Google Analytics fait son travail de collecte des informations, et le site (django dans notre cas) va se connecter sur l'API de Google Analytics pour afficher les informations en fonction des périodes demandées.
On ne compte pas ceux qui utilisent des bloqueurs (ghostery, noscript, etc.)
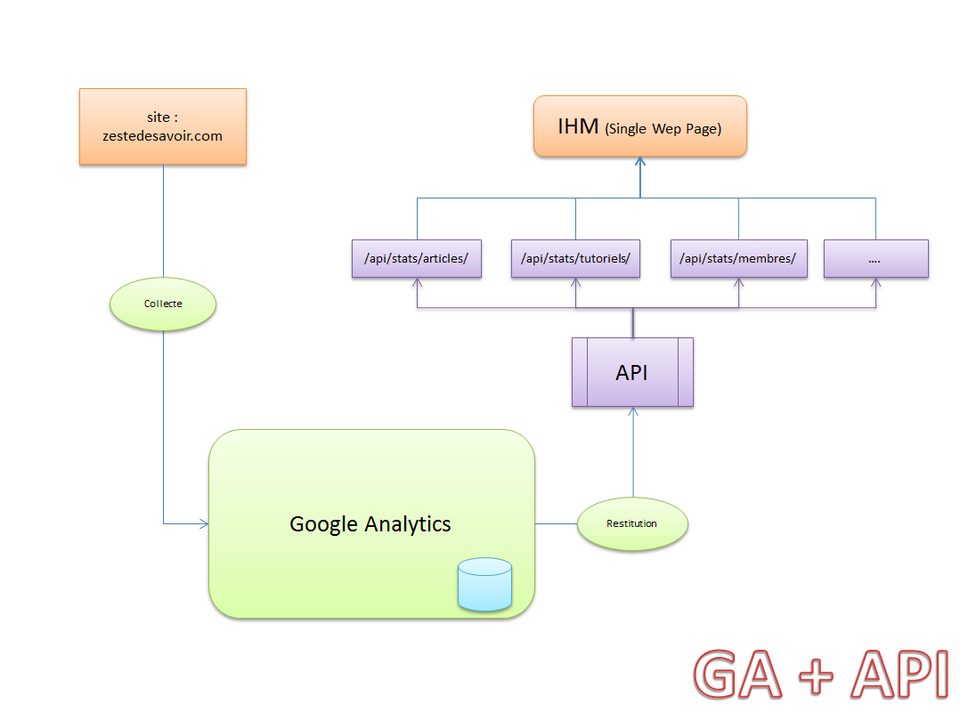
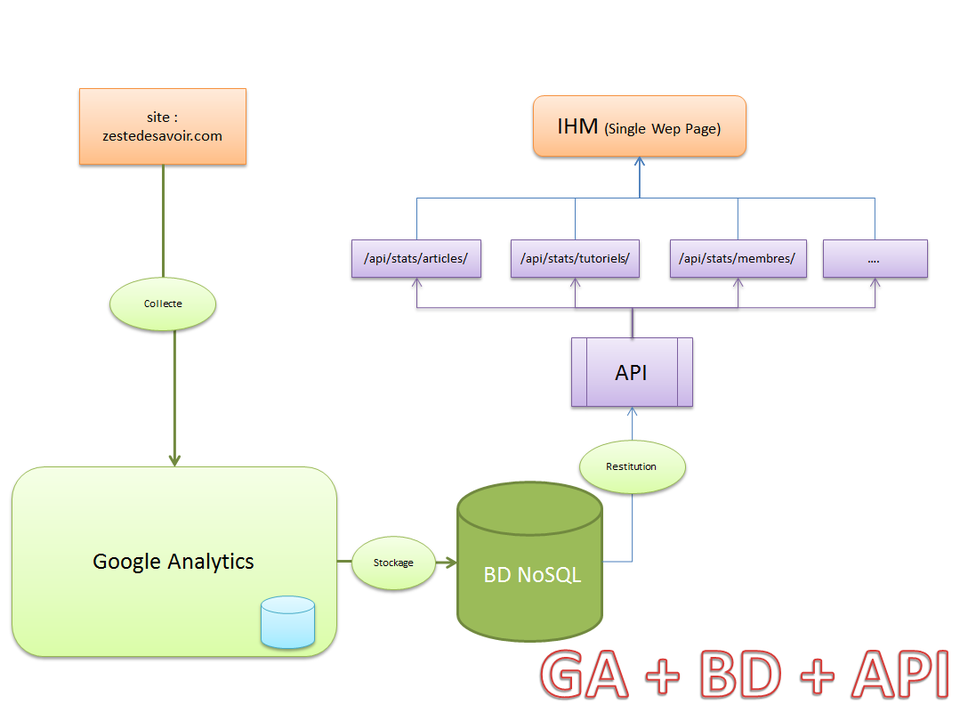
Architecture GA + BD + API
Google Analytics fait son travail de collecte des informations. Un script qui se lancera toute les x heures (pour ne pas dépasser la limite de GA), se charge de stocker les informations dans une base NoSQL (solr, elasticsearch, mongodb, etc.), et le module des stats se charge de présenter le contenu de la base via une API qui permet de présenter les stats comme on veut.
Schéma
Solution GA + BD + API
Avantages :
Un poil plus long a développer que la solution du dessus
La maintenance du serveur est assurée par Google
Des appli tierces peuvent exploiter les statistiques via l'API
Inconvénients :
Dépendance faible à Google
On ne compte pas ceux qui utilisent des bloqueurs (ghostery, noscript, etc.)
Architecture : Logs + BD + API
Les logs nginx sont parsés et stockés dans une base NoSQL (solr, elasticsearch, mongodb, etc.), et le module des stats se charge de présenter le contenu de la base via une API qui permet de présenter les stats comme on veut.
Schéma :
Solution Log + BD + API
Avantages :
Aucune dépendance vis à vis de Google
Chiffres justes car tout est comptabilisé
Temps de développement équivalent à celui de la solution du dessus.
Des appli tierces peuvent exploiter les statistiques via l'API
Inconvénients :
Pertes d'informations (mineures) par rapport à Google Analytics.
Nécessité de redimensionner notre serveur
Installation et maintenance des outils supplémentaires
se charge de stocker les informations dans une base NoSQL (solr, elasticsearch, mongodb, etc.),
Au delà du fait que j'ai du mal a comprendre comment tu met dans le même panier solr/elasticsearch et mongodb, j'ai du mal à comprendre le pourquoi du besoin d'un NoSQL. J'ai rien contre mais en soit je vois ce qui t'impose ça.
Perso je verrai bien un truc à la base simple :
On a d'un coté le provider de donnée qui doit se charger d'alimenter une base d'info. On doit pouvoir définir une interface sur les données qu'on veut enregistrer (pages vues, etc.)
On a une API qui exploite les données pour les mettre a disposition de la communauté
Cette API est aussi utilisé par le site pour présenter les résultats aux auteurs.
Pour moi si on veut faire un truc propre, c'est surtout au niveau du provider qu'il faut bien réfléchir : définir quels infos seront enregistré. Par exemple définir un schema clair de données (apres qu'en réel ça soit stocké dans un mongo ou un sql, osef). Si les providers de données sont bien définit, on peut faire une première version en crawlant régulièrement depuis l'API de GA et le jour ou on a plus de ressources remplacer ce module par Piwik ou n'importe quoi.
On a probablement jamais besoin de passer à Google Analytics Premium. Les limites sont ultra-hautes et, à ma connaissance, il n'a jamais été question de faire un appel à GA à chaque affichage de statistique, seulement à leurs calculs (une fois par jour à priori).
Il manque "Installation et maintenance des outils supplémentaires" dans les inconvénients du point "Logs + BD + API", et pourtant comme je l'ai déjà dit c'est sans doute l'inconvénient majeur de la solution.
"Pertes d'informations (mineures) par rapport à Google Analytics." –> j'aimerais plus de détails sur cette assertion : que perds-on vraiment ?
"On ne compte pas ceux qui utilisent des bloqueurs (ghostery, noscript, etc.)" –> On a déjà eu cette discussion, et ce qui en ressortait c'est que les erreurs de stats compensent la facilité d'utilisation. Alors on peut refaire encore le débat, mais le fait est que dans tous les articles parlant de stats, on ne nous a jamais demandé plus de précision à ce sujet - et pourtant l'origine des stats et ce que ça implique sur leur précision était précisée. Le seules remarques que j'ai vu passer rapport à GA sont celles sur l'appartenance de l'outil à Google.
Donc, j'en reviens à la même conclusion que mes 2 voisins du dessus : si jamais on veut se débarrasser de Google Analytics, d'une part c'est après un vrai débat en sachant exactement ce qu'on gagne et perds, et d'autre part c'est pour le remplacer par un outil fiable et pas pour réinventer la roue.
j'ai du mal à comprendre le pourquoi du besoin d'un NoSQL.
Kje
Pour le besoin de stockage des données multidimensionnelles et du requetages rapide. Utiliser un SGBDR ici serait beaucoup moins performant étant donné qu'on utilise en aucun cas les aspects transactionnels et que toutes nos informations sont potentiellement indexables (afin de pouvoir rechercher facilement à l'intérieur).
Perso je verrai bien un truc à la base simple :
Kje
La solution que tu décrit ce sont les 3 trois dernières solutions que je présente. Avec les avantages et inconvénients que ça comporte.
@firm1 : même question que Kjé + pourquoi réinventer la roue ?
Coyote
Je ne parle pas encore d'outil pour le moment, si on se décide sur une architecture on pourra parler ensuite de son implémentation.
il n'a jamais été question de faire un appel à GA à chaque affichage de statistique, seulement à leurs calculs (une fois par jour à priori).
SpaceFox
Ceci rejoins donc la solution 3 (GA + BD + API) ? Puisque les données calculées doivent être stockées quelque part.
Il manque "Installation et maintenance des outils supplémentaires" dans les inconvénients du point "Logs + BD + API", et pourtant comme je l'ai déjà dit c'est sans doute l'inconvénient majeur de la solution.
Bien vu, je modifie.
"Pertes d'informations (mineures) par rapport à Google Analytics." –> j'aimerais plus de détails sur cette assertion : que perds-on vraiment ?
Comme je l'ai dis, en relisant le topic, les données qu'on ne peut pas obtenir sont celles qui nécessite du JS (temps passés sur une page, nombre de membres connectés à l'instant, etc.)
GA ou pas GA peu importe, par contre le bon sens assurerait d'avoir une façade entre les données brutes GA et les données exposables.
Que ce soit une BDD relationnelle ou non, etc.
Tant qu'à faire de partir sur du tout neuf (c'est bien, firm1 a visiblement le temps de se pencher sur la question et est motivé pour faire quelque chose de propre), je suis vraiment favorable à intercaler un pont entre les données GA et les données API (ou page, ou BDD ou n'importe quoi), quitte à ce qu'en V1 ledit pont soit quasi isomorphe (c'est comme ça qu'on dit ? :\ ).
Le jour ou on a un autre fournisseur de données : il n'y a qu'à écrire un pont / adapter suivant le terme qu'on préfère utiliser pour faire "entrer" les données dans le système. Le côté "exposition des données" restant pour lui inchangé.
Ca pourrait, par exemple, permettre d'utiliser les logs conjointement à GA, ou foutre en l'air GA le jour où ils cassent les pieds, ou passer à un autre service parce que franchement il est top.
Franchement c'est un sacré luxe qu'on aimerait tous avoir le temps de faire en entreprise (c'est juste l'application bête et méchante de façade/adapters ptetre plus au niveau architectural).
Juste une idée comme ça, histoire qu'elle soit mentionnée explicitement, même si elle me paraît aller de soi : si on installe un système indépendant de GA, quel que soit ce système, qu'est-ce qui nous empêche d'intégrer dans notre BDD les données de GA de l'ouverture du site jusqu'à la date de mise en place du nouveau système ?
EDIT : c'est plus ou moins ce que dit Javier, mais on a écrit en parallèle.
si on installe un système indépendant de GA, quel que soit ce système, qu'est-ce qui nous empêche d'intégrer dans notre BDD les données de GA de l'ouverture du site jusqu'à la date de mise en place du nouveau système ?
Si y'a "traduction", "agrégation", "adaptation", etc. m'est avis qu'il vaudrait mieux la faire entre GA et un système propre à ZdS (la fameuse BD dont parle firm1 par exemple), plutôt qu'entre le site et la BDD (ou autre support de persistence) non ?
Le truc c'est qu'en disant "on fait KISS, on stocke brutalement les données renvoyées par GA" tu peux être sûr que tu vas te retrouver à les adapter/bricoler un jour ou l'autre (ne serait-ce que pour les agréger). Si t'as choisi la mauvaise solution technique (e.g. t'as rempli brutalement un MongoDB avec le JSON issu de l'API GA), tu vas te retrouver à écrire du code franchement peu enviable (et vas-y que je manipule des maps de maps de maps de listes de maps de maps, ou alors que je vais chercher les nième noeud du pième document) etc. Et tu prends vraiment le risque de soit tout refaire, soit d'avoir à écrire un truc infâme.
En comparaison, tu pourrais stocker chaque visite sous forme clé/valeur dans un redis, c'est con, mais à t0 sans savior à quoi ressemble ladite façade, ça se tient presque.
Etc.
A mon avis faut prendre le problème dans l'autre sens : a quoi devrait ressembler une façade propre exposant des stats aux utilisateurs/rédacteurs de cours (peu ou prou ce qu'à fait Eskimon ?) ? Comment on arrive à ça depuis les données de GA ? C'est quoi la meilleure solution technique entre les deux ?
PS : j'ai pas l'impression que ce soit réellement ton propos SpaceFox (KISS == on stocke ce qui provient de GA) mais en fait j'ai un doute donc mieux vaut prévenir que guérir. Sans aucune forme de méchanceté ou autre procès d'intention.
Je sais pas, il faut que j'y réfléchisse à tête reposée. Mais pour moi on doit se fixer 2 objectifs :
Efficace : on sort les stats dont les auteurs ont besoin (cf le 1er post, on peut faire un genre de sondage aussi)
Simple à maintenir : on a déjà du mal à dépiler notre liste de ticket et encore plus notre liste de ZEP "cœur de métier", si en plus on doit maintenir un système qui fait du café avec les stats, on ne va jamais s'en sortir
PS :
j'ai pas l'impression que ce soit réellement ton propos SpaceFox (KISS == on stocke ce qui provient de GA)
Non, c'est pas mon propos.
Mais là j'ai l'impression qu'on parle de stocker des tonnes de données et de faire des quantités délirantes de stats avec. C'est clairement pas le but.
Ou alors, on se la joue comme la faisait Motion Twins avec ses jeux : on ne sort aucune stat par nous-même, on met à disposition des données brutes et on laisse la communauté faire des outils tiers pour les stats. Ça peut être une piste.
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte