Depuis le début de ce tutoriel, nous avons compilé et recompilé de nombreuses fois nos programmes. Vous savez, depuis l’introduction, que la compilation transforme notre code source en un programme exécutable qui sera compris par l’ordinateur. Mais, concrètement, que se passe-t-il pendant la compilation ? Quelles en sont les différentes étapes ?
Le but de ce chapitre va être de présenter en détails la compilation d’un code C++.
Le préprocesseur
La toute première étape est celle du préprocesseur. Ce nom vous est familier ? Normal, on fait déjà appel à lui pour chaque ligne qui commence par #.
Inclure des fichiers
Dans le cas de la directive #include, il s’agit d’inclure tout le fichier demandé. Il est possible de voir à quoi ressemble notre code après son passage.
- Avec Visual Studio, il faut faire un clic-droit sur le nom du projet et cliquer sur Propriétés. Là, on va dans Propriétés de configuration -> C/C++ -> Préprocesseur, puis on met le champ Prétraiter dans un fichier à Oui (/P). Attention cependant, cette option bloque la suite de la compilation. Donc désactivez la sortie du préprocesseur une fois que vous avez fini d’explorer cette option.
- Avec QtCreator, il faut modifier le fichier .pro en lui ajoutant la ligne
QMAKE_CXXFLAGS += -save-temps. Le fichier obtenu après traitement a une extension en.ii. - Pour ceux qui travaillent en ligne de commande, pour GCC c’est
g++ -E fichier.cpp -o fichier.iet pour Clang,clang++ -E fichier.cpp -o fichier.i.
Le résultat n’est pas le même en fonction du compilateur, mais le fichier devient conséquent après le passage du préprocesseur. Pour un simple #include <iostream>, j’obtiens plus de 17.800 lignes pour Clang, plus de 18.000 lignes avec GCC et même plus de 50.000 lignes avec Visual Studio (dont pas mal vides, certes) !
Conditions
Mais le préprocesseur ne se contente pas d’inclure bêtement ce qu’on lui demande et c’est tout. Il est capable d’exécuter d’autres instructions, notamment celles permettant d’éviter les inclusions multiples. Ce sont des instructions conditionnelles pour le préprocesseur. Je vous remets un exemple ci-dessous.
#ifndef TEST_HPP
#define TEST_HPP
#endif
La première ligne teste si une constante de préprocesseur TEST_HPP existe. Si ce n’est pas le cas, alors on exécute le code qui suit. Justement, la ligne d’après définit la constante TEST_HPP. Ainsi, si l’on tente d’inclure de nouveau le fichier, la première condition devient fausse et rien n’est inclus. Enfin, l’instruction #endif permet de fermer la portée du #ifndef, tout comme les accolades fermantes pour if.
Ce mécanisme de conditions est très utilisé au sein des fichiers d’en-tête de la bibliothèque standard. En effet, cela permet d'adapter le code en fonction de la version du compilateur ou de la norme C++, entre autres. Par exemple, la bibliothèque standard fournie avec Visual Studio utilise le code suivant pour ne définir la fonction std::for_each_n que si l’on compile en C++17.
#if _HAS_CXX17
// Le code de la fonction std::for_each_n, disponible uniquement à partir de C++17.
#endif /* _HAS_CXX17 */
Debug ou release ?
Le préprocesseur est également utilisé pour modifier la bibliothèque standard selon qu’on compile en debug ou en release. Il s’agit de modes de compilation qui sont utilisés en fonction du moment.
Debug — Quand on code
Le mode debug inclut, dans le code de la bibliothèque standard, de nombreuses vérifications et autres tests. C’est le mode dans lequel est compilé le code quand on est encore en plein développement, qu’on cherche à corriger des bugs ou qu’on fait des tests. Depuis le début du cours, nous ne compilons qu’en mode debug. C’est pour cette raison que, quand nous utilisons un indice trop grand, le programme plante avec un message d’erreur.
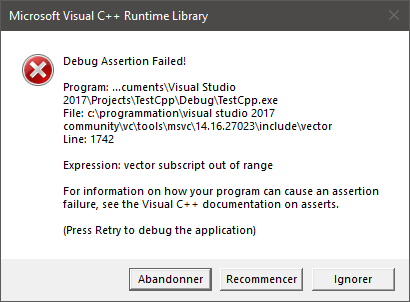
Si on regarde le code de std::vector tel qu’il est fourni avec Visual Studio, on trouve les lignes suivantes. On retrouve le message qu’on voit dans la fenêtre ci-dessus.
#if _ITERATOR_DEBUG_LEVEL != 0
_STL_VERIFY(_Pos < size(), "vector subscript out of range");
#endif /* _ITERATOR_DEBUG_LEVEL != 0 */
La macro _ITERATOR_DEBUG_LEVEL est elle-même définie uniquement si une macro _HAS_ITERATOR_DEBUGGING est définie comme valant autre chose que 0. Cette dernière dépend de l’existence de la macro _DEBUG, qui est uniquement définie quand on compile en mode debug.
Release — Quand on distribue
Le mode release, lui, se débarrasse de toutes ces vérifications, optimise le code pour le rendre plus rapide à exécuter et réduit la taille de l’exécutable qu’on obtient en sortie. On compile avec ce mode quand le programme est prêt et qu’on veut le distribuer à d’autres personnes. À ce stade, on juge que le programme est suffisamment bon et correctement testé. Il est donc inutile de continuer à inclure tous les tests et autres vérifications, qui rendent le code plus gros et plus lent.
Typiquement, les assertions sont désactivées en release. Bien souvent, assert n’est pas implémentée en tant que fonction, comme nous en avions l’habitude, mais à l’aide du préprocesseur, ce qui permet de la supprimer du code, ou de la rendre inopérante, quand on passe en release.
La compilation
Maintenant que le préprocesseur a fini son travail, place à la compilation à proprement parler. Chaque fichier obtenu après le passage du préprocesseur, qu’on appelle unité de compilation, est traité individuellement. Le but de cette phase est de transformer le C++ en code exécutable par l’ordinateur.
C’est lors de cette étape que beaucoup de vérifications ont lieu et donc d’erreurs. Par exemple, dans le cas où le compilateur ne trouve pas la déclaration d’une fonction que vous appelez, il décidera de faire s’arrêter la compilation. Vous aurez alors un message d’erreur vous indiquant ce qui n’a pas fonctionné.
Les templates
Comme dit dans le chapitre correspondant, le compilateur va instancier chaque template qu’il trouve avec les bons types. C’est pendant cette étape que des erreurs incompréhensibles de templates peuvent arriver, par exemple quand on tente d’appliquer std::sort sur une std::list.
Prenez l’exemple suivant d’un code C++ très simple.
template <typename T>
void fonction(T const & t)
{
T const resultat { t * 2 };
}
int main()
{
fonction(42);
fonction(3.1415);
return 0;
}
Avec Clang, il est possible d’utiliser les options -Xclang -ast-print -fsyntax-only pour afficher le code après l’instanciation des templates. Avec GCC, c’est la commande -fdump-tree-original qui génère des fichiers .original qu’on peut afficher.
On voit dans le résultat suivant, obtenu avec Clang, que le template est instancié deux fois, avec int et avec double.
template <typename T = int> void fonction(const int &t) {
const int resultat{t * 2};
}
template <typename T = double> void fonction(const double &t) {
const double resultat{t * 2};
}
template <typename T> void fonction(const T &t) {
const T resultat{t * 2};
}
int main() {
fonction(42);
fonction(3.1415);
return 0;
}
constexpr
Nous avions dit, dans le chapitre sur la documentation, que nous reviendrons sur ce mot-clé en temps voulu. C’est maintenant le moment d’en parler, car il a un rapport avec la compilation. En effet, il indique au compilateur qu'une variable ou une fonction peut déjà être évaluée pendant la compilation et non plus seulement à l’exécution du programme. L’avantage, c’est que c’est le compilateur qui effectue le travaille une fois pour toutes, ce qui rend l’exécution du programme plus rapide.
Des constantes
En déclarant des constantes avec le mot-clef constexpr, on les rend utilisables à la compilation. Typiquement, dans le cas où l’on fixe d’avance la hauteur et la largeur d’une matrice, utiliser std::array est tout à fait possible.
constexpr std::size_t hauteur { 5 };
constexpr std::size_t largeur { 4 };
std::array<int, hauteur * largeur> matrice {};
constexpr et constImplicitement, utiliser constexpr sur une variable revient à la déclarer const, ce qui est logique. Personnellement, dans le but d’être explicite, je précise également const, mais ce n’est pas une obligation, simplement une question de goût.
Par contre, pour que l’instruction soit valide et que le programme puisse compiler, il faut qu’elle soit évaluable à la compilation. Cela signifie que toute l’expression doit être comprise et utilisable par le compilateur pendant la compilation et que rien ne doit dépendre de variables non-constantes, d’entrées/sorties, etc.
int main()
{
// Valide parce que 5 est une littérale évaluable à la compilation.
constexpr int const x { 5 };
// Valide parce que x est constexpr.
constexpr int const y { 2 * x };
// Invalide car b n'est pas une constante.
int b { 10 };
constexpr int const non { b - 5 };
return 0;
}
Des fonctions
Grâce au mot-clé constexpr, nous somme capables d’écrire des fonctions qui s’exécuteront pendant la compilation, ce dont nous étions pas capables jusque-là, tout du moins sans utiliser les templates. En plus, la syntaxe est très simple, puisqu’il suffit d’ajouter constexpr au prototype de la fonction.
constexpr int add(int a, int b)
{
return a + b;
}
Cela a néanmoins un effet un peu particulier.
- Si la fonction est appelée avec des arguments
constexpr, comme des littéraux ou des variablesconstexpr, alors elle est exécutée à la compilation. - Dans le cas contraire, avec des arguments non-
constexpr, elle se comporte normalement et est exécutée pendant l’exécution du programme.
Prenons un exemple en calculant la factorielle d’un nombre entier. C’est une opération mathématique simple, qui se définit comme le produit de tous les entiers de 1 à . La formule est la suivante.
Ainsi, vaut 2, mais vaut déjà 3628800 ! C’est donc une opération qu’il convient de faire calculer au compilateur si cela est possible. En plus, son implémentation est toute simple, comme vous le montre le code suivant. Notez que dans le premier cas, la fonction est appelée pendant la compilation, alors que dans le deuxième cas, pendant l’exécution.
#include <array>
#include <iostream>
constexpr int factorielle(int n)
{
int resultat { 1 };
for (int i { 1 }; i <= n; ++i)
{
resultat *= i;
}
return resultat;
}
int main()
{
// Exécuté à la compilation.
std::array<int, factorielle(3)> tableau {};
// Exécuté quand le programme est lancé.
int entier { 0 };
std::cout << "Donne un entier entre 1 et 10 : ";
std::cin >> entier;
std::cout << "Sa factorielle vaut " << factorielle(entier) << "." << std::endl;
return 0;
}
Alors pourquoi ne pas déclarer toutes nos fonctions constexpr ? Comme ça on gagne en performances.
Parce que constexpr est soumis à des restrictions. En C++11, il ne pouvait pas y avoir de boucles ou de if / else. Depuis C++14, ces restrictions ont été levées, ce qui permet l’implémentation de la factorielle telle que vous la voyez plus haut.
Et sans parler de ces considérations, une fonction ne peut être constexpr que si toutes ses instructions sont évaluables pendant la compilation. Cela nous interdit donc d’utiliser les entrées/sorties ou des fonctions qui ne sont pas constexpr. Voilà pourquoi toutes nos fonctions ne peuvent pas être exécutées pendant la compilation.
La compilation à proprement parler
Maintenant, il s’agit de transformer tout ce code C++ en quelque chose de compréhensible par l’ordinateur. Lui ne comprend que les 0 et les 1. Il n’a que faire de nos noms de variables, de fonctions ou de type. La transformation du C++ en code machine se fait en plusieurs étapes. On peut en citer quelques-unes.
- L’analyse lexicale, où il déduit que
autoouintsont des mots-clés,mainouxsont des identificateurs,=ou+sont des opérateurs, etc. - L’analyse syntaxique, où le compilateur regarde si la syntaxe fait sens et ce qu’elle signifie. Ainsi, écrire
auto = 5sera rejeté pendant la compilation car cette syntaxe n’a aucun sens. - Les optimisations, notamment en mode release. Cette étape supprime du code inutile, modifie certaines portions pour qu’elles s’exécutent plus vite, etc.
- Génération du code pour la plateforme cible. Le fichier objet ne sera pas pareil selon qu’on compile sous Windows ou GNU/Linux, donc le compilateur fait des adaptations pour la machine cible.
Je ne détaille pas plus la compilation du C++ à proprement parler car c’est affreusement compliqué. C++ a la réputation d’être un langage dont l’écriture du compilateur est très compliquée et cette réputation n’est pas volée.
Le compilateur va au final générer des fichiers objets, un pour chaque fichier .cpp, chaque unité de compilation, qu’il trouve, comprenant son code propre et tous les fichiers d’en-têtes inclus. Si aucune modification n’est détectée depuis la dernière compilation, alors le compilateur réutilise le fichier objet précédemment créé, ce qui accélère la compilation d’un projet.
Un fichier objet, reconnaissable à son extension en .o ou .obj, n’est rien d’autre que du code machine mais seul, sans aucun lien avec le reste du monde. Tel quel, il n’est pas exécutable, car il lui manque des informations. Pour cela, il faut utiliser le linker, ce que nous allons voir dans la partie suivante.
Dans le cas de Visual Studio, ils sont présents dans le dossier de sortie. Dans le cas de GCC et Clang, il faut utiliser l’option -c lors de la compilation.
> g++ -std=c++17 -c test.cpp -o test.o
> clang++ -std=c++17 -c test.cpp -o test.o
Une étape intermédiaire cachée
Beaucoup de compilateurs génèrent maintenant directement des fichiers objets, rendant invisible une étape intermédiaire, la transformation de C++ en Assembleur, un langage de bas-niveau très proche du langage machine. Ce langage était ensuite passé à un assembleur 1, qui s’occupait de transformer ce code en fichier objet.
Il est cependant possible d’obtenir le code Assembleur généré avec la bonne option.
- Avec Visual Studio, il faut aller dans les propriétés du projet, puis dans C/C++ -> Fichiers de sortie. Là, il faut mettre l’option Sortie de l’assembleur à Assembleur, code machine et source (/FAcs).
- Avec Qt Creator, si vous avez déjà ajouté la ligne
QMAKE_CXXFLAGS += -save-tempsà votre fichier .pro, vous n’avez rien d’autre à faire. Le fichier assembleur est celui avec une extension .s. - Avec GCC et Clang, il faut compiler avec l’option
-S.
Attention, il s’agit d’un langage très… brut de décoffrage. Si vous ne me croyez pas, jetez un œil par vous-mêmes, vous allez être surpris. 
Influer sur la compilation
Il est possible de passer d’autres informations au compilateur, notamment pour lui demander d’effectuer certaines opérations ou des tests supplémentaires. Cette possibilité est importante puisque plus le compilateur fait de vérifications, plus il peut nous signaler d’éventuels problèmes dans notre code. C’est ce qu’on appelle les warnings. Loin de nous embêter, le compilateur est donc un précieux allié.
Un mot sur les outils
Comme le compilateur fourni avec Visual Studio est différent de GCC ou de Clang, les options de compilation et les warnings sont aussi différents et ne s’activent pas forcément de la même façon.
Avec Visual Studio, allez dans les propriétés du projet, puis C/C++ -> Général et là, mettez le champ Niveau d’avertissement à la valeur Niveau 4 (/W4). Cela augmente le nombre de vérifications effectuées et donc de warnings générés. Je ne conseille pas (/Wall) parce que cette option est si sévère qu’elle va même générer des avertissements dans le code de la bibliothèque standard.
Avec GCC ou Clang, il faut rajouter des options supplémentaires, qu’on appelle couramment des flags. Il en existe énormément, tant pour GCC que pour Clang. Mais les deux plus utilisés sont -Wall et -Wextra, qui activent en sous-main de nombreux warnings, ceux revenant le plus fréquemment.
> g++ -std=c++17 -Wall -Wextra test.cpp -o test.out
> clang++ -std=c++17 -Wall -Wextra test.cpp -o test.out
Je vous conseille de toujours activer les warnings suggérés ci-dessus. Plus le compilateur travaille pour vous, plus vous pouvez corriger tôt d’éventuels problèmes et améliorer ainsi la qualité de votre code.
Conversion entre types
Dès le début de ce cours, nous avons vu des types simples, permettant de stocker des caractères (char), des entiers (int, std::size_t) et des réels (double). Ils sont bien pratiques, mais si on commence à les mélanger, on peut avoir des problèmes.
En effet, comme déjà signalé dans le chapitre sur les erreurs, tous n’ont pas la même taille. Un int, par exemple, ne peut pas stocker des nombres aussi grands que double peut. Ainsi, convertir un double en int entraîne une perte d’information. C’est un peu comme vouloir transvaser de l’eau depuis un seau dans un gobelet.
Le code suivant illustre bien le principe, puisque en passant d’un double à un int, on perd comme information la partie décimale du nombre.
#include <iostream>
double fonction()
{
return 3.141582;
}
int main()
{
int const x { fonction() };
std::cout << "Voici un nombre : " << x << std::endl;
return 0;
}
Le compilateur ne va d’ailleurs pas se gêner pour vous le dire.
[Visual Studio]
Erreur C2397 la conversion de 'double' en 'int' requiert une conversion restrictive
------------------------------------------------------------
[GCC]
test.cpp: In function ‘int main()’:
test.cpp:10:27: warning: narrowing conversion of ‘fonction()’ from ‘double’ to ‘int’ inside { } [-Wnarrowing]
int const x { fonction() };
~~~~~~~~^~
------------------------------------------------------------
[Clang]
test.cpp:10:19: error: type 'double' cannot be narrowed to 'int' in initializer list [-Wc++11-narrowing]
int const x { fonction() };
^~~~~~~~~~
test.cpp:10:19: note: insert an explicit cast to silence this issue
int const x { fonction() };
^~~~~~~~~~
static_cast<int>( )
Le compilateur nous prévient que c’est une erreur et qu’il faut une conversion explicite, ou en anglais cast, pour résoudre le problème. Clang est le plus sympa puisqu’il propose une solution, qui consiste à utiliser le mot-clé static_cast. Ce dernier permet de dire explicitement au compilateur qu’on veut convertir un type vers un autre, en l’occurrence ici un double vers un int. Il s’utilise comme suit.
static_cast<le type qu'on veut en résultat>(une variable ou une littérale)
Une fois la conversion explicite appliquée, le code fonctionne sans problème.
#include <iostream>
double fonction()
{
return 3.141582;
}
int main()
{
int const x { static_cast<int>(fonction()) };
std::cout << "Voici un nombre : " << x << std::endl;
return 0;
}
Sans les avertissements du compilateur, l’erreur serait sans doute passée inaperçue. Si l’on comptait faire des calculs avec nos valeurs réelles, ceux-ci auraient été faussés puisque les parties décimales auraient disparues. Avec l’avertissement, nous pouvons soit corriger notre erreur, soit mettre le cast pour montrer que notre conversion est voulue et volontaire.
Oubli d’initialiser
Imaginez que vous oubliez d’écrire les accolades {} après avoir déclaré une variable. C’est moyennement cool, puisque du coup, on ne lui donne pas de valeur par défaut. Elle peut donc valoir tout et n’importe quoi. Le message du code suivant peut, ou non, s’afficher. C’est impossible à savoir.
#include <iostream>
int main()
{
int x;
if (x > 5)
{
std::cout << "J'ai l'impression d'oublier quelque chose..." << std::endl;
}
return 0;
}
Heureusement, le compilateur ne manque pas de le souligner.
[Visual Studio]
Erreur C4700 variable locale 'x' non initialisée utilisée
------------------------------------------------------------
[GCC]
test.cpp: In function ‘int main()’:
test.cpp:7:5: warning: ‘x’ is used uninitialized in this function [-Wuninitialized]
if (x > 5)
^~
------------------------------------------------------------
[Clang]
test.cpp:7:9: warning: variable 'x' is uninitialized when used here [-Wuninitialized]
if (x > 5)
^
test.cpp:5:10: note: initialize the variable 'x' to silence this warning
int x;
^
= 0
Paramètres inutilisés
Imaginez que vous déclarez une fonction attendant deux paramètres, mais que vous n’en utilisez qu’un seul. C’est peut-être volontaire, parce que vous n’avez pas encore fini de l’implémenter, mais c’est peut-être une erreur, soit que vous avez oublié une portion de code à écrire, soit oublié de supprimer un paramètre désormais inutile.
#include <iostream>
#include <string>
void fonction(std::string const & chaine, bool en_majuscule)
{
std::cout << chaine << std::endl;
}
int main()
{
std::string const une_phrase { "Du texte." };
fonction(une_phrase, true);
return 0;
}
Votre compilateur se demande quelle est votre intention et vous affiche donc un message.
[Visual Studio]
Warning C4100: 'en_majuscule' : paramètre formel non référencé
------------------------------------------------------------
[GCC]
test.cpp: In function ‘void fonction(const string&, bool)’:
test.cpp:4:48: warning: unused parameter ‘en_majuscule’ [-Wunused-parameter]
void fonction(std::string const & chaine, bool en_majuscule)
^~~~~~~~~~~~
------------------------------------------------------------
[Clang]
test.cpp:4:48: warning: unused parameter 'en_majuscule' [-Wunused-parameter]
void fonction(std::string const & chaine, bool en_majuscule)
^
1 warning generated.
Release et debug
Les options de compilation servent aussi à indiquer au compilateur le mode choisi. Il est ainsi capable d’optimiser le programme pour le rendre plus petit et plus rapide. Une partie de ce travail est faite quand le préprocesseur passe, mais d’autres améliorations et optimisations sont effectuées par le compilateur.
Avec Visual Studio, il faut simplement changer la valeur du cadre de l’image ci-dessous, qui se trouve près du triangle vert Débogueur Windows local.
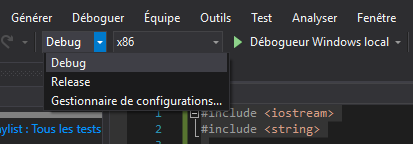
Avec GCC et Clang, c’est l’option de compilation -O2 qu’il faut passer. Celle-ci cherche à optimiser le programme pour rendre son exécution plus rapide.
g++ -std=c++17 -Wall -Wextra -O2 test.cpp -o test.out
- Oui, il s’agit du même nom pour le langage et pour l’outil qui compile ce langage. On les différencie toutefois en employant un « A » majuscule pour parler du langage.↩
Le linker
Les propos ci-dessous sont illustrés sous GNU/Linux, mais le principe et la plupart des explications sont valables peu importe le système d’exploitation.
Maintenant que nous avons des fichiers objets, il faut les lier pour obtenir notre exécutable final. C’est justement le travail accompli pendant l’étape du linkage. Et pour illustrer mes explications, nous allons travailler avec le code ci-dessous, divisé en trois fichiers.
D’abord, le fichier d’en-tête test.hpp, qui ne contient qu’un simple prototype.
#ifndef TEST_HPP
#define TEST_HPP
int fonction();
#endif
Ensuite, le fichier test.cpp, qui est l’implémentation du prototype déclaré précédemment.
#include "test.hpp"
int fonction()
{
return 38;
}
Et enfin le fichier main.cpp, le point d’entrée.
#include <iostream>
#include "test.hpp"
int main()
{
int const x { 5 };
std::cout << "Voici un calcul : " << x + fonction() << std::endl;
return 0;
}
On génère donc le code. Que ce soit avec GCC, Clang ou en utilisant Visual Studio, on obtient deux fichiers objets, un par fichier source.
> g++ -std=c++17 -c test.cpp main.cpp
> clang++ -std=c++17 -c test.cpp main.cpp
Une question de symboles
Un fichier objet contient, entre autres, des symboles. Qu’est-ce que c’est ? Un symbole correspond au nom d’une fonction ou d’une variable. Les noms de toutes les fonctions et variables utilisées dans chaque fichier source sont donc présents dans les fichiers objets correspondants. On peut le voir en utilisant la commande objdump -t fichier.o -C.
> objdump -t test.o -C
test.o: format de fichier elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 test.cpp
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
0000000000000000 g F .text 000000000000000b fonction()
De nombreuses informations sont affichées, qui nécessiteraient beaucoup d’explication. Notons simplement qu’on retrouve notre identificateur fonction sur la dernière ligne. La lettre F indique qu’il s’agit d’une fonction. Devant, on note la présence de .text, la section dans laquelle fonction se trouve.
Sans rentrer dans les détails ni transformer ce cours de C++ en cours système, il faut savoir qu’un programme est découpé en plusieurs sections. Une section regroupe certaines informations ensemble. Citons la section .text qui contient le code et .rodata, qui contient toutes les données non-modifiables, comme les littérales chaînes de caractères.
Dans le cas du fichier objet test.o, comme fonction désigne une fonction, donc du code exécutable, il est normal que sa section soit .text. Et si on faisait la même analyse sur main.o ?
objdump -t main.o -C
main.o: format de fichier elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 main.cpp
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l O .bss 0000000000000001 std::__ioinit
0000000000000000 l d .rodata 0000000000000000 .rodata
0000000000000059 l F .text 0000000000000049 __static_initialization_and_destruction_0(int, int)
00000000000000a2 l F .text 0000000000000015 _GLOBAL__sub_I_main
0000000000000000 l d .init_array 0000000000000000 .init_array
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
0000000000000000 g F .text 0000000000000059 main
0000000000000000 *UND* 0000000000000000 std::cout
0000000000000000 *UND* 0000000000000000 _GLOBAL_OFFSET_TABLE_
0000000000000000 *UND* 0000000000000000 std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*)
0000000000000000 *UND* 0000000000000000 fonction()
0000000000000000 *UND* 0000000000000000 std::ostream::operator<<(int)
0000000000000000 *UND* 0000000000000000 std::basic_ostream<char, std::char_traits<char> >& std::endl<char, std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&)
0000000000000000 *UND* 0000000000000000 std::ostream::operator<<(std::ostream& (*)(std::ostream&))
0000000000000000 *UND* 0000000000000000 std::ios_base::Init::Init()
0000000000000000 *UND* 0000000000000000 .hidden __dso_handle
0000000000000000 *UND* 0000000000000000 std::ios_base::Init::~Init()
0000000000000000 *UND* 0000000000000000 __cxa_atexit
Certaines choses ne nous surprennent pas, comme main désignée comme étant une fonction située dans .text. Par contre, d’autres lignes n’ont que pour seule information *UND*. On trouve plusieurs choses familières, comme std::cout ou encore std::ostream::operator<<(int).
En fait, toutes les lignes contentant *UND* désignent des symboles n’ayant aucune section liée. Ce sont des symboles qui ne sont pas définis dans notre fichier objet. Il faut donc lier celui-ci à d’autres fichiers objets, notamment ceux qui contiennent ce qui nous manque.
Dans le cas de la bibliothèque standard, c’est fait automatiquement par le compilateur sans avoir besoin de rien faire. Mais pour résoudre le symbole fonction(), il faut lier nos deux fichiers objets. C’est très simple, la commande suivante vous le montre. Notez que l’option -std=c++17 est absente, car ici on ne compile rien, on linke, ou assemble, deux fichiers objets.
g++ test.o main.o -o mon_super_programme.out
clang++ test.o main.o -o mon_super_programme.out
Maintenant, on obtient un exécutable parfaitement fonctionnel. La compilation est terminée.
./super_programme.out
Voici un calcul : 43
Au contraire, si on tente de compiler seulement main.o, le linkage échouera avec une erreur comme celle ci-dessous.
> g++ main.o -o super_programme.out
main.o : Dans la fonction « main » :
main.cpp:(.text+0x27) : référence indéfinie vers « fonction() »
collect2: error: ld returned 1 exit status
> clang++ main.o -o super_programme.out
main.o : Dans la fonction « main » :
main.cpp:(.text+0x27) : référence indéfinie vers « fonction() »
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Schéma récapitulatif
Le processus de compilation d’un programme C++ peut sembler vraiment complexe quand on démarre. C’est vrai qu’il s’agit d’un domaine avancé, mais avoir une idée globale du processus et de ce qui se passe sous le capot est important. Voici donc un schéma, car une image vaut mieux que mille mots. 
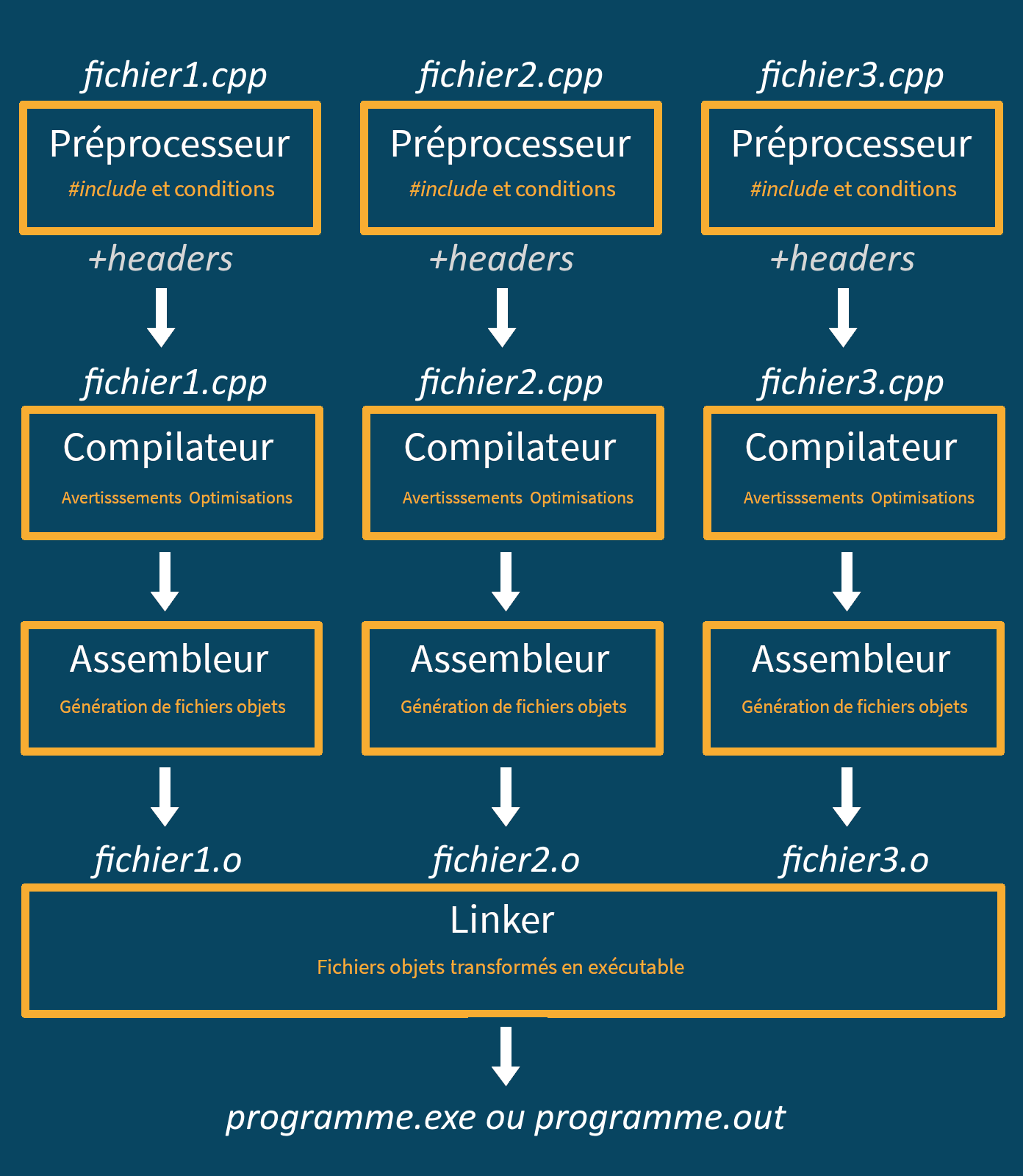
En résumé
- Le préprocesseur commence le travail en remplaçant chaque directive
#includepar le contenu du fichier demandé et en exécutant des tests conditionnels pour activer ou désactiver certains morceaux de code. - Le compilateur instancie les templates, exécute les fonctions
constexpr, vérifie la qualité de notre code puis, en plusieurs phases, transforme le code C++ en fichier objet. - Le linker fait le lien entre plusieurs fichiers objets pour résoudre des symboles manquants et achever le processus de compilation en générant un exécutable fonctionnel.
- Il n’est pas obligatoire de connaître chaque détail, mais avoir une vision globale est important.