Depuis le début de ce tutoriel, toutes les données que nous manipulons ont un point commun, qui est leur volatilité. Elles sont en effet stockées dans la mémoire vive de l’ordinateur, et celle-ci se vide dès qu’on l’éteint. Impossible, dans ces conditions, de sauvegarder des informations, comme une sauvegarde de jeu vidéo ou un résumé sur l’utilisateur.
Le but de ce chapitre est donc d’apprendre à lire et écrire dans des fichiers et, de manière plus générale, dans des flux.
Pour manipuler des fichiers, il faut inclure le fichier d’en-tête <fstream>.
- Avant-propos
- std::ofstream — Écrire dans un fichier
- std::ifstream — Lire dans un fichier
- Exercice
- Encore plus de flux !
Avant-propos
Votre ordinateur contient énormément de fichiers, de tous les genres. Vos musiques préférées sont des fichiers, tout comme vos photos de vacances, votre CV Word ou LibreOffice, les fichiers de configuration de vos jeux vidéos, etc. Mêmes les programmes que vous utilisez sont des fichiers !
- Chaque fichier a un nom.
- Chaque fichier a une extension.
Prendrez-vous une extension ?
Il existe tout un tas d’extension de fichiers, pour chaque type qui existe. En voici quelques exemples.
- Fichiers audios :
.mp3,.oga, etc. - Fichiers vidéos :
.mp4,.avi, etc. - Images :
.jpg,.png,.gif, etc. - Exécutables :
.exe,.msi,.out, etc. - Fichiers textes :
.txt,.ini,.log, etc.
Celles-ci sont surtout utiles pour nous, humains, afin de savoir quel type de fichier nous allons manipuler. Mais elles n’influencent en rien le contenu du fichier.
Certains fichiers, comme les fichiers textes, sont très simples à ouvrir et donne accès directement à l’information. D’autres, comme les .png ou les .docx, doivent être lus en respectant une certaine façon de faire, une norme, afin que l’information fasse sens. Dans le cadre de ce cours, nous ne verrons que les documents textes simples.
🎜 Vois sur ton chemin…
Afin de faciliter leur localisation et leur gestion, les fichiers sont classés et organisés sur leur support suivant un système de fichiers. C’est lui qui permet à l’utilisateur de répartir ses fichiers dans une arborescence de dossiers et de localiser ces derniers à partir d’un chemin d’accès.
Un chemin d’accès permet d’indiquer où est situé un fichier dans ledit système de fichier. Il contient forcément le nom du fichier concerné, mais également, si nécessaire, un ou plusieurs noms de dossiers, qu’il est nécessaire de traverser pour accéder au fichier depuis la racine.
La racine d’un système de fichier est le point de départ de l’arborescence des fichiers et dossiers. Sous GNU/Linux, il s’agit du répertoire / tandis que sous Windows, chaque lecteur est une racine (comme C: par exemple). Si un chemin d’accès commence par la racine, alors celui-ci est dit absolu car il permet d’atteindre le fichier depuis n’importe qu’elle position dans l’arborescence. Si le chemin d’accès ne commence pas par la racine, il est dit relatif et ne permet de parvenir au fichier que depuis un point précis dans la hiérarchie de fichiers.
Prenons un exemple. Nous avons un fichier code_nucléaire.txt qui se trouve dans un dossier top_secret, lui-même dans documents, qui se trouve à la racine. Le chemin absolu ressemblera à ça.
- Windows :
C:\documents\top_secret\code_nucléaire.txt - GNU/Linux :
/documents/top_secret/code_nucléaire.txt
Par contre, si nous sommes déjà dans le dossier documents, alors nous pouvons nous contenter d’utiliser un chemin relatif. Ce chemin ne marchera cependant plus si nous sortons du dossier documents.
- Windows :
top_secret\code_nucléaire.txt - GNU/Linux :
top_secret/code_nucléaire.txt
Le point . représente le dossier courant, c’est-à-dire documents dans notre exemple.
Un mot sur Windows
Depuis les années 1990, Windows supporte les chemins utilisant les slashs /. Si vous ouvrez l’explorateur de fichier et que vous écrivez C:/Windows/System32, ça marchera sans problème. Vous avez donc deux possibilités.
- Utilisez les slashs
/si vous voulez que votre programme puisse fonctionner sur tous les systèmes. - Utilisez les antislashs
\si votre programme n’est destiné qu’à Windows.
Si vous décidez d’utiliser ces derniers, n’oubliez pas de les doubler en écrivant \\, car \ seul est un caractère d’échappement. Ou bien utilisez les chaînes brutes.
Pas d’interprétation, on est des brutes
Utiliser les séquences d’échappement peut alourdir le code, en plus d’être casse-pieds à écrire. C++ offre une solution alternative qui se nomme chaînes brutes (de l’anglais raw strings). Par défaut, une chaîne brute commence par R"( et termine par )". Tout ce qui se trouve entre ces deux séquences n’est pas interprété, mais tout simplement ignoré.
#include <iostream>
int main()
{
std::cout << R"(Elle a dit "Va dans le dossier C:\Program Files" et regarde.)" << std::endl;
return 0;
}
Et si jamais notre chaîne contient le délimiteur de fin, on peut personnaliser les délimiteurs pour qu’ils soient différents. Pour ça, on ajoute les caractères qu’on souhaite entre les guillemets et les parenthèses.
#include <iostream>
int main()
{
// Oups, ça ne marche pas...
//std::cout << R"(Il a écrit "f(x)" au tableau.)" << std::endl;
// Heureusement, je peux choisir moi-même mes délimiteurs.
// Ici, tout ce qui est entre "&( et )&" n'est pas interprété.
std::cout << R"&(Il a écrit "f(x)" au tableau.)&" << std::endl;
return 0;
}
std::ofstream — Écrire dans un fichier
Commençons par apprendre à écrire dans un fichier. Cela nous est utile si nous voulons sauvegarder un score, les paramètres de configuration d’une application ou n’importe quel résultat de notre programme. Et pour ce faire, nous allons utiliser le type std::ofstream, abréviation de « output file stream », ce qui signifie « flux fichier de sortie ».
Ouvrir le fichier
Il attend en argument le nom du fichier à ouvrir. Par défaut, si le fichier n’existe pas, il est créé.
#include <fstream>
int main()
{
// Je veux ouvrir un fichier nommé 'sortie.txt', qui se trouve dans le dossier du projet.
// S'il existe, il sera ouvert. Sinon, il sera d'abord créé puis ouvert.
std::ofstream fichier { "sortie.txt" };
return 0;
}
Écriture
Pour écrire dedans, c’est très simple, il suffit de réutiliser les chevrons, comme avec std::cout. Voyez par vous-mêmes.
#include <fstream>
int main()
{
std::ofstream fichier { "sortie.txt" };
// On écrit un 3, un espace et un 4.
fichier << 3 << " " << 4;
return 0;
}
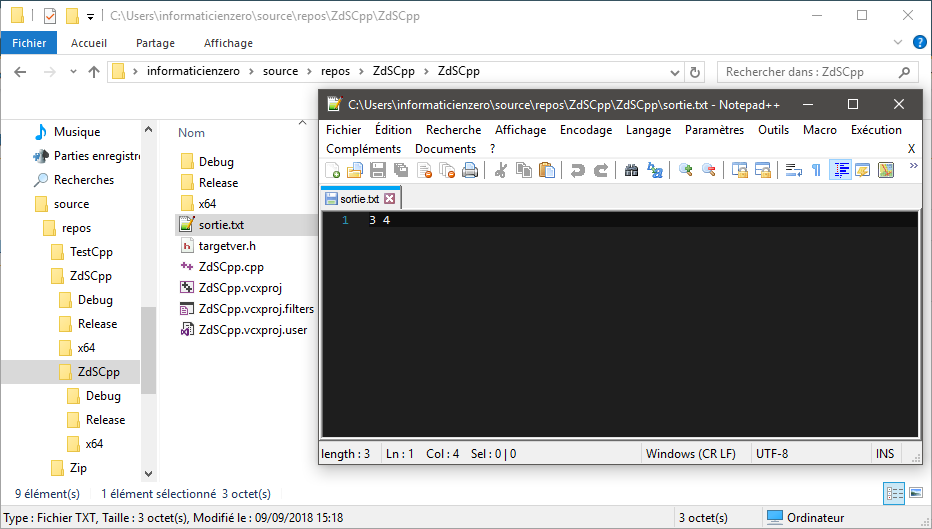
Et, exactement comme pour std::cout, nous pouvons écrire des littéraux, mais aussi des variables et des expressions.
#include <fstream>
#include <string>
int main()
{
std::ofstream fichier { "sortie.txt" };
fichier << 3 << " " << 4;
int x { 0 };
// On va à la ligne puis on écrit une équation.
fichier << '\n' << x << " + 2 = " << x + 2;
// Pas de problème avec le texte non plus.
std::string texte { "Voici une phrase." };
fichier << '\n' << texte;
return 0;
}
J’ai essayé d’écrire une phrase avec des accents et j’ai obtenu un texte avec des caractères bizarres. Que s’est-il passé ?
Normalement, les Linuxiens sont épargnés par ce problème et seuls ceux utilisant Windows sont concernés (pas de chance). En fait, c’est une histoire d'encodage.
Sans rentrer dans les détails, car un cours entier existe déjà sur le sujet, il existe différents encodages qui permettent de stocker plus ou moins de caractères. Le premier inventé (années 1960), l'ASCII, ne permet de stocker que 127 caractères, dont les 26 lettres de l’alphabet anglais, mais pas nos accents français, le ñ espagnol, le ß allemand, etc. D’autres sont apparus et permettent de stocker plus de caractères, dont UTF-8.
Par défaut en C++, quand on manipule une chaîne de caractères, celle-ci est interprétée comme étant de l'ASCII. Comme nos accents français ne sont pas représentables, on obtient du grand n’importe quoi en sortie. La solution consiste à utiliser UTF-8, ce qui se fait en précisant u8 devant nos chaînes de caractères.
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
int main()
{
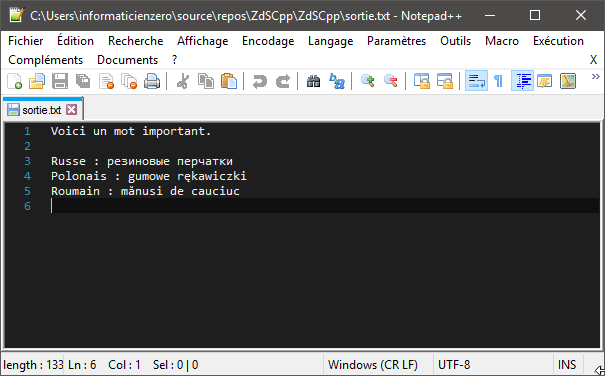
std::vector<std::string> const phrases
{
u8"Voici un mot important.\n",
u8"Russe : резиновые перчатки",
u8"Polonais : gumowe rękawiczki",
u8"Roumain : mănusi de cauciuc"
};
std::ofstream fichier { "sortie.txt" };
for (auto const & phrase : phrases)
{
fichier << phrase << std::endl;
}
return 0;
}
Enfin, il faut enregistrer le code source en UTF-8. Pour se faire, suivez les instructions ci-dessous.
- Sous Visual Studio, cliquez sur Fichier -> Enregistrer main.cpp sous…, puis cliquez sur la petite flèche à côté du bouton Enregistrer et sélectionnez l’option Enregistrer avec encodage…. Ensuite, pour le champs « Encodage », choisissez la valeur « Unicode (UTF-8 avec signature) - Page de codes 65001 » et validez.
Il ne vous reste plus qu’à lancer et voir le résultat.
Ouvrir sans effacer
Essayer de modifier le fichier vous-mêmes, avec votre éditeur de texte préféré, et ajouter au tout début une phrase quelconque. Lancez le programme, rouvrez le fichier et horreur ! votre texte a disparu. 
En fait, par défaut, std::ofstream tronque le contenu du fichier. Autrement dit, s’il y avait des données écrites précédemment, elles sont perdues dès que le programme rouvrira le fichier. Mais il est possible de régler ce problème très simplement.
Lorsque nous initialisons notre objet std::ofstream, nous pouvons lui donner un deuxième argument qui est le mode d’ouverture. Dans notre cas, ce mode est std::ios::app. Ici, ios veut dire Input Output Stream, c’est-à dire flux d’entrée et de sortie ; app est le diminutif de append, qui veut dire ajouter en anglais.
Notre contenu n’est plus effacé et les données supplémentaires sont ajoutées à la suite.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ofstream fichier { "sortie.txt", std::ios::app };
fichier << 3 << " " << 4;
int x { 0 };
fichier << '\n' << x << " + 2 = " << x + 2;
std::string texte { u8"Voici une phrase." };
fichier << '\n' << texte;
return 0;
}
std::ifstream — Lire dans un fichier
Abordons maintenant la lecture, opération elle aussi ô combien importante. Cela nous permet de charger des paramètres, d’analyser des fichiers, etc. Pour ce faire, nous allons utiliser le type std::ifstream, abréviation de « input file stream », ce qui signifie « flux fichier d’entrée ».
Ouvrir le fichier
L’ouverture se fait de la même façon que pour std::ofstream, c’est-à-dire en donnant le nom du fichier à ouvrir. Sauf que cette fois, il faut que le fichier existe déjà. C’est logique : vous ne pouvez pas lire un fichier qui n’existe pas.
Créez donc avec moi un fichier appelé entrée.txt.
#include <fstream>
int main()
{
std::ifstream fichier { "entrée.txt" };
return 0;
}
Lecture
Écrivez avec moi, dans le fichier entrée.txt, un entier, puis un retour à la ligne, puis un mot.
42
Bonjour
La lecture se fait très simplement. On utilise les chevrons comme pour std::cin. Voyez par vous-mêmes.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ifstream fichier { "entrée.txt" };
int entier { 0 };
fichier >> entier;
std::cout << "Mon entier vaut : " << entier << std::endl;
std::string mot { "" };
fichier >> mot;
std::cout << "Mon mot vaut : " << mot << std::endl;
return 0;
}
J’avais dans mon fichier une phrase entière, et seul le premier mot est apparu dans la console. Que s’est-il passé ?
En fait, c’est un comportement tout à fait normal, qu’on retrouve également avec std::cin. Par défaut, les espaces et les retours à la ligne sont considérés comme étant des délimiteurs, des séparateurs. Ainsi, là où vous voyez une phrase complète, le programme va voir un ensemble de mots séparés par des espaces.
Les concepteurs de C++ ne nous laissent néanmoins pas sans solution. Il existe une fonction, std::getline, qui permet de lire une ligne entière. Elle attend le flux d’entrée à lire, ainsi qu’une std::string pour écrire le résultat.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ifstream fichier { "entrée.txt" };
int entier { 0 };
fichier >> entier;
std::cout << "Mon entier vaut : " << entier << std::endl;
std::string phrase { "" };
std::getline(fichier, phrase);
std::cout << "Ma phrase vaut : " << phrase << std::endl;
return 0;
}
Ça ne marche toujours pas ! Pourquoi je ne vois plus rien maintenant ?
Vicieux comme je suis, je vous ai encore fait tomber dans un piège. 
Le problème vient de l’utilisation, juste avant std::getline, des chevrons. Ceux-ci lisent la valeur entière, pas de soucis, mais le caractère de retour à la ligne est laissé. Si l’on refait encore cette opération avec les chevrons, alors ce caractère est « mangé » et ne nous gène pas. Mais ce n’est pas le cas avec std::getline.
Pour régler ce problème, nous avons plusieurs solutions.
- Nous pouvons utiliser
fichier.ignore(255, '\n')après l’utilisation des chevrons, comme nous l’avons appris dans les T.P de gestion des erreurs d’entrée. Ainsi, nous sommes sûrs de supprimer le retour à la ligne qui nous embête. - Nous pouvons utiliser le modificateur de flux (c’est-à-dire qui modifie son comportement)
std::ws(de l’anglais « white spaces », espaces blancs). Il supprime tous les espaces et retours à la ligne qu’il trouve et s’utilise comme suit.
// On peut l'utiliser directement, en même temps que la lecture.
int entier { 0 };
fichier >> entier >> std::ws;
std::cout << "Mon entier vaut : " << entier << std::endl;
// On peut en faire une instruction à part.
fichier >> std::ws;
// Ou même directement avec std::getline !
std::getline(fichier >> std::ws, phrase);
Maintenant, en complétant le code précédent, nous n’avons plus aucun problème.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ifstream fichier { "entrée.txt" };
int entier { 0 };
fichier >> entier;
std::cout << "Mon entier vaut : " << entier << std::endl;
std::string phrase { "" };
// On est sûr de ne pas oublier en l'utilisant directement dans std::getline.
std::getline(fichier >> std::ws, phrase);
std::cout << "Ma phrase vaut : " << phrase << std::endl;
return 0;
}
Tout lire
Vous êtes un lecteur vorace et vous voulez lire tout le fichier ? Aucun problème. Tant les chevrons (mot par mot) que std::getline (ligne par ligne) peuvent être utilisés dans une boucle, pour lire jusqu’à la fin du fichier.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ifstream fichier { "entrée.txt" };
std::string ligne { "" };
while (std::getline(fichier, ligne))
{
std::cout << "Ligne lue : " << ligne << std::endl;
}
return 0;
}
Remarquez la syntaxe de la boucle : while (std::getline(fichier, ligne)). Cela devrait vous rappeler notre utilisation de std::cin dans les boucles (et plus généralement dans les conditions). Ce parallèle est dû au fait que la fonction std::getline renvoie un flux ; plus précisément, elle renvoie le flux qu’on lui donne en paramètre (ici, le fichier ouvert), dont l’état a donc été modifié. C’est ce flux qui est alors converti en booléen pour nous dire si tout s’est bien passé. En particulier, lorsqu’on a atteint la fin du fichier, le flux renvoyé par std::getline est évalué à false, ce qui permet de sortir de la boucle en fin de lecture de fichier.
Exercice
Statistiques sur des fichiers
Quand vous écrivez avec un logiciel de traitement de texte, celui-ci vous donne en direct certaines informations, telles que le nombre de caractères, de mots, de paragraphes, etc. Faisons donc un petit programme qui va ouvrir un fichier et obtenir les informations suivantes.
- Le nombre de lignes.
- Le nombre de caractères (sans les espaces).
- Le nombre de mots.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ifstream fichier { "fichier_1.txt" };
std::string ligne { "" };
int total_lignes { 0 };
int total_caracteres { 0 };
int total_mots { 0 };
bool espace_caractere_precedent { false };
while (std::getline(fichier, ligne))
{
++total_lignes;
for (char c : ligne)
{
if (isspace(c))
{
// Si le précédent n'était pas un espace, alors c'était une partie de mot.
if (!espace_caractere_precedent)
{
++total_mots;
}
espace_caractere_precedent = true;
}
else
{
++total_caracteres;
espace_caractere_precedent = false;
}
}
// Ne pas oublier de regarder pour l'éventuel dernier mot.
if (!espace_caractere_precedent)
{
++total_mots;
espace_caractere_precedent = true;
}
}
std::cout << "Total de caractères : " << total_caracteres << std::endl;
std::cout << "Total de lignes : " << total_lignes << std::endl;
std::cout << "Total de mots : " << total_mots << std::endl;
return 0;
}
Félicitations, vous avez déjà codé une ébauche de wc, un programme UNIX existant. 
Encore plus de flux !
Nous savons lire et écrire dans des fichiers, ce qui est déjà bien. Mais allons un peu plus loin, voulez-vous ? Nous allons découvrir que la manipulation de fichiers et celle des entrées / sorties ont beaucoup plus de points communs que ce que vous auriez pu penser. En effet, dans les deux cas, on parle de flux.
Un flux c’est quoi ?
Il existe de très nombreux composants électroniques. Que ce soient des processeurs, des cartes-mères, des claviers, des écrans, des téléphones, une multitude s’offre à nous. Et tous viennent avec leur propre façon de communiquer. Écrire un programme qui devrait savoir communiquer avec tous ces périphériques est impossible. C’est pour cela qu’on utilise des abstractions.
Par exemple, votre système d’exploitation (Windows, GNU/Linux, Android, etc) est une abstraction. Notre programme ne communique plus avec un nombre potentiellement très grand de matériels et composants, mais uniquement avec le système d’exploitation, qui se charge lui-même de faire le lien avec le matériel (la mémoire vive, le processeur, le disque dur, etc). Cela nous simplifie grandement la vie.
La bibliothèque standard est aussi une abstraction. Elle nous fournit un lot unique de fonctionnalités précises, qui marcheront peu importe le système d’exploitation utilisé. Ainsi, en utilisant la bibliothèque standard, notre programme pourra être compilé pour fonctionner tant avec Windows, que GNU/Linux, qu’Android, etc.
Les flux sont eux aussi une abstraction. Grâce à eux, on peut envoyer ou recevoir des « flux de données » (d’où le nom), d’une taille potentiellement infinie, à des composants. Dans la bibliothèque standard, nous avons ainsi de quoi recevoir des informations du clavier (std::cin), d’en envoyer à l’écran (std::cout) mais aussi avec des fichiers (std::ifstream et std::ofstream).
L’avantage, c’est qu’ils offrent une façon transparente et unifiée d’envoyer et de recevoir des données. Vous l’avez vu vous-mêmes plus haut, il n’y a aucune différence entre écrire sur la sortie standard ou un fichier de notre choix. On pourrait même coder nos propres flux de façon à lire et écrire sur le réseau, qui s’utiliseraient de la même façon que les autres !
Un buffer dites-vous ?
Les flux sont, selon le terme anglophone largement employé, bufferisé. Le problème est qu’accéder à des composants externes, des périphériques, comme la carte graphique, un appareil externe ou autre, peut être long. Ainsi, dans le code suivant, on accèderait potentiellement trois fois à un composant externe.
flux << 1 << 'A' << 3.1415;
Pour éviter ça, tout ce qu’on envoie ou reçoit d’un flux n’est pas directement traité mais mis en mémoire dans un tampon (en anglais « buffer »). Pour que les données soient concrètement et physiquement envoyées à l’écran, ou écrites sur un fichier ou autre, il faut vider le tampon (en anglais « flush »). C’est notamment ce que fait std::endl, en plus d’afficher un retour à la ligne. C’est également ce qui se passe quand le fichier est fermé, quand notre objet arrive à la fin de sa portée et est détruit.
Tenez, faisons un test. Compilez le code suivant et, avant de taper une phrase quelconque en guise d’entrée, ouvrez le fichier concerné et regardez son contenu. Vous le trouverez vide, car les données sont toujours dans le buffer.
#include <fstream>
#include <iostream>
#include <string>
int main()
{
std::ofstream fichier { "sortie.txt" };
// Notez que je ne vide pas le tampon.
fichier << "Hey, salut toi !\n";
fichier << 42 << " " << 2.718;
// Une entrée pour vous laisser le temps d'ouvrir le fichier sortie.txt.
std::string phrase { "" };
std::cout << "Tape une phrase quelconque : ";
std::cin >> phrase;
// Je vide explicitement le tampon. Maintenant les données sont écrites.
fichier << std::flush;
return 0;
}
Pour éviter ce phénomène parfois coûteux, certains codes remplacent std::endl par '\n', pour éviter de flusher trop souvent. Dans le cadre de ce cours, ces questions de performances ne nous intéressent pas, donc nous continuerons à utiliser en alternance std::endl et '\n'.
Les modificateurs de flux
Nous avons déjà vu un modificateur de flux au début de ce cours : std::boolalpha. Il permet d’afficher true ou false au lieu de 1 ou 0 quand on manipule des booléens. Il est tout à fait possible de l’utiliser avec d’autres types de flux. L’exemple suivant vous le démontre.
#include <fstream>
int main()
{
std::ofstream fichier { "sortie.txt" };
// On va écrire true.
fichier << std::boolalpha << true << std::endl;
// On revient comme avant et on va écrire 0.
fichier << std::noboolalpha << false << std::endl;
return 0;
}
Le modificateur std::noboolalpha fait l’opération inverse de std::boolalpha. La plupart des modificateurs sont ainsi disponibles « en paire », l’un activant le comportement désiré, l’autre le désactivant.
Voici ce que vous allez obtenir dans le fichier de sortie.
true
0
Examinons un autre exemple. Vous savez que, si vous afficher dans la console un nombre positif, vous le verrez tel quel. Mais on peut aussi demander à afficher le signe +, tout comme le signe - est affiché pour les nombres négatifs.
#include <iostream>
int main()
{
std::cout << std::showpos << 42 << " " << 89 << " " << -48 << std::endl;
return 0;
}
+42 +89 -48
Même les chaînes y passent !
Maintenant, admettons que vous vouliez avoir une chaîne de caractères représentant un nombre réel. Mais, contraintes supplémentaires, vous voulez que le signe soit toujours affiché et que le nombre soit écrit en utilisant la notation scientifique. Comment faire ?
Il y a bien std::scientific et std::showpos, mais ils n’existent que pour les flux. Justement, la solution va être de traiter les chaînes de caractères comme des flux. Cela se fait en utilisant std::ostringstream comme flux de sortie et std::istringstream comme flux d’entrée. Les deux sont disponibles dans le fichier <sstream>.
#include <iostream>
#include <sstream>
#include <string>
int main()
{
double const reel { 10245.789 };
std::ostringstream flux_chaine;
// Notez comment l'utilisation est identique à ce que vous connaissez.
flux_chaine << std::scientific << std::showpos << reel << std::endl;
// On récupère une chaîne de caractères en appellant str().
std::string resultat { flux_chaine.str() };
std::cout << "Affichage par défaut : " << reel << std::endl;
std::cout << "Affichage modifié : " << resultat << std::endl;
return 0;
}
Affichage par défaut : 10245.8
Affichage modifié : +1.024579e+04
Maintenant, abordons std::istringstream, qui permet de traiter une chaîne de caractères comme un flux, avec un exemple concret. En informatique, beaucoup de valeurs sont écrites suivant le système hexadécimal. Que ce soit l’identifiant d’une carte réseau ou le codage des couleurs sur un site web, il est courant de l’utiliser.
Le système hexadécimal est un système de numération qui utilise 16 chiffres au lieu des 10 que nous connaissons dans le système décimal. Les chiffres vont de 0 à 9, comme pour le décimal, puis on utilise les lettres A, B, C, D, E et F. Ainsi, des nombres comme 2A et FD sont des nombres écrits en hexadécimal, qui valent respectivement 42 et 253 dans notre système décimal.
Si vous souhaitez en savoir plus, lisez l’article Wikipédia, ainsi que d’autres ressources. Pour ma part, je ne vais pas rentrer plus dans les détails que ça.
Par exemple, l’orange agrume utilisé sur Zeste de Savoir est écrit f8ad32 dans son code source. Imaginons donc que nous récupérions cette valeur. C’est une chaîne de caractères et nous voulons en déterminer le niveau de rouge, de vert et de bleu.
Il existe un modificateur de flux appelé std::hex qui permet de dire au flux concerné que les nombres qu’il va extraire utilisent le système hexadécimal et non décimal. En traitant une chaîne de caractères comme un flux, on résout alors notre problème.
#include <iostream>
#include <sstream>
int main()
{
std::istringstream flux_entree { "f8 ad 32" };
int rouge { 0 };
int vert { 0 };
int bleu { 0 };
flux_entree >> std::hex >> rouge >> vert >> bleu;
std::cout << "Niveau de rouge : " << rouge << std::endl;
std::cout << "Niveau de vert : " << vert << std::endl;
std::cout << "Niveau de bleu : " << bleu << std::endl;
return 0;
}
Niveau de rouge : 248
Niveau de vert : 173
Niveau de bleu : 50
On utilisait beaucoup std::ostringstream et std::istringstream avant C++11 pour convertir des nombres en chaînes de caractères et vice-versa. D’autres méthodes existent maintenant, mais nous en parlerons plus tard.
En résumé
- Pour ouvrir un fichier, il faut préciser son chemin, qui peut être relatif ou absolu.
- On écrit dans un fichier en utilisant
std::ofstream. - On lit dans un fichier en utilisant
std::ifstream. - Les flux sont une abstraction permettant d’envoyer ou recevoir un flux de données à des composants quelconques.
- Les flux sont bufferisés.
- Il existe des flux pour communiquer avec des fichiers (
std::ifstreametstd::ofstream), avec des chaînes de caractères (std::istringstreametstd::ostringstream), avec l’entrée et la sortie standards (std::cinetstd::cout). - On utilise des modificateurs de flux pour en modifier le comportement.