
Suite à un commentaire lors d’une discussion sur l’estimation des temps de lecture, j’ai voulu observer par moi-même la distribution des mots en fonction de leur taille dans des textes écrits en français.
- Variabilité liée au choix de l'échantillon
- Variabilité liée au style
- Statistiques générales
- Données et outils
Variabilité liée au choix de l'échantillon
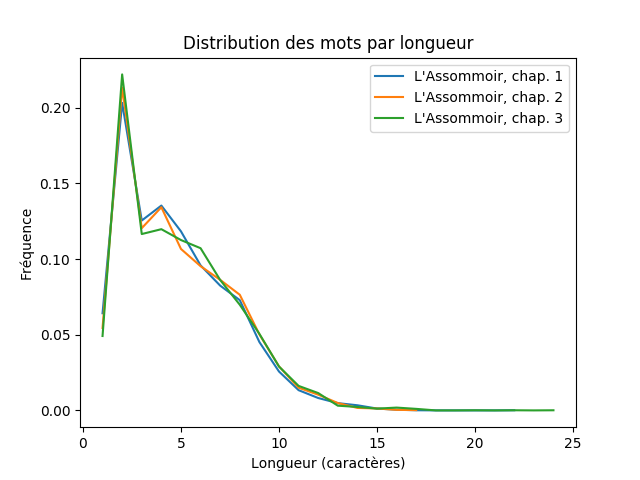
J’ai commencé par comparer les trois premiers chapitres de L’Assommoir de Zola.
Il s’agit de trois chapitres d’une même œuvre par un seul auteur. Cela donne une idée de la variabilité liée au choix de l’échantillon. Chaque chapitre fait quelques dizaines de kilo-octets.
On observe assez peu de variabilité, ce qui indique que la taille de l’échantillon semble suffisamment grande pour mon usage. Le pic remarquable correspond aux mots de deux lettres (tels que un, et, de, es, ai, …)
Variabilité liée au style
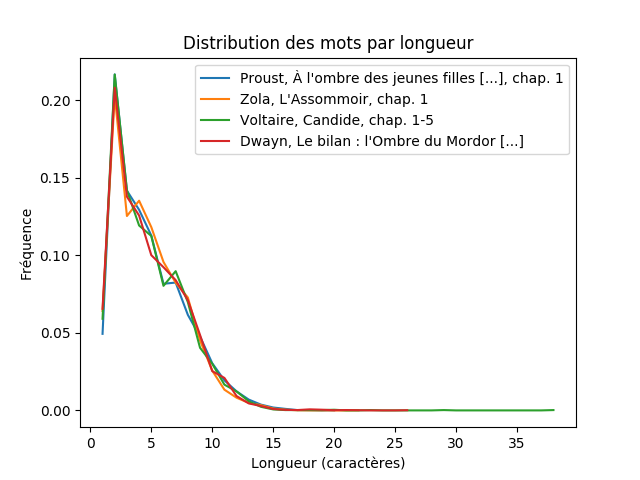
J’ai voulu ensuite comparer différents auteurs. Les heureux élus sont Zola, Voltaire, Proust et Dwayn.
L’idée derrière cette comparaison est de voir la variabilité liée au style des auteurs. Il s’agit d’une comparaison pour des extraits de taille approximativement comparables. Le plus petit texte est celui de Voltaire (environ 30 ko), le plus long celui de Proust (environ 400 ko).
La variabilité n’est pas vraiment notable, on peut donc dire que chaque auteur utilise des mots dont la longueur est représentative du français écrit usuel.
Statistiques générales
La longueur moyenne d’un mot est de 4,8 caractères.
Le mot médian a une longueur de 4 caractères.
Ses valeurs sont sujettes à prendre avec précaution puisque la séparation en mots est faite avec plein de défauts (voir la section suivante).
Données et outils
Données
J’ai utilisés les sources suivantes :
- L’Assommoir sur Wikisource,
- Candide sur Wikisource
- À l’ombre des jeunes filles en fleurs sur Wikisource,
- Bilan : l’Ombre du Mordor & l’Ombre de la Guerre sur Zeste de Savoir.
Outils
J’ai utilisé un script Python (ci-dessous) pour réaliser ces analyses rudimentaires. Il a des défauts assez majeurs, comme le fait d’ignorer la ponctuation et d’ignorer les apostrophes pour couper les mots.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | import matplotlib.pyplot as plt # TODO: improve error management def read_text(text_file): """Read a text in a text file.""" with open(text_file, 'r') as text_file: text = text_file.read() return text # TODO: manage punctuation # TODO: improve to also split at quotes def split_into_words(s): """Split a string into words.""" return str.split(s) def count_words_by_length(text): """Count the number of words of each lengths.""" words = split_into_words(text) print(words) words_length = list(map(len, words)) lengths = list(range(min(words_length), max(words_length) + 1)) counts = [] for i in range(len(lengths)): counts.append(words_length.count(lengths[i])) return lengths, counts def counts_to_frequencies(lengths, counts): total = sum(counts) frequencies = [count/total for count in counts] return lengths, frequencies def plot_distr(lengths, frequencies, label): """Plot the frequencies of words per length for a text.""" plt.figure() plt.plot(lengths, frequencies) plt.xlabel('Longueur (caractères)') plt.ylabel('Fréquence') plt.title('Distribution du nombre de mots par longueur') plt.legend([label]) plt.show() def plot_distr_compare(lengths_freqs_label_list): """Plot the frequencies of words per length for many texts.""" plt.figure() lengths, freqs, labels = zip(*lengths_freqs_label_list) for i in range(len(lengths)): plt.plot(lengths[i], freqs[i]) plt.xlabel('Longueur (caractères)') plt.ylabel('Fréquence') plt.title('Distribution des mots par longueur') plt.legend(labels) plt.show() if __name__ == '__main__': # input_files = ["zola-assommoir-chap1.txt", "zola-assommoir-chap2.txt", "zola-assommoir-chap3.txt"] # labels = ["L'Assommoir, chap. 1", "L'Assommoir, chap. 2", "L'Assommoir, chap. 3"] input_files = ["proust-jeunes_filles_fleurs_chap1.txt", "zola-assommoir-chap1.txt", "voltaire-candide-chap1-5.txt", "dwayn-mordor.txt"] labels = ["Proust, À l'ombre des jeunes filles [...], chap. 1", "Zola, L'Assommoir, chap. 1", "Voltaire, Candide, chap. 1-5", "Dwayn, Le bilan : l'Ombre du Mordor [...]"] sets = [] for file, label in zip(input_files, labels): text = read_text(file) l, c = count_words_by_length(text) l, f = counts_to_frequencies(l, c) sets.append((l, f, label)) plot_distr_compare(sets) |

















{kind=link}