Depuis que nous avons commencé ce cours, nous avons étudié deux conteneurs très utiles, std::vector, qui est un tableau dynamique, et std::array, un tableau statique. Nous avons appris qu’on peut accéder à un élément grâce aux crochets []. Cette solution n’est pourtant pas très générique, puisque avec d’autres conteneurs C++, comme std::list, les crochets ne sont pas disponibles.
Ce chapitre va donc introduire une solution générique à ce problème qui porte le nom d’itérateurs, largement employés dans la bibliothèque standard, notamment avec les algorithmes.
Le socle de base : les itérateurs
Qu’est-ce qu’un itérateur ? Littéralement, il s’agit de quelque chose dont on se sert pour itérer. Dans notre cas, c’est sur des conteneurs que nous voulons itérer. Et qui dit concept de boucle, dit accès aux éléments un par un. Nous avons vu plus tôt les crochets [] avec std::array et std::vector. Il s’agit ici du même concept, mais encore plus puissant, car totalement indépendant du conteneur utilisé !
Un itérateur peut accomplir ceci puisque il sait à quel endroit de la séquence regarder. On dit que l’itérateur est un curseur sur l’élément. Et en se déplaçant d’emplacement en emplacement, il peut ainsi parcourir l’ensemble d’une collection de données.
Déclaration d’un itérateur
Pour déclarer un itérateur, rien de plus simple, vous connaissez déjà la moitié de la syntaxe. Schématiquement, le code ressemblera à ça. Notez que le type de l’identificateur doit correspondre à celui du conteneur associé : on ne peut pas utiliser un itérateur de std::vector<double> pour parcourir un std::vector<char>.
// Dans le cas d'un conteneur modifiable.
std::/* Le conteneur utilisé. */::iterator identificateur { /* L'élément sur lequel pointer. */ };
// Dans le cas d'un conteneur const.
std::/* Le conteneur utilisé. */::const_iterator identificateur { /* L'élément sur lequel pointer. */ };
Pour raccourcir le code et se simplifier la vie, on peut bien entendu faire appel à l’inférence de type, à l’aide d'auto. C’est ce que je vais faire dans le reste de ce cours.
auto identificateur { /* L'élément sur lequel pointer. */ };
Début et fin d’un conteneur
Notez, dans la déclaration précédente, le commentaire /* L'élément sur lequel pointer. */. Deux fonctions, dans un premier temps, vont nous intéresser : std::begin, un curseur vers le premier élément du conteneur, et std::end, un curseur vers un élément virtuel inexistant, qui se trouve après le dernier élément.
Pourquoi ne pas pointer vers le dernier élément de la collection plutôt ?
Pour une raison simple : comment faites-vous donc pour déterminer que vous êtes à la fin de la collection ? En effet, si std::end pointe vers l’adresse en mémoire d’un élément valide de la collection, qu’est-ce qui vous prouve que vous êtes à la fin ? C’est pour cela que std::end renvoie un itérateur sur un élément inexistant, qui indique la fin de la collection.
#include <vector>
int main()
{
std::vector<int> const tableau { -1, 28, 346 };
// Déclaration explicite d'un itérateur de std::vector d'entiers.
std::vector<int>::const_iterator debut_tableau { std::begin(tableau) };
// Déclaration plus courte en utilisant auto.
auto fin_tableau { std::end(tableau) };
return 0;
}
Accéder à l’élément pointé
Nous savons comment pointer vers le premier élément de la collection, ainsi que signaler sa fin, mais ça ne nous avance pas vraiment. Il nous manque l’accès aux éléments. Pour cela, il faut déréférencer l’itérateur, grâce à l’étoile * devant celui-ci. L’exemple suivant affiche la valeur sur laquelle pointe l’itérateur, c’est-à-dire le premier élément du tableau, ici T.
#include <iostream>
#include <string>
int main()
{
std::string tableau { "Tu texte." };
auto debut_tableau { std::begin(tableau) };
// On affiche le premier élément du tableau.
std::cout << *debut_tableau << std::endl;
// Et on peut même le modifier, comme ce qu'on fait avec les références, ou les crochets.
*debut_tableau = 'D';
// On vérifie.
std::cout << tableau << std::endl;
return 0;
}
std::end !Ne tentez pas de déréférencer std::end ! Vous accéderiez à un espace mémoire inconnu, ce qui entraînera un comportement indéterminé, donc tout et n’importe quoi potentiellement. Je répète, ne tentez pas d’accéder à la valeur pointée par std::end, ni de la modifier.
Se déplacer dans une collection
Déplacement vers l’élément suivant
Maintenant que nous sommes capables d’afficher le premier élément, il serait bien de faire de même avec les autres. Nous pouvons, à partir d’un itérateur sur un élément, récupérer l’adresse de l’élément suivant en appliquant l’opérateur d’incrémentation ++.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> tableau { -1, 28, 346 };
auto debut_tableau { std::begin(tableau) };
std::cout << *debut_tableau << std::endl;
// On incrémente l'itérateur pour pointer sur l'élément suivant.
++debut_tableau;
// On affiche le deuxième élément.
std::cout << *debut_tableau << std::endl;
return 0;
}
Utilisation concrète
Nous avons maintenant tout ce qu’il nous faut pour afficher l’ensemble d’une collection. L’exemple suivant vous montre comment parcourir un conteneur à l’aide d’une boucle for classique et d’itérateurs. Vous noterez l’utilisation d’un identifiant it, qui est l’équivalent de i quand nous avions vu les boucles.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> tableau { -1, 28, 346, 84 };
for (auto it { std::begin(tableau) }; it != std::end(tableau); ++it)
{
std::cout << *it << std::endl;
}
return 0;
}
Déplacement vers l’élément précédent
La plupart des conteneurs fournissent aussi l’opération inverse, c’est-à-dire récupérer l’adresse de l’élément précédent, grâce à l’opérateur de décrémentation --. Cet opérateur va, par exemple, nous permettre de récupérer le dernier élément d’un conteneur et l’afficher.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> tableau { -1, 28, 346, 84 };
auto iterateur_dernier_element { std::end(tableau) };
// On récupère l'adresse de l'élément précédent.
--iterateur_dernier_element;
// Et on affiche pour vérifier.
std::cout << *iterateur_dernier_element << std::endl;
return 0;
}
Se déplacer de plusieurs éléments
Admettons que vous vouliez vous déplacer de plusieurs éléments, disons pour récupérer le cinquième. N’y a-t-il pas un autre moyen que d’utiliser cinq fois l’opérateur ++ ? La réponse dépend du conteneur que vous utilisez. En effet, en fonction de celui-ci, les itérateurs derrières ne proposent pas exactement les mêmes fonctionnalités.
Les conteneurs comme std::vector, std::array ou std::string, que nous avons découvert plut tôt dans ce tutoriel, sont ce qu’on appelle des conteneurs à accès direct (random access en anglais), c’est-à-dire qu’on peut accéder directement à n’importe quel élément. Cela est vrai en utilisant les crochets [] (c’est même à leur présence qu’on reconnait qu’un conteneur est à accès direct), et c’est également vrai pour les itérateurs. Ainsi, on peut directement écrire ceci quand on utilise un conteneur à accès direct.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> tableau { -1, 28, 346, 84, -94, 31, 784 };
// Notez le +4 pour accéder au cinquième élément, car comme avec les crochets, on commence à 0.
auto iterateur_cinquieme_element { std::begin(tableau) + 4 };
std::cout << *iterateur_cinquieme_element << std::endl;
return 0;
}
Il existe d’autres conteneurs, comme std::list, qui sont dit bidirectionnels, parce qu’ils autorisent le déplacement vers un élément précédent ou suivant, mais pas plusieurs d’un coup. Si vous remplacez, dans le code précédent, std::vector par std::list, vous verrez qu’il ne compilera pas.
Il existe, dans la bibliothèque standard, cinq types différents d’itérateurs. Nous en avons déjà vu deux ici. Nous aurons l’occasion de voir les trois autres au fur et à mesure que nous progresserons dans le cours.
const et les itérateurs
Le concept d’itérateur réclame des explications supplémentaires concernant l’utilisation de const. En effet, avec les itérateurs, on distingue la constance de l’itérateur lui-même de la constance de l’objet pointé. Pour parler plus concrètement, appliquer const à un itérateur rend celui-ci constant, c’est-à-dire qu’on ne peut pas, une fois assigné, le faire pointer sur autre chose. Par contre, la valeur pointée est tout à fait modifiable.
#include <string>
#include <iostream>
int main()
{
std::string mot { "Donjour" };
// Itérateur constant sur un élément modifiable.
auto const it { std::begin(mot) };
// Ceci est impossible.
// it = std::end(mot);
// Ceci est parfaitement autorisé.
*it = 'B';
std::cout << mot << std::endl;
return 0;
}
Pour garantir la constance des éléments pointés, on va utiliser deux fonctions très proches de celles vues plus haut. Il s’agit de std::cbegin et de std::cend, pour const begin et const end. L’exemple suivant vous montre la différence.
#include <string>
int main()
{
std::string mot { "Donjour" };
// Itérateur constant sur un élément modifiable.
auto const iterateur_constant { std::begin(mot) };
// Ceci est impsosible.
// it = std::end(mot);
// Ceci est parfaitement autorisé.
*iterateur_constant = 'B';
auto iterateur_non_constant { std::cbegin(mot) };
// Ceci est impossible.
// *iterateur_non_constant = 'D';
// Ceci est parfaitement autorisé.
iterateur_non_constant = std::cend(mot) - 1;
return 0;
}
On peut, bien entendu, combiner les deux formes pour obtenir un itérateur constant sur un élément constant.
Itérer depuis la fin
Il existe encore une troisième paire de fonctions, qui vont nous autoriser à parcourir une collection de la fin vers le début. Elles se nomment std::rbegin (reverse begin) et std::rend (reverse end). Elles s’utilisent exactement comme les précédentes, leur utilisation est transparente. 
#include <iostream>
#include <vector>
int main()
{
std::vector<int> const tableau { -1, 28, 346, 84 };
// Affiche depuis la fin, en commençant par 84.
for (auto it { std::rbegin(tableau) }; it != std::rend(tableau); ++it)
{
std::cout << *it << std::endl;
}
return 0;
}
Et comme pour les autres, les itérateurs peuvent être déclarés comme constant avec std::crbegin et std::crend.
Pourquoi avoir des itérateurs spéciaux ? Pourquoi ne pas partir de std::end et itérer jusqu’à std::begin ?
Pour vous répondre, je vais utiliser une illustration qu’a créé @gbdivers dans son cours C++, comme la licence m’y autorise.
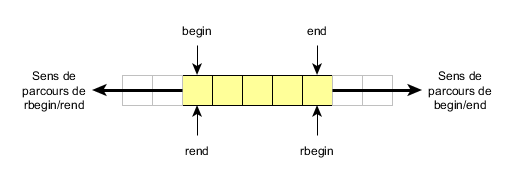
Si l’on part de std::end, on va se déplacer vers la droite et jamais l’on ne retombera sur std::begin ; le programme plantera bien avant. Voilà pourquoi il existe des itérateurs spécialement conçus pour parcourir une collection de la fin vers le début.
Alors, pourquoi ne pas partir de la fin et aller vers le début en décrémentant ?
Vous pourriez… mais ça serait tellement plus pénible. Il faudrait gérer les cas spéciaux que sont la valeur de début et la valeur de fin. Ou bien réécrire tous les algorithmes pour prendre en compte la décrémentation. Ou bien… utiliser std::rbegin et std::rend de manière totalement transparente.
Utilisation conjointe avec les conteneurs
Terminons cette section en présentant une possibilité d’initialisation des conteneurs qui nous était inconnue jusque-là. Grâce aux itérateurs, nous pouvons facilement créer des sous-ensembles à partir d’une collection d’éléments, comme un tableau qui ne contiendrait que les éléments 2 à 5 d’un autre tableau. Cela se fait très simplement : il suffit de donner en argument, entre accolades {}, l’itérateur de début et l’itérateur de fin.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> collection { 1, -8, 4, 654, -7785, 0, 42 };
// On passe l'itérateur de début et celui de fin.
std::vector<int> sous_ensemble { std::begin(collection) + 1, std::begin(collection) + 5 };
// On affiche pour vérifier.
for (auto element : sous_ensemble)
{
std::cout << element << std::endl;
}
return 0;
}
Certains conteneurs, comme std::vector, std::list ou encore std::string, proposent également une fonction nommée erase, qui se base sur le principe des itérateurs pour supprimer plusieurs éléments d’une collection. On peut ainsi supprimer tous les éléments à partir du cinquième jusqu’à la fin, ou bien les trois premiers.
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
int main()
{
std::vector<int> nombres { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// Certains éléments.
nombres.erase(std::begin(nombres) + 2, std::begin(nombres) + 5);
for (auto nombre : nombres)
{
std::cout << nombre << std::endl;
}
std::cout << std::endl;
std::string phrase { "Voici une phrase beurk !" };
// Jusqu'à la fin.
phrase.erase(std::begin(phrase) + 16, std::end(phrase));
std::cout << phrase << std::endl;
return 0;
}
Des algorithmes à gogo !
Maintenant, les itérateurs vont devenir vraiment intéressants et concrets, parce qu’ils sont pleinement employés par les algorithmes de la bibliothèque standard. Ces derniers, assez nombreux, sont des fonctions déjà programmées et fortement optimisées pour manipuler des collections, permettant ainsi de les trier, de récupérer tous les éléments satisfaisant une certaine condition, etc. Nous n’en verrons que quelques-uns dans ce chapitre, mais une fois le principe compris, vous n’aurez aucune difficulté à utiliser les autres.
La plupart des algorithmes se trouvent dans le fichier d’en-tête <algorithm>, pensez donc à l’inclure.
std::count — Compter les occurrences d’une valeur
Commençons avec un algorithme simple, mais on ne peut plus utile : compter les occurrences d’une certaine valeur dans une collection. Cela se fait avec l’algorithme std::count. Celui-ci attend trois paramètres.
- Le premier est un itérateur pointant sur le début de la séquence.
- Le deuxième est un itérateur pointant sur la fin de la séquence.
- Le dernier est l’élément à compter.
La force de l’algorithme, c’est qu’il ne nous impose pas de chercher dans toute la collection. En effet, comme on manipule ici des itérateurs, rien ne nous empêche de compter les occurrences d’une valeur seulement entre le troisième et le septième élément de la collection, ou entre le cinquième et le dernier.
#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Exemple illustrant le tutoriel C++ de Zeste de Savoir." };
// Toute la collection.
auto const total_phrase { std::count(std::begin(phrase), std::end(phrase), 'e') };
std::cout << "Dans la phrase entière, il y a " << total_phrase << " 'e' minuscule." << std::endl;
// Un sous-ensemble seulement de la collection.
auto const total_premier_mot { std::count(std::begin(phrase), std::begin(phrase) + 7, 'e') };
std::cout << "Dans le premier mot, il y a " << total_premier_mot << " 'e' minuscule." << std::endl;
return 0;
}
Cet exemple utilise std::string, mais j’aurais tout aussi bien pu employer std::vector ou std::array. Par contre, std::list ne convient pas parce que … oui ! j’ai fait std::begin(phrase) + 7, ça suit dans le fond. Heureusement, une solution existe, que je vais vous montrer de suite.
std::find — Trouver un certain élément
Vous remarquerez que le code précédent n’est pas de très bonne qualité, puisque j’ai écrit +7 directement, en dur. En plus du problème soulevé précédemment (ne pas pouvoir utiliser std::list), cela n’est pas très flexible : si le premier mot devient plus long ou plus court, je fausse les résultats. Alors qu’avec un itérateur qui pointerait sur le premier espace, on serait assuré d’avoir plus de souplesse. C’est justement ce que propose std::find, qui prend trois paramètres.
- Le premier est un itérateur pointant sur le début de la séquence.
- Le deuxième est un itérateur pointant sur la fin de la séquence.
- Le dernier est l’élément à rechercher.
Cette fonction retourne un itérateur sur le premier élément correspondant à la recherche, ou bien le deuxième argument si rien n’est trouvé.
#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Exemple illustrant le tutoriel C++ de Zeste de Savoir." };
// On obtient un itérateur pointant sur le premier espace trouvé.
// Si l'on n'avait rien trouvé, on aurait obtenu std::end(phrase) comme valeur de retour.
auto const iterateur_premier_mot { std::find(std::begin(phrase), std::end(phrase), ' ') };
// On peut donc s'en servir ici. Même si l'on modifie la longueur du premier mot, on est assuré que cette solution marche.
auto const total_premier_mot { std::count(std::begin(phrase), iterateur_premier_mot, 'e') };
std::cout << "Dans le premier mot, il y a " << total_premier_mot << " 'e' minuscule." << std::endl;
return 0;
}
Je précise de nouveau pour être bien clair : std::find retourne un itérateur sur le premier élément trouvé, pas le deuxième ou le trousillième. Mais avec une simple boucle, rien ne nous empêche de récupérer la deuxième occurrence, ou la troisième.
Cela me donne d’ailleurs une excellente idée d’exercice. En utilisant les deux fonctions que nous venons de voir, nous allons faire un programme qui compte le nombre de 'e' dans chaque mot d’une phrase. Essayez de coder par vous-mêmes ce petit exercice. Une solution est proposée ci-dessous.
Petite astuce avant de commencer : on peut initialiser une chaîne de caractères avec un itérateur de début et de fin, comme n’importe quel autre conteneur.
#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Exemple illustrant le tutoriel C++ de Zeste de Savoir, mais un peu plus long." };
// Pour garder en mémoire le début de chaque mot.
auto iterateur_precedent { std::begin(phrase) };
auto iterateur_espace { std::find(std::begin(phrase), std::end(phrase), ' ') };
// Tant qu'on est pas à la fin de la phrase.
while (iterateur_espace != std::end(phrase))
{
std::string const mot { iterateur_precedent, iterateur_espace };
auto const total_e { std::count(std::begin(mot), std::end(mot), 'e') };
std::cout << "Dans le mot '" << mot << "', il y a " << total_e << " fois la lettre 'e'." << std::endl;
// On incrémente pour ne pas garder l'espace au début, car iterateur_espace pointe déjà sur un espace.
++iterateur_espace;
// On met à jour notre itérateur de sauvegarde.
iterateur_precedent = iterateur_espace;
// On cherche la première occurrence dans le nouveau sous-ensemble.
iterateur_espace = std::find(iterateur_espace, std::end(phrase), ' ');
}
// Une dernière fois pour analyser les caractères restants.
std::string const dernier_mot { iterateur_precedent, std::end(phrase) };
std::cout << "Dans le dernier mot '" << dernier_mot << "', il y a " << std::count(iterateur_precedent, std::end(phrase), 'e') << " fois la lettre 'e'." << std::endl;
return 0;
}
std::sort — Trier une collection
L’algorithme std::sort, fonctionnant, comme les autres, avec une paire d’itérateurs, permet de trier dans l’ordre croissant une collection d’éléments, que ce soit des nombres, des caractères, etc. Bien entendu, cet algorithme ne marchera que sur des conteneurs modifiables, c’est-à-dire non const. Voici un exemple tout simple qui ne devrait guère vous surprendre.
#include <algorithm>
#include <iostream>
#include <vector>
int main()
{
std::vector<double> constantes_mathematiques { 2.71828, 3.1415, 1.0836, 1.4142, 1.6180 };
std::sort(std::begin(constantes_mathematiques), std::end(constantes_mathematiques));
for (auto constante : constantes_mathematiques)
{
std::cout << constante << std::endl;
}
return 0;
}
Si vous avez essayé de changer std::vector en std::list, vous vous êtes rendu compte que le code ne compile plus. En effet, std::sort attend en paramètre des itérateurs à accès direct, comme ceux de std::array, std::vector et std::string.
À l’opposé, std::list n’utilise que des itérateurs bidirectionnels. Il est donc impossible de trier une std::list en utilisant cet algorithme.
std::listLe type std::list possède une fonction sort qui lui est propre et qui fait la même chose.
#include <iostream>
#include <list>
int main()
{
std::list<int> liste { 4, -8, 45, 2 };
liste.sort();
for (int i : liste)
{
std::cout << i << std::endl;
}
return 0;
}
std::reverse — Inverser l’ordre des éléments d’une collection
Parlons de std::reverse, qui inverse la position des éléments compris entre l’itérateur de début et l’itérateur de fin. Un exemple va vous montrer clairement ce qu’il fait.
#include <algorithm>
#include <iostream>
#include <list>
int main()
{
std::list<int> nombres { 2, 3, 1, 7, -4 };
std::cout << "Avant :\n";
for (auto nombre : nombres)
{
std::cout << nombre << std::endl;
}
std::reverse(std::begin(nombres), std::end(nombres));
std::cout << "\nAprès :\n";
for (auto nombre : nombres)
{
std::cout << nombre << std::endl;
}
return 0;
}
std::remove — Suppression d’éléments
Admettons maintenant que vous voulez supprimer toutes les lettres 'b' d’une chaîne. Avec std::remove, il n’y a aucun problème à ça. L’algorithme va supprimer toutes les occurrences de la lettre dans la chaîne. Et comme l’algorithme ne peut pas modifier la taille du conteneur, il nous renvoit un itérateur qui nous signale la fin de la collection. Il ne reste plus qu’à supprimer le tout grâce à erase.
#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string paroles { "I'm blue, da ba dee da ba daa !" };
auto iterateur_fin { std::remove(std::begin(paroles), std::end(paroles), 'b') };
paroles.erase(iterateur_fin, std::end(paroles));
std::cout << paroles << std::endl;
return 0;
}
std::search — Rechercher un sous-ensemble dans un ensemble
Cette fois, avec std::search, ça n’est pas un unique élément que nous allons chercher, mais bien un sous-ensemble dans un autre ensemble, comme, par exemple, un mot dans une phrase. Cette fois, pas moins de quatre arguments sont attendus.
- Le premier est l’itérateur de début de la collection à fouiller.
- Le deuxième est l’itérateur de fin.
- Le troisième est l’itérateur de début de la sous-collection à rechercher.
- Le quatrième est l’itérateur de fin.
Tout comme std::find, si rien n’est trouvé, le deuxième argument, l’itérateur de fin de la collection à parcourir, est renvoyé. Voici donc un exemple pour illustrer le fonctionnement de l’algorithme.
#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string const phrase { "Un exemple de phrase avec plusieurs mots." };
auto const debut { std::begin(phrase) };
auto const fin { std::end(phrase) };
// Rappel : std::boolalpha permet d'afficher 'true' ou 'false' et non '1' ou '0'.
std::cout << std::boolalpha;
std::string mot { "mot" };
std::cout << (std::search(debut, fin, std::begin(mot), std::end(mot)) != fin) << std::endl;
mot = "exemple";
std::cout << (std::search(debut, fin, std::begin(mot), std::end(mot)) != fin) << std::endl;
return 0;
}
std::equal — Vérifier l’égalité de deux ensembles
Comment testeriez-vous que deux ensembles sont équivalents, autrement dit qu’ils possèdent les mêmes éléments ? La réponse vient du titre : avec l’algorithme std::equal. Celui-ci prend plusieurs paramètres.
- L’itérateur de début du premier ensemble.
- L’itérateur de fin du premier ensemble.
- L’itérateur de début du deuxième ensemble.
- L’itérateur de fin du deuxième ensemble.
Si les deux ensembles n’ont pas la même taille, alors l’égalité est forcément impossible. Sinon, l’algorithme va comparer les deux ensembles élément par élément.
#include <algorithm>
#include <iostream>
#include <vector>
int main()
{
std::vector<int> const premier { 1, 2, 3, 4 };
std::vector<int> const second { 1, 2, 3, 4, 5 };
std::vector<int> const troisieme { 1, 2, 3, 4 };
std::cout << std::boolalpha;
std::cout << std::equal(std::begin(premier), std::end(premier), std::begin(second), std::end(second)) << std::endl;
std::cout << std::equal(std::begin(premier), std::end(premier), std::begin(troisieme), std::end(troisieme)) << std::endl;
}
Et tant d’autres
Il y a tellement d’algorithmes différents que je ne vais pas tous vous les présenter. Vous en avez déjà vu plusieurs, et tous fonctionnent sur le même principe, celui des itérateurs. Utiliser les autres ne devrait donc pas vous poser de problème. 
Personnalisation à la demande
Jusqu’ici, nos algorithmes sont figés. Par exemple, std::sort ne trie que dans l’ordre croissant. Mais les concepteurs de la bibliothèque standard ont pensé à ça et ont écrit leurs algorithmes de telle manière qu’on peut personnaliser leur comportement. Mine de rien, cette possibilité les rend encore plus intéressants ! Voyons ça ensemble.
Le prédicat, à la base de la personnalisation des algorithmes
Un prédicat est une expression qui prend, ou non, des arguments et renvoie un booléen. Le résultat sera donc true ou false, si la condition est vérifiée ou non. Littéralement, un prédicat répond à des questions ressemblant à celles ci-dessous.
- Est-ce que l’élément est impair ?
- Est-ce que les deux éléments
aetbsont égaux ? - Est-ce que les deux éléments sont triés par ordre croissant ?
La très grande majorité des algorithmes utilisent les prédicats, même ceux vu plus haut, sans que vous le sachiez. Par exemple, std::sort utilise, par défaut, le prédicat <, qui compare si un élément a est strictement inférieur à un autre élément b, ce qui explique pourquoi l’algorithme trie une collection dans l’ordre croissant. Mais il est tout à fait possible de lui indiquer de faire autre chose.
La bibliothèque standard contient déjà quelques prédicats, regroupés dans le fichier d’en-tête <functional>. Nous apprendrons, plus tard dans ce tutoriel, à écrire nos propres prédicats.
Trier une liste dans l’ordre décroissant
Faisons connaissance avec std::greater. Il s’agit d’un foncteur, c’est-à-dire un objet qui agit comme une fonction. Les détails internes ne nous intéressent pas pour l’instant, nous y reviendrons plus tard, quand nous aurons les connaissances requises.
Ce foncteur compare deux éléments et retourne true si le premier est plus grand que le deuxième, sinon false. Voici quelques exemples. Notez qu’on doit préciser, entre chevrons <>, le type des objets comparés.
#include <functional>
#include <iostream>
int main()
{
std::cout << std::boolalpha;
// On peut l'utiliser directement.
std::cout << std::greater<int>{}(2, 3) << std::endl;
std::cout << std::greater<int>{}(6, 3) << std::endl;
std::cout << std::greater<double>{}(0.08, 0.02) << std::endl;
// Ou bien à travers une variable, qu'on appelle comme une fonction.
std::greater<int> foncteur {};
std::cout << foncteur(-78, 9) << std::endl;
std::cout << foncteur(78, 8) << std::endl;
return 0;
}
Afin de personnaliser le comportement de std::sort, notre fonction de tri vue plus haut, il suffit de lui passer ce foncteur. Observez par vous-mêmes.
#include <algorithm>
#include <functional>
#include <iostream>
#include <vector>
int main()
{
std::vector<int> tableau { -8, 5, 45, -945 };
std::sort(std::begin(tableau), std::end(tableau), std::greater<int> {});
for (auto x : tableau)
{
std::cout << x << std::endl;
}
return 0;
}
Somme et produit
Dans le fichier d’en-tête <numeric>, il existe une fonction répondant au doux nom de std::accumulate, qui permet de faire la somme d’un ensemble de valeurs, à partir d’une valeur de départ. Ça, c’est l’opération par défaut, mais on peut très bien lui donner un autre prédicat, comme std::multiplies, afin de calculer le produit des éléments d’un ensemble.
#include <functional>
#include <iostream>
#include <numeric>
#include <vector>
int main()
{
std::vector<int> const nombres { 1, 2, 4, 5, 10 };
// On choisit 0 comme élément de départ pour calculer la somme, car 0 est l'élément neutre de l'addition.
auto somme { std::accumulate(std::cbegin(nombres), std::cend(nombres), 0) };
std::cout << somme << std::endl;
// On choisit 1 comme élément de départ pour calculer le produit, car 1 est l'élément neutre de la multiplication.
auto produit { std::accumulate(std::cbegin(nombres), std::cend(nombres), 1, std::multiplies<int> {}) };
std::cout << produit << std::endl;
return 0;
}
Prédicats pour caractères
Il existe, dans le fichier d’en-tête <cctype>, des prédicats vérifiant des conditions uniquement sur un caractère. Ils permettent de vérifier si un caractère est une lettre, un chiffre, un signe de ponctuation, etc. Voyez par vous-mêmes.
#include <cctype>
#include <iostream>
int main()
{
char const lettre { 'A' };
std::cout << "Est-ce que " << lettre << " est une minuscule ? " << islower(lettre) << std::endl;
std::cout << "Est-ce que " << lettre << " est une majuscule ? " << isupper(lettre) << std::endl;
std::cout << "Est-ce que " << lettre << " est un chiffre ? " << isdigit(lettre) << std::endl;
char const chiffre { '7' };
std::cout << "Est-ce que " << chiffre << " est un chiffre ? " << isdigit(chiffre) << std::endl;
std::cout << "Est-ce que " << chiffre << " est un signe de ponctuation ? " << ispunct(chiffre) << std::endl;
return 0;
}
Ces fonctions sont héritées du C, c’est pour cela qu’elles ne sont pas précédées de l’habituel std::. C’est également la raison pour laquelle elles renvoient des entiers et non des booléens, comme on aurait pu s’y attendre.
On peut faire des choses intéressantes avec ça. Par exemple, en utilisant l’algorithme std::all_of, qui vérifie que tous les éléments d’un ensemble respectent une propriété, on peut vérifier si tous les caractères d’une chaîne sont des chiffres, pour valider qu’il s’agit d’un numéro de téléphone.
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
int main()
{
std::string const numero { "0185017204" };
if (std::all_of(std::cbegin(numero), std::cend(numero), isdigit))
{
std::cout << "C'est un numéro de téléphone correct." << std::endl;
}
else
{
std::cout << "Entrée invalide." << std::endl;
}
return 0;
}
Plus loin dans le cours, nous apprendrons à écrire nos propres prédicats, ce qui nous donnera encore plus de pouvoir sur nos algorithmes. Mais patience.
Exercices
Palindrome
Vous devez tester si une chaîne de caractères est un palindrome, c’est-à-dire un mot pouvant être lu indifféremment de gauche à droite ou de droite à gauche. Un exemple : « kayak. »
Correction palindrome (Afficher/Masquer)#include <algorithm>
#include <iostream>
#include <string>
int main()
{
std::string const s1 { "azerty" };
std::string const s2 { "radar" };
std::cout << std::boolalpha;
std::cout << std::equal(std::begin(s1), std::end(s1), std::rbegin(s1), std::rend(s1)) << std::endl;
std::cout << std::equal(std::begin(s2), std::end(s2), std::rbegin(s2), std::rend(s2)) << std::endl;
return 0;
}
L’astuce consiste à regarder si les deux ensembles de lettres sont les mêmes, en partant de la gauche vers la droite pour le premier (itérateur classique) et l’opposé pour le deuxième (reverse iterator).
string_trim — Suppression des espaces
Allez, un exercice plus dur, pour vous forger le caractère. Le but est de reproduire une fonction qui existe dans de nombreux autres langages, comme C# ou Python, et qui permet de supprimer les espaces, au début et à la fin d’une chaîne de caractères. Cela signifie non seulement les espaces ' ' mais aussi les tabulations '\t', les retours à la ligne '\n', etc. Pour vous aider, vous aller avoir besoin de deux choses.
- Le prédicat
isspace, pour savoir si un caractère est un type d’espace ou non. - L’algorithme
std::find_if_not, qui permet de trouver, dans un ensemble délimité par deux itérateurs, le premier caractère qui ne respecte pas une condition.
Pour vous faciliter la vie, découper l’exercice en deux. Faites d’abord la fonction permettant de supprimer tous les espaces à gauche, puis pour ceux à droite. Bon courage.
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
int main()
{
std::string test { "\n\tHello !\n\t" };
std::cout << "Avant modification : " << test << std::endl;
// On utilise l'itérateur fourni par std::find_if_not, qui pointe sur le premier élément qui n'est pas un espace.
auto premier_non_espace { std::find_if_not(std::begin(test), std::end(test), isspace) };
test.erase(std::begin(test), premier_non_espace);
// On affiche pour tester.
std::cout << "Suppression au début : " << test << std::endl;
// En inversant, tous les espaces de fin se retrouvent au début.
std::reverse(std::begin(test), std::end(test));
// On reprend le même algorithme.
premier_non_espace = std::find_if_not(std::begin(test), std::end(test), isspace);
test.erase(std::begin(test), premier_non_espace);
// On revient à l'état initial.
std::reverse(std::begin(test), std::end(test));
// On affiche pour tester.
std::cout << "Suppression à la fin : " << test << std::endl;
return 0;
}
Il est vrai que nous répétons deux fois les instructions pour supprimer les espaces à gauche. Laissez ça en l’état, nous verrons très bientôt une solution pour corriger ce fâcheux problème.
Couper une chaîne
Une autre opération courante, et qui est fournie nativement dans d’autres langages comme Python ou C#, consiste à découper une chaîne de caractères selon un caractère donné. Ainsi, si je coupe la chaîne "Salut, ceci est une phrase." en fonction des espaces, j’obtiens en résultat ["Salut,", "ceci", "est", "une", "phrase.].
Le but est donc que vous codiez un algorithme qui permet de faire ça. Vous allez notamment avoir besoin de la fonction std::distance, qui retourne la distance entre deux itérateurs, sous forme d’un nombre entier.
#include <algorithm>
#include <iostream>
#include <string>
#include <vector>
int main()
{
std::string texte { "Voici une phrase que je vais couper." };
char const delimiteur { ' ' };
std::vector<std::string> parties {};
auto debut = std::begin(texte);
auto fin = std::end(texte);
auto iterateur = std::find(debut, fin, delimiteur);
while (iterateur != fin)
{
// Grâce à std::distance, nous obtenons la taille du mot.
std::string mot { debut, debut + std::distance(debut, iterateur) };
parties.push_back(mot);
// +1 pour sauter le délimiteur.
debut = iterateur + 1;
// Et on recommence.
iterateur = std::find(debut, fin, delimiteur);
}
// Ne pas oublier le dernier mot.
std::string mot { debut, debut + std::distance(debut, iterateur) };
parties.push_back(mot);
// On affiche pour vérifier.
for (std::string mot : parties)
{
std::cout << mot << std::endl;
}
return 0;
}
En résumé
- Les itérateurs sont des abstractions représentant un pointeur sur un élément d’un conteneur. Ils rendent ainsi l’usage du conteneur plus transparent.
- Deux fonctions,
std::beginetstd::end, sont extrêmement utilisées avec les itérateurs, car retournant un pointeur sur, respectivement, le début et la fin d’une collection. - Les itérateurs demandent de la rigueur pour ne pas manipuler des éléments qui sont hors de la collection, ce qui entrainerait des comportements indéterminés.
- La bibliothèque standard contient des algorithmes, déjà programmés et très optimisés, qu’on peut appliquer à des collections.
- Nous pouvons les personnaliser grâce à des prédicats fournis dans la bibliothèque standard.