Cette chère documentation est une des plus vieilles amies du développeur. Parfois très complète, parfois vraiment courte, parfois pas présente du tout (pas de bol), elle est là pour le guider, répondre à ses questions et lui apprendre comment utiliser tel ou tel type, ce qu’attend telle ou telle fonction, etc. Heureusement, dans notre cas, il existe une excellente documentation pour C++, en anglais certes (sachez que la version française est une traduction automatique), mais simple à comprendre. Et elle n’aura bientôt plus de secret pour vous. 
Nous allons apprendre à lire la documentation C++ ainsi qu’à écrire celle de nos programmes.
Lire une page de doc
À l’arrivée
Vous êtes donc sur la documentation et tant de liens vous laissent perplexes. Comment on s’y retrouve là-dedans ? Par où chercher l’information ? Le site étant classé en plusieurs parties, tout dépend de ce que vous cherchez. Certaines vont plus nous intéresser, dans le cadre de ce cours, que d’autres.
- Headers / Fichiers d’en-tête standard. Cette page recense tous les fichiers d’en-tête de la bibliothèque standard. Nous en reconnaissons plusieurs, comme
<iostream>,<string>ou<vector>. Ils sont classés par catégorie, en fonction de s’ils concernent la manipulation de chaînes de caractères, les conteneurs, etc. - String library / Chaînes de caractères. Ici, nous allons retrouver tout ce qui concerne le célèbre
std::string. - Containers library / Conteneurs. Ici, vous avez un lien direct vers tous les conteneurs qui existent. Vous reconnaitrez notamment
vector,arrayetlist. - Algorithms library / Algorithmes. Vous en connaissez certains, mais il en reste d’autres, tous listés ici.
Je vous cite ici les autres catégories, pour information et pour satisfaire votre curiosité débordante. 
- Utilities library. Correspond aux utilitaires pour gérer les types, la mémoire, les erreurs, les dates et temps, etc.
- Iterators library / Itérateurs. Vous connaissez déjà les itérateurs. Ici, on retrouve la documentation de tout ceux qu’on connait, plus bien d’autres encore.
- Numerics library / Numérique. C’est tout ce qui touche à la manipulation des nombres (complexes, aléatoires, etc).
- Input/output library / Entrées/sorties. On a déjà un peu manipulé, mais il reste encore beaucoup de choses.
- Localizations library / Internationalisation. Nous n’en parlerons pas, mais il y a ici des éléments permettant d’adapter son programme à d’autres langues et cultures.
- Filesystem library / Système de fichiers. Pour permettre la manipulation de dossiers et de fichiers de manière standard.
- D’autres encore, d’un niveau trop avancé pour être expliqués maintenant.
Au fur et à mesure que vous progresserez en C++ et gagnerez en autonomie, vous pourrez vous débrouiller seuls dans la documentation, car celle-ci est organisée de manière logique.
vector − Retour sur le plus célèbre des conteneurs
Présentation
Commençons en examinant la page dédiée à vector. Il y a une très grande quantité d’informations, mais toutes ne nous sont pas utiles. Commençons par lire à quoi ressemble un vector.
template<
class T,
class Allocator = std::allocator<T>
> class vector;
Vous reconnaissez la syntaxe des templates. Seulement, vous aviez l’habitude jusque là de déclarer des objets de type tableau de la manière suivante std::vector<int> tableau, alors qu’ici vous voyez qu’il y a deux types génériques attendus. C’est parce que le deuxième est renseigné avec une valeur par défaut.
Test le type des éléments.Allocatorest utilisé pour l’acquisition de la mémoire pour stocker les éléments.
On ne modifie le deuxième qu’en cas de besoins très particuliers, notamment quand on veut manipuler la mémoire d’une manière précise, donc pour nous, ça ne présente aucun intérêt. On laisse donc la valeur par défaut et on retrouve ainsi la syntaxe habituelle.
Les fonctions membres
Sautons plusieurs détails et passons directement à la section Member functions / Fonctions membres. Ici sont listées toutes les fonctions que l’on peut appliquer à un vector avec la syntaxe mon_vecteur.fonction(). Certaines vous sont familières, comme push_back ou clear. Si vous cliquez sur l’une d’elles, vous aurez tous les détails la concernant. Examinons ces deux exemples.
Chaque page de fonction présente d’abord tous les prototypes de la fonction. Comme vous le savez déjà, avec les surcharges, il peut exister plusieurs fonctions avec le même identificateur mais des paramètres différents. C’est le cas ici pour push_back. Si une fonction est apparue en même temps qu’une nouvelle norme de C++, ou si elle a été supprimée, cela est précisé à la fin de la ligne.
void push_back( const T& value ); (1)
void push_back( T&& value ); (2) (since C++11)
Dans le cas de la fonction push_back, nous avons deux surcharges, dont la deuxième n’est disponible qu’à partir de C++11.
La syntaxe du deuxième prototype doit vous surprendre. En effet, nous ne l’avons pas encore abordée. Nous le ferons plus loin dans le cours, mais sachez que, entre autres, la deuxième version est appelée quand vous lui donnez directement un littéral (push_back(5);), alors que si vous passez une variable, ça sera le premier prototype (int const a { 5 }; push_back(a);). Pour faire simple, cela permet d’optimiser le code lorsqu’il est appelé avec une valeur temporaire.
Les fonctions non-membres
Sur la page de std::vector, on trouve d’autres fonctions, dites non-membres. Celles-ci utilisent la syntaxe fonction(mon_vecteur), en opposition à ce que nous avons vu au sous-titre précédent mais en relation avec des fonctions que vous connaissez, comme std::size ou std::begin. C’est ici que vous trouverez la plupart des opérateurs surchargés, notamment.
On trouve, par exemple, std::swap, qui permet d’échanger le contenu de deux vecteurs, ou bien des opérateurs de comparaison.
Les paramètres
Revenons sur la page push_back. La sous-section Parameters y décrit les différents paramètres qu’une fonction attend. Rien de bien surprenant pour vous dans le cas de push_back, il s’agit simplement de la valeur à insérer. Ensuite, la sous-secton Return value décrit le résultat, qui, dans notre cas, n’existe pas puisque la fonction renvoie un void.
Les exceptions
Intéressons-nous maintenant à la section Exceptions. Comme vous le savez, C++ permet d’utiliser les exceptions et certaines fonctions de la bibliothèque standard le font. Cette section décrit le comportement attendu au cas où une fonction viendrait à lancer une exception. En effet, toutes ne réagissent pas de la même manière.
- Certaines ont une garantie forte (strong exception guarantee). Elles garantissent que, si une exception est levée, alors rien n’est modifié et tout reste comme avant le lancement de l’exception. C’est le cas de
push_back: si une exception est levée, alors le tableau reste inchangé. - D’autres ont une garantie basique (basic exception guarantee). Dans ce cas, la seule chose dont on est sûr, c’est qu’il n’y a pas de fuite de mémoire. Par contre, l’objet peut avoir été modifié.
- D’autres encore ont une garantie pas d’exception (no-throw guarantee). Aucune exception ne sera levée. Ces fonctions possèdent le mot-clef
noexceptdans leur prototype. C’est le cas de la fonctionemptypar exemple. - Enfin, il en existe qui n’ont aucune garantie (No exception safety). Tout peut se passer potentiellement. Ce genre de fonction est celle qui offre le moins de garantie et de protection.
Dans le cas où la fonction est noexcept, la section Exceptions peut être absente de la page de documentation. Cela dépend des cas.
noexceptSi une fonction spécifiée noexcept lève quand même une exception, la fonction std::terminate est appelée et celle-ci provoque un arrêt brutal du programme.
Exemple(s)
Enfin, la section Example / Exemple donne un cas d’utilisation concret de la fonction exposée. On peut même modifier et exécuter le code en cliquant sur Run this code.
Les algorithmes
Continuons notre apprentissage en nous rendant sur la page des algorithmes. Nous en connaissons déjà quelques-uns, ce qui va nous faciliter la compréhension de la documentation. Notez que les algorithmes sont eux-mêmes classés en sous-catégories, comme « Non-modifying sequence operations / Non modifiants », « Modifying sequence operations / Modifiants », « Sorting operations / Tri », etc. Au début de chaque sous-catégorie se trouve le fichier d’en-tête à inclure pour utiliser les algorithmes sous-cités.
Prenons l’exemple de std::sort, que vous connaissez déjà. Si vous le cherchez dans la page, vous le trouverez dans la catégorie « Sorting operations », puisqu’il s’agit d’un algorithme de tri. On note en haut que le fichier d’en-tête requis est <algorithm>. Maintenant que nous avons ces informations, nous pouvons nous rendre sur sa page.
Une fois là-bas, on remarque qu’il existe quatre signatures différentes, chacune étant ordonnée avec un numéro. La première est celle que nous connaissons le mieux, puisque nous l’avons déjà vue. On remarque que le prototype change en fonction de si l’on compile en C++20 ou antérieur. La différence réside dans le mot-clef constexpr, que je détaillerai plus tard.
template <class RandomIt>
void sort(RandomIt first, RandomIt last);
Le troisième lui ressemble, à ceci près qu’on a une possibilité de personnaliser l’algorithme de comparaison. Là encore, la seule différence entre pré-C++20 et post-C++20, c’est constexpr.
template <class RandomIt, class Compare>
void sort(RandomIt first, RandomIt last, Compare comp);
Les deux autres, à savoir le (2) et le (4), ont été introduits avec C++17 et permettent de traiter plusieurs instructions en parallèle plutôt que les unes à la suite des autres. C’est encore compliqué à notre niveau, donc je ne m’embêterai pas à les expliquer. De toute façon, à la fin de ce chapitre, vous aurez l’autonomie et les ressources nécessaires pour aller lire et pratiquer par vous-mêmes.
La section Parameters nous donne des indications supplémentaires sur les arguments attendus par std::sort. On y trouve notamment la forme que doit prendre la fonction transmise en paramètre de comp. Dans ce cas-ci, vous le saviez déjà, mais c’est dans cette section que vous trouverez la même info pour d’autres algorithmes.
Enfin, avant d’avoir un exemple en code, on nous informe que la fonction ne renvoie rien et qu’elle peut éventuellement lever une exception de type std::bad_alloc, nous indiquant par-là de quoi nous protéger.
Les chaînes de caractère au grand complet
Voici la page de documentation de std::string. Comme déjà dit lors de l’introduction de using, le type std::string est un alias d’un type basic_string, instancié pour les char. Ne vous étonnez donc pas en voyant la documentation.
Exemple de fonction membre
Vous pouvez voir, dans la section Member functions, tout un tas de fonctions que nous ne connaissions pas encore. Certaines sont familières, comme push_back ou find. D’autres nouvelles, comme insert, que nous allons étudier.
En regardant les différents prototypes proposés, on distingue pas moins de 11 signatures différentes. On peut insérer plusieurs fois un même caractère (1), on peut insérer une chaîne entière (2)(4), des morceaux de chaînes grâce aux itérateurs (8) ou à des index (5), etc. Chacune est détaillée plus bas, avec explication de chaque paramètre attendu.
Toutes ces fonctions peuvent lever des exceptions. La documentation cite std::out_of_range si on transmet un index plus grand que la taille de la chaîne (logique) et std::length_error si on tente de créer une trop grande chaîne. Dans tous les cas, on a une garantie forte.
Exemple de fonction non-membre
Comme pour std::vector, on a ici des opérateurs de comparaison, mais d’autres encore. Ainsi, quand nous concaténons deux chaînes en faisant "A"s + "B"s, nous faisons appel à operator+.
Exemple d’autres fonctions associées
Tout ce qui permet de convertir une chaîne de caractères en entiers ou réels (et vice-versa) est listé sur cette page. Ces fonctions ne font pas partie du type std::string, mais sont tellement liées qu’elles sont réunies au sein du même fichier d’en-tête. On retrouve ainsi stoi, stod et to_string.
Exercices
Pour que vous gagniez en autonomie et que vous soyez capables de vous débrouiller seuls dans la documentation, il faut que vous vous entraîniez. Le but de cette section d’exercices est donc que vous appreniez à chercher une information dans la documentation. C’est important, car vous n’aurez pas toujours un tutoriel pour vous expliquer quoi et où chercher.
Remplacer une chaîne de caractère par une autre
J’aimerais pouvoir remplacer un morceau d’une chaîne de caractères par un autre. Disons que je veux remplacer une portion commençant à un index précis et d’une longueur précises. Le code suivant devra être complété pour pouvoir s’exécuter.
#include <cassert>
#include <iostream>
#include <string>
int main()
{
std::string phrase { "J'aimerai annuler ce texte." };
std::string const mot { "remplacer" };
// Le code à écrire.
assert(phrase == "J'aimerai remplacer ce texte." && "Le texte n'a pas été modifié correctement.");
return 0;
}
Puisqu’on parle de chaînes de caractères, on va donc chercher du côté de basic_string. On remarque, dans la liste des fonctions disponibles, une certaine replace. Le premier prototype est justement celui qui répond à l’énoncé. On obtient donc ce qui suit.
#include <cassert>
#include <iostream>
#include <string>
int main()
{
std::string phrase { "J'aimerai annuler ce texte." };
std::string const mot { "remplacer" };
// Le code.
phrase.replace(10, 7, mot);
std::cout << phrase << std::endl;
assert(phrase == "J'aimerai remplacer ce texte." && "Le texte n'a pas été modifié correctement.");
return 0;
}
Norme d’un vecteur
Pour ceux qui ont quelques connaissances en vecteurs, vous savez comment en calculer la norme. Pour les autres, sachez que la norme d’un vecteur est « sa longueur » que l’on calcule simplement à l’aide de la formule suivante. Il me semble qu’il y a une fonction pour ça en C++, mais laquelle ?
Si est un vecteur de coordonnées , alors sa norme vaut .
#include <cassert>
int main()
{
int const x { 5 };
int const y { 12 };
int norme { 0 };
// Le code pour résoudre l'exercice.
assert(norme == 13 && "La norme d'un vecteur v(5;12) vaut 13.");
return 0;
}
Il faut chercher dans les fonctions mathématiques.
En parcourant la liste des fonctions contenues sur cette page de documentation, on note le triplet hypot, hypotf et hypotl. La description associée dit que ces fonctions calculent la racine carrée de la somme des carrées de deux nombres, soit . Bien que, de par son nom, cette fonction semble plutôt destinée à calculer une hypoténuse, elle se révèle quand même adaptée. La correction est toute simple.
#include <cassert>
#include <cmath>
int main()
{
int const x { 5 };
int const y { 12 };
int norme { 0 };
// Le code pour résoudre l'exercice.
norme = std::hypot(x, y);
assert(norme == 13 && "La norme d'un vecteur v(5;12) vaut 13.");
return 0;
}
Nombres complexes
Ah, les nombres complexes ! Saviez-vous que C++ permettait d’en utiliser ? Eh oui, je peux calculer la racine carrée de -1 si ça me chante. En fait non, c’est plutôt vous qui allez le faire. Que diriez-vous de faire ce calcul puis d’afficher la partie réelle puis la partie imaginaire du résultat ?
Vous devez chercher du côté de la page complex.
Alors, on arrive sur la fameuse page en question, où l’on découvre un nouveau type, complex. C’est un template, donc on va devoir lui passer un type, en l’occurrence double.
On voit ensuite, plus bas, la fonction sqrt, qui répond à la première partie de l’exercice. C’est une fonction non-membre, donc qui s’utilise en se préfixant de std::.
Plus haut, dans les fonctions membres, on voit real et imag, qui donnent respectivement la partie réelle et la partie imaginaire de notre résultat complexe. On a donc tout ce qu’il nous faut.
#include <complex>
#include <iostream>
int main()
{
auto resultat = std::sqrt(std::complex<double>{ -1, 0 });
std::cout << "La racine carrée de -1 donne (" << resultat.real() << ";" << resultat.imag() << "i)." << std::endl;
return 0;
}
Transformations
Vous connaissez déjà l’algorithme std::for_each, qui applique une opération sur chaque élément d’un conteneur. Mais imaginez que nous ne voulons pas modifier le tableau lui-même mais une copie. Est-ce possible ? À vous de trouver l’algorithme adapté.
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Voici une phrase longue que je veux en majuscules." };
std::string sortie { "" };
// L'algorithme à utiliser.
std::cout << sortie << std::endl;
return 0;
}
Qui dit algorithme dit bien souvent le fichier correspondant <algorithm>. C’est effectivement dedans que nous allons trouver ce qu’il nous faut et l’algorithme en question se nomme std::transform. Avez-vous écrit un code comme celui-ci ?
std::transform(std::begin(phrase), std::end(phrase), std::begin(sortie), [](char c) -> char
{
return std::toupper(c);
});
Si oui, alors vous n’avez pas bien lu la documentation. En effet, lancez ce programme et il plantera. Pourquoi ? Parce que la chaîne de sortie est vide, donc on ne peut pas modifier les éléments d’une chaîne vide puisqu’il n’y en a pas. La documentation apporte une précision.
std::transformapplies the given function to a range and stores the result in another range, beginning atd_first.
std::transform.Il faut que le conteneur de sortie ait la même taille que celui d’entrée. Ou, tout du moins, en théorie. Si vous lisez le code d’exemple situé en fin de page, vous allez remarquer la présence d’une fonction inconnue jusque-là : std::back_inserter. En lisant sa documentation, on apprend qu’elle créée un std::back_insert_iterator.
Qu’à cela ne tienne, allons lire la documentation de ce nouveau genre d’itérateur. Celle-ci nous donne une information très intéressante.
std::back_insert_iteratoris anLegacyOutputIteratorthat appends to a container for which it was constructed. The container’spush_back()member function is called whenever the iterator (whether dereferenced or not) is assigned to.
std::back_insert_iterator.Traduit, cela signifie qu’à chaque fois que l’itérateur est modifié, la fonction push_back du conteneur en question est appelée. C’est exactement ce qu’il nous faut pour notre conteneur de sortie vide. Voici donc le code final.
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Voici une phrase longue que je veux en majuscules." };
std::string sortie { "" };
std::transform(std::begin(phrase), std::end(phrase), std::back_inserter(sortie), [](char c) -> char
{
return std::toupper(c);
});
std::cout << sortie << std::endl;
return 0;
}
Cet exercice vous a semblé plus difficile ? C’était le cas. Quand on ne connait pas quelque chose, bien souvent, une seule page de documentation n’est pas suffisant. Il faut parfois faire des recherches complémentaires. Heureusement pour vous, la documentation C++ présente sur ce site est accompagnée d’exemples qui vous aideront à bien saisir les difficultés et particularités potentielles.
Documenter son code avec Doxygen
Vous commencez maintenant à vous débrouiller avec la documentation officielle de C++. C’est une très bonne chose, car savoir lire et comprendre une documentation est un gros atout en informatique, vu que la très grande majorité des langages et des programmes viennent avec la leur. Mais les vôtres alors ? C’est un peu vide n’est-ce-pas ? La suite logique serait donc d’apprendre à écrire la documentation de notre code.
Installation des outils
Cela va se faire en utilisant un outil appelé Doxygen. Pour l’installer sur Windows, rendez-vous sur la page des téléchargements et prenez la dernière version disponible. Pour les utilisateurs de GNU/Linux, regarder dans vos dépôts. Le paquet devrait s’appeler doxygen, accompagné ou non de doxygen-doxywizard1. Une fois ceci fait, nous allons utiliser le Doxygen Wizard, l’interface graphique pour lancer la génération de la documentation.
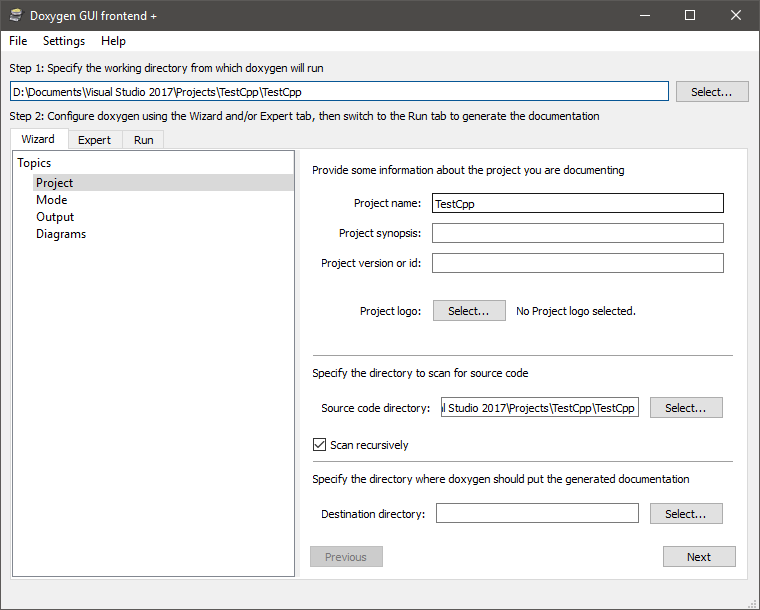
La première étape est de définir le chemin de sortie, là où la documentation sera écrite. Personnellement, je la mets dans le même dossier que le code, mais vous êtes libres de faire comme vous le souhaitez.
Ensuite, on s’assure qu’on est bien sur l’onglet « Wizard » où l’on va pouvoir configurer plusieurs options. Les trois premiers champs sont facultatifs, mais permettent de définir le nom du projet, son but et son numéro de version, dans le cas où il y aura plusieurs versions du programme et donc de la documentation disponibles. Vous pouvez vous amuser à mettre un logo aussi.
Il faut ensuite préciser où se situe le code source exactement. Dans mon cas, il est dans le même dossier qu’indiqué plus haut, mais dans d’autres, il peut être rangé dans un sous-dossier. Mettez le chemin du dossier qui contient votre code source.
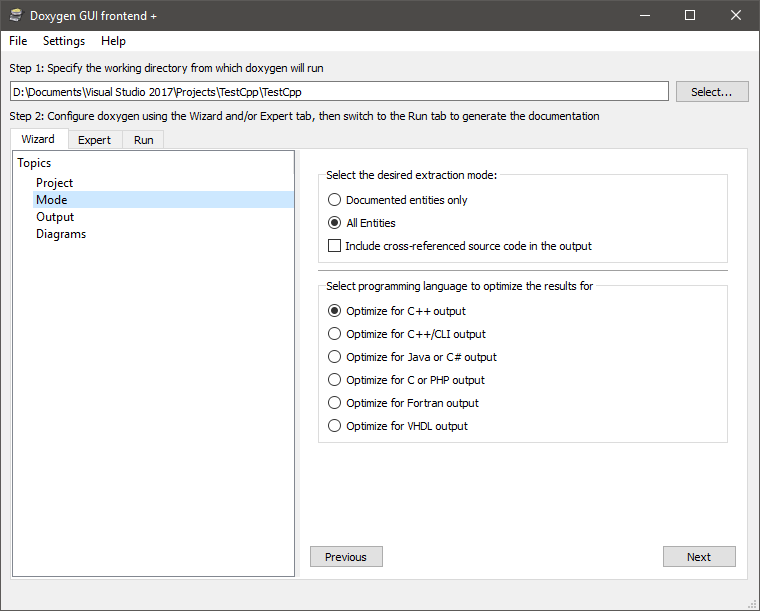
La deuxième étape est celle nommée « Mode », où l’on va indiquer que c’est du C++ (sélectionner Optimize for C++ output) et qu’on veut tout extraire (sélectionner All Entities).
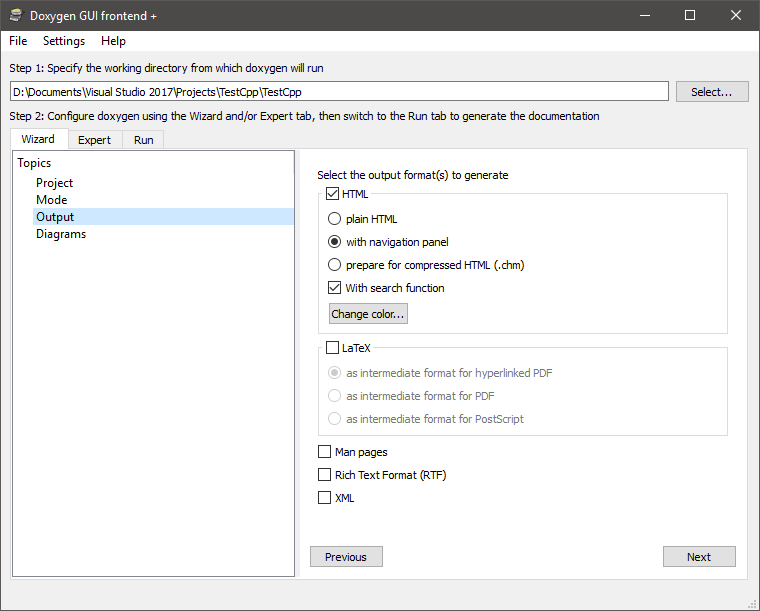
Dans la troisième étape, « Output », ne cochez que HTML et sélectionnez with navigation panel, parce que les autres options de sortie ne nous intéressent pas.
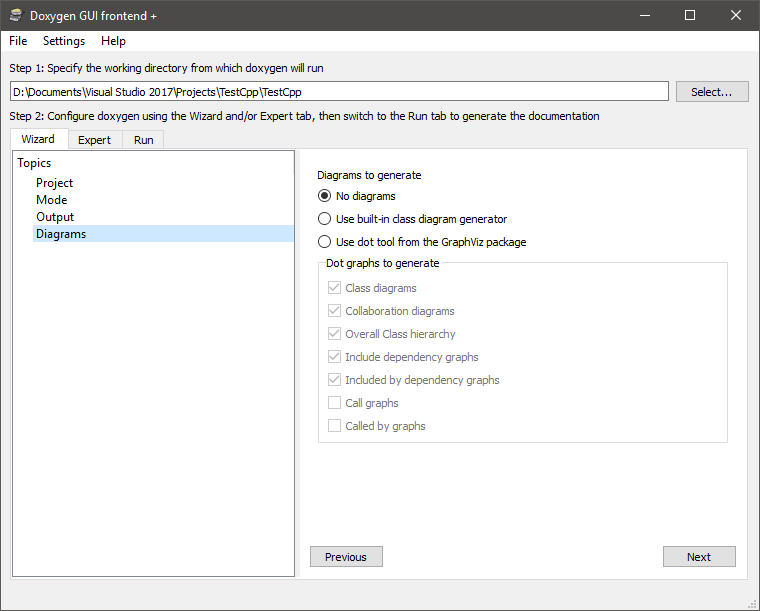
Enfin, dernière étape, « Diagrams », sélectionnez No diagrams et tout est bon. On peut passer à l’onglet « Run », d’où nous allons lancer la génération de la documentation en cliquant sur Run doxygen. Une fois cette étape faite, un dossier html sera présent.
En quittant l’application DoxyWizard, on vous demandera, si vous souhaitez sauvegarder cette configuration quelque part. Quand vous relancerez l’application, il suffira de recharger cette configuration pour gagner du temps.
Par défaut, la documentation est générée en anglais, mais vous pouvez mettre la langue de votre choix en cliquant sur Expert, puis Project. Là, mettez l’option OUTPUT_LANGUAGE à la valeur que vous décidez, French pour le français.
Écrire la documentation
Mais concrètement, comment on écrit la documentation ? En utilisant des balises spéciales, que Doxygen comprendra et qu’il traitera de façon appropriée. Ainsi, on a des attributs spéciaux pour décrire les arguments d’une fonction, sa valeur de retour, la présence de bugs, etc. La liste est longue, donc je n’en décrirai que certains. Libre à vous d’explorer la documentation de Doxygen pour découvrir les autres.
À noter également qu’on peut utiliser le Markdown2 dans les blocs de commentaire, pour entourer un morceau de code, mettre en gras, etc.
Comment fait-on ? Plusieurs façons de faire sont possibles ; j’ai fait le choix de vous en montrer deux. D’abord, soit la forme /** Commentaire */, soit la forme /// Commentaire. On retrouve ici un parallèle avec les commentaires /* */ et //. C’est une question de choix. Personnellement, quand le commentaire fait plus d’une ligne, j’utilise la forme longue /** */, sinon les trois slashs ///.
Description d’une fonction
Et si nous reprenions notre fonction d’entrée sécurisée pour illustrer cette partie ? Je vous remets ci-dessous la dernière version, utilisant les templates.
template <typename T, typename Predicat>
void entree_securisee(T & variable, Predicat predicat)
{
while (!(std::cin >> jour) || !predicat(variable))
{
if (std::cin.eof())
{
throw std::runtime_error("Le flux a été fermé !");
}
else if (std::cin.fail())
{
std::cout << "Entrée invalide. Recommence." << std::endl;
std::cin.clear();
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
}
else
{
std::cout << "Le prédicat n'est pas respecté !" << std::endl;
}
}
}
Une des premières choses que nous voulons faire, c’est d’expliquer ce que fait la fonction, la raison de son existence. Pour cela, Doxygen fournit deux attributs.
@briefsert à décrire brièvement la fonction. En une ou deux phrases, on décrit la fonction et ce qu’elle fait.@detailssert à décrire en détails la fonction. Ici, on entre dans les détails, en expliquant ce qu’elle fait, ce qu’elle ne fait pas, les exceptions qu’elle peut lever potentiellement, etc.
Appliquons donc ce que nous venons d’apprendre à notre code. J’ai écrit un certain texte, mais vous pouvez très bien mettre le vôtre.
/**
* @brief Saisie sécurisée avec `std::cin`.
* @details Vérifie que la variable demandée est du bon type et respecte un prédicat donné.
* En cas de fermeture du flux d'entrée, une exception `std::runtime_error` est levée.
* En cas de type invalide, le flux d'entrée est vidé.
* En cas de prédicat non respecté, un message d'erreur est affiché sur la sortie standard.
*/
template <typename T, typename Predicat>
void entree_securisee(T & variable, Predicat predicat)
{
// Le code qui ne change pas.
}
Si vous naviguez dans les fichiers HTML créés, vous allez trouver, dans la documentation du fichier C++ où se trouve la fonction (main.cpp par exemple), un encart présentant la fonction avec sa signature, une description courte puis une plus détaillée.
Les paramètres
Maintenant, attaquons un autre morceau très important, à savoir la description des paramètres. Il est important que l’utilisateur sache ce que signifie chaque paramètre et s’il y a des préconditions à respecter. Ça tombe bien, on a des attributs spécifiques pour ça.
@param[type] paramètrepermet de décrire un paramètre de manière générale. Le type entre crochet peut prendre trois valeurs :insi le paramètre est une valeur lue mais non modifiée par la fonction,outsi le paramètre est modifié par la fonction etin,outdans le cas où le paramètre est lu mais également modifié.@predécrit une précondition par ligne. Si plusieurs attributs@presont présents les uns après les autres, ils sont regroupés dans un même bloc à la sortie.@postdécrit une postcondition par ligne. Si plusieurs attributs@postsont présents les uns après les autres, ils sont regroupés dans un même bloc à la sortie.- Parce que les templates n’échappent pas à la règle,
@tparam paramètrepermet de faire la même opération pour nos chers patrons.
Ceci appliqué à notre code, on obtient quelque chose comme ci-dessous. Pareil, le texte que vous avez mis peut varier.
/**
* @brief Saisie sécurisée avec `std::cin`.
* @details Vérifie que la variable demandée est du bon type et respecte un prédicat donné.
* En cas de fermeture du flux d'entrée, une exception `std::runtime_error` est levée.
* En cas de type invalide, le flux d'entrée est vidé.
* En cas de prédicat non respecté, un message d'erreur est affichée sur la sortie standard.
*
* @tparam T Le type de la valeur à récupérer.
* @tparam Predicat Un prédicat à passer pour personnaliser la vérification.
*
* @param[out] variable Une référence sur la variable de type `T` à récupérer.
* @param[in] predicat Un prédicat que l'entrée saisie doit respecter.
*
* @pre Le type `T` doit être utilisable avec `std::cin`.
* @pre Le prédicat doit être de la forme `bool predicat(T variable)`.
* @post La variable sera initialisée correctement avec la valeur entrée.
*/
template <typename T, typename Predicat>
void entree_securisee(T & variable, Predicat predicat)
{
// Le code qui ne change pas.
}
Les exceptions
Notre fonction peut lever des exceptions, que ce soit parce que nous en lançons nous-mêmes explicitement, ou bien parce qu’une des fonctions appelées lance une exception en interne. Il est donc de bon ton de décrire ce qui peut potentiellement arriver. Bien sûr, être totalement exhaustif est impossible. Mais décrire les exceptions que nous lançons explicitement est une bonne habitude à prendre. Cela se fait très simplement avec l’attribut @exception exception_lancée.
/**
* @brief Saisie sécurisée avec `std::cin`.
* @details Vérifie que la variable demandée est du bon type et respecte un prédicat donné.
* En cas de fermeture du flux d'entrée, une exception `std::runtime_error` est levée.
* En cas de type invalide, le flux d'entrée est vidé.
* En cas de prédicat non respecté, un message d'erreur est affiché sur la sortie standard.
*
* @tparam T Le type de la valeur à récupérer.
* @tparam Predicat Un prédicat à passer pour personnaliser la vérification.
*
* @param[out] variable Une référence sur la variable de type `T` à récupérer.
* @param[in] predicat Un prédicat que l'entrée saisie doit respecter.
*
* @pre Le type `T` doit être utilisable avec `std::cin`.
* @pre Le prédicat doit être de la forme `bool predicat(T variable)`.
* @post La variable sera initialisée correctement avec la valeur entrée.
*
* @exception std::runtime_error Si le flux d'entrée est fermé.
*/
template <typename T, typename Predicat>
void entree_securisee(T & variable, Predicat predicat)
{
// Le code qui ne change pas.
}
Le type de retour
Nous n’en avons pas dans notre cas, car la fonction entree_securisee ne retourne rien. Certains aiment utiliser l’attribut @returns même dans ce cas, d’autres jugent que c’est inutile. Je vous laisse choisir. Voici néanmoins un exemple d’utilisation de cet attribut, avec une fonction que nous avions écrite dans le chapitre consacré (et légèrement modifiée).
/** @brief Détermine si une expression est correctement parenthésée.
* @details La fonction regarde si on a bien le même nombre de parenthèses
* ouvrantes et fermantes et si celles-ci sont bien ordonnées.
*
* @param[in] expression Une chaîne de caractères à analyser.
*
* @returns `true` si l'expression est bien parenthésée, `false` sinon.
*/
bool parentheses(std::string const & expression)
{
int ouvrantes { 0 };
int fermantes { 0 };
for (auto const & caractere : expression)
{
if (caractere == '(')
{
++ouvrantes;
}
else
{
++fermantes;
}
if (fermantes > ouvrantes)
{
return false;
}
}
return ouvrantes == fermantes;
}
D’autres attributs utiles
Terminons cet aperçu des attributs de documentation d’une fonction en en présentant quelques-uns qui permettent de signaler des informations supplémentaires, ne rentrant pas dans le cadre des attributs vus plus haut. Il arrive, par exemple, qu’on veuille signaler la présence d’un bug encore non corrigé ou rarissime, d’une modification ou amélioration prévue mais pas encore faite, d’un avertissement concernant un aspect particulier du code, etc.
@bugsert à décrire la présence d’un bug dans le code. Cet attribut aurait pu, par exemple, être utilisé dans les anciens T.P où nous ne pensions pas à prendre en compte la fermeture potentielle du flux. On aurait pu ajouter un commentaire du type@bug Si le flux est fermé, la fonction rentre dans une boucle infinie.@todosert à décrire une action à faire plus tard. On pourrait s’en servir pour se rappeler, dans notre T.P, de mettre à jour le code pour utiliser un flux d’entrée générique à la place destd::cin.@notepermet d'ajouter des informations génériques. Si votre code implémente une fonction mathématique, vous aurez peut-être envie de l’écrire clairement. Ce bloc est tout à fait adapté à ça.@warningpermet d'ajouter des avertissements. On peut vouloir prévenir, par exemple, qu’une fonction ne doit pas être utilisée en même temps qu’une autre, où bien qu’un paramètre doit être d’abord correctement initialisé sous peine de voir le programme planter.
Les structures et les énumérations
Bien évidemment, il ne faut pas oublier de commenter nos types personnalisés. Non seulement le type lui-même, mais chacun des champs. Pour cela, nous disposons des attributs @struct et @enum. Chacun fonctionne sur le même principe.
- D’abord, on écrit l’attribut puis le nom du type.
- Ensuite, une description brève.
- Enfin, une description plus détaillée.
De même, chaque champ peut faire l’objet de description courte, détaillée, d’avertissements, etc. En général, seul une description succincte est nécessaire. Examinez par vous-mêmes un exemple de structure et d’énumération documentées.
/** @enum Couleur
* @brief Liste des couleurs possibles.
* @details La liste des trois couleurs applicables à l'écran de fond du programme.
*/
enum class Couleur
{
/// @brief Un bleu profond.
Bleu,
/// @brief Un rouge vif.
Rouge,
/// @brief Un vert magnifique.
Vert
};
/** @struct InformationsPersonnelles
* @brief Les informations personnelles d'un membre.
* @details Permet de stocker, sous un même type, le nom/prénom ainsi que le genre et l'âge d'un membre.
* Il n'y a pas de limite à la taille du nom ou du prénom du membre.
*/
struct InformationsPersonnelles
{
/// @brief Le prénom du membre.
std::string prenom;
/// @brief Le nom de famille du membre.
std::string nom;
/// @brief Femme ou homme ?
std::string sexe;
/// @brief L'âge du membre.
int age;
};
Quelques bonnes pratiques
Vous savez maintenant documenter votre code et c’est une excellente chose. Une bonne documentation fait gagner du temps et est la meilleure alliée d’un développeur découvrant un nouveau code. Mais doit-on tout documenter ? Absolument tout ? Y a t-il des bonnes pratiques ?
Ce qu’il faut documenter
Dans l’idéal, toutes vos fonctions devraient être documentées. Utilisez Doxygen pour détailler vos fonctions, leur utilisation, ce qu’elles attendent, les exceptions qu’elles peuvent lancer, etc. C’est assez fastidieux, je vous l’accorde. Mais ne pas le faire est une très mauvaise pratique. Qui n’a jamais pesté contre un appareil qu’il a dû utiliser sans manuel ni instructions ? Si quelqu’un vient à utiliser votre code, il n’aimera pas non plus avoir à deviner ce que celui-ci fait, les exceptions qu’il lance, etc.
Mais si je suis seul, c’est pas un peu inutile ?
Cela vous servira même si vous êtes seul. Ne croyez pas que vous vous souviendrez de ce que font vos 4000 lignes de code quand vous rouvrirez le projet après plusieurs mois d’absence s’il n’y a pas de documentation. Ce qui vous semble clair maintenant ne le sera peut-être pas plus tard. Épargnez-vous des problèmes, documentez. Pour ne pas vous démotiver face à l’immensité de cette tâche, commencez tôt et faites en petit à petit. Ainsi, tandis que votre base de code augmentera, elle sera bien documentée et facile à comprendre.
Les fichiers d’en-tête ou source ?
Nous n’aimons pas la recopie. C’est une source d’erreurs et d’incompréhensions. Imaginez que la documentation d’un prototype dans un fichier d’en-tête soit légèrement différente de celle de son implémentation dans le fichier source. Qui a raison ? Qui est à jour ? Un vrai nœud à problèmes que de maintenir deux fois la même documentation à jour.
Heureusement, Doxygen est assez intelligent et affiche la documentation du fichier d’en-tête même si on demande à voir celle du fichier source. Il comprend qu’on a affaire aux mêmes fonctions, avec d’un côté le prototype et de l’autre l’implémentation.
Exemple
Parfois, certaines fonctions sont assez compliquées à utiliser et avoir un exemple fonctionnel sous les yeux nous aide vraiment. Vous-mêmes l’avez certainement remarqué en vous plongeant dans la documentation C++. Un exemple, ça aide. Voilà pourquoi j’ai choisi de séparer cette section du reste de la présentation de Doxygen, pour que vous compreniez bien que c’est important.
Une façon de faire consiste à utiliser l’attribut @note, pour bien différencier des autres sections, puis à écrire un petit exemple entre les attributs @code et @endcode.
/** @brief Détermine si une expression est correctement parenthésée.
* @details La fonction regarde si on a bien le même nombre de parenthèses
* ouvrantes et fermantes et si celles-ci sont bien ordonnées.
*
* @param[in] expression Une chaîne de caractères à analyser.
*
* @returns `true` si l'expression est bien parenthesée, `false` sinon.
*
* @note Voici un exemple d'utilisation.
* @code
* std::string const test { "((()))" };
* parentheses(test);
* @endcode
*/
bool parentheses(std::string const & expression)
{
// Implémentation.
}
Commentaire vs documentation
La découverte et l’utilisation de Doxygen signifie t-elle la fin des commentaires comme nous avions appris dès le chapitre introductif à C++ ? Bien sûr que non. En fait, les deux ne sont pas opposés, simplement, les commentaires ne servent pas les mêmes buts.
La documentation a pour but d’être, si possible, exhaustive et de décrire le quoi, le comment. On s’en sert pour expliquer ce que fait une fonction, les paramètres qu’elle attend, ce qu’elle renvoie, les exceptions qu’elle peut lever, ses contrats, etc. On s’en sert aussi pour illustrer le fonctionnement du code par des exemples, comme vu plus haut. Si la documentation est bien faite, un développeur n’aura jamais besoin d’aller lire le code source pour comprendre.
Les commentaires eux, sont plutôt à usage interne et expliquent le pourquoi. On s’en sert pour expliciter ce que le code ne dit pas, pour décrire les raisons qui ont poussé à faire ou ne pas faire telle ou telle chose. Ils seront donc moins présents certes, mais pas moins utiles.
De bons commentaires…
Par exemple, on peut vouloir expliquer le choix d’une structure de données qui sort de l’ordinaire. Vous rappelez-vous de std::map et std::unordered_map ? La deuxième est souvent choisie pour des raisons de performances. Ainsi, vous voudrez peut-être expliquer pourquoi vous avez choisi la première avec un bref commentaire.
// Utilisation de `std::map` car les clés doivent rester triées dans l'ordre.
using Data = std::map<std::string, int>;
On peut aussi s’en servir pour justifier un code un peu sale ou exotique.
int const x { 0 };
// Le +1 est nécessaire car fonction_externe est bugué quand x vaut 0.
int resultat { fonction_externe(x) + 1 };
De la même manière, si vous voulez tester si un nombre est premier ou pas, vous pouvez appliquer une astuce consistant à ne tester que de 2 à . Cela peut faire l’objet d’un commentaire explicatif.
int const N { 24 };
bool est_premier { true };
// On ne teste que jusqu'à racine de N pour gagner du temps.
for (int i { 2 }; i < std::sqrt(N); ++i)
{
if (N % i == 0)
{
est_premier = false;
break;
}
}
Ces commentaires sont utiles, car seulement en lisant le code, vous n’auriez pas compris pourquoi il a été écrit de cette façon.
…et de mauvais commentaires
Malheureusement, ce qu’on voit le plus souvent, ce sont les mauvais commentaires. Que ce soit parce qu’ils se contentent de redire ce que dit déjà le code, parce que le code est mal écrit, ou bien encore parce qu’ils ne sont pas clairs, le fait est qu’ils n’apportent rien de bon. Un exemple ? La plupart des commentaires écrits dans ce cours répètent ce que le code dit. Bien sûr, dans votre cas, c’est nécessaire car vous êtes en plein apprentissage. Par contre, pour des développeurs chevronnés, ce genre de commentaires est inutile.
Un autre type de commentaire problématique, c’est celui qui explique le code parce que celui-ci n’est pas clair. Regardez la façon dont cela est illustré dans l’exemple suivant.
// Si la vie atteint une valeur critique (<100).
if (vie < 100)
{
// Du code.
}
Le code pourrait être amélioré en utilisant une constante, ce qui supprimerait le commentaire au passage.
int const niveau_vie_critique { 100 };
// ...
if (vie < niveau_vie_critique)
{
// Du code.
}
Dans le même genre, les commentaires signalant une accolade fermante, ceux signalant la date de dernière modification, ceux retraçant l’historique des modifications d’un fichier, tout ça fait partie des commentaires qui n’ont pas lieu d’être.
La distinction peut vous sembler dur à comprendre et la frontière entre un bon et un mauvais commentaire peut paraître bien mince. Une littérature informatique abondante aborde ce sujet, que nous ne pouvons, dans le cadre de ce cours, parcourir exhaustivement. Si vous souhaitez aller plus loin, un chapitre du livre Coder proprement y est dédié.
En résumé
- La documentation est une des meilleures amies du développeur.
- La documentation C++ est classée en divers thèmes, allant du langage lui-même aux algorithmes, en passant par
std::stringet les fonctions mathématiques. - On retrouve souvent les mêmes sections, décrivant les différents prototypes, les paramètres, les exceptions possibles, ainsi que des exemples concrets.
- Doxygen nous permet d’écrire la documentation de nos programmes. C’est une bonne habitude à prendre.
- Certaines bonnes pratiques peuvent nous aider à écrire des commentaires et de la documentation de qualité.