Les couches transport et réseau sont les plus importantes du modèle OSI. Nous allons donc les examiner en détail. Ce chapitre sert d’introduction à l’univers de la couche de transport.
Présentation
Le rôle de la couche transport est de rendre possible la communication logique entre applications. En anglais, on parle de logical end-to-end communication.
Pourquoi « logique » ?
Une communication logique, c’est une communication « distante », dans le sens où les hôtes communiquant ne sont pas forcément reliés physiquement, mais ils ne s’en rendent pas compte. Pour eux, ils sont connectés et peuvent communiquer, c’est tout ce qu’ils savent. Le reste, ils s’en fichent !
La couche transport établit une communication logique entre les processus d’applications. Cela signifie qu’un programme, une application sur votre ordinateur utilise la couche 4 pour établir une transmission avec une autre application. Seule cette communication lui est connue, tous les autres échanges de votre machine lui sont hors de portée (et accessoirement, elle n’en a rien à faire  ).
).
Prenons deux hôtes A et B qui s’échangent des fichiers avec le protocole BitTorrent, que nous avons vu précédemment. Ils utilisent chacun un client pour partager leurs torrents. Donc il s’agit d’un même type d’application dans la transmission et la réception. Voilà pourquoi on parle de end-to-end application communication, ce qui en français peut se traduire par « bout-en-bout ». Par « bout-en-bout », la pensée exprimée est que la communication entre les couches se fait de façon parallèle.
Voici un schéma illustrant ce principe de communication parallèle :

Ce principe reste valable pour les autres couches du modèle OSI ou TCP-IP. Chaque couche communique parallèlement avec sa couche « homologue ». La couche application de l’hôte émetteur communique directement avec la couche application de l’hôte récepteur, de même que la couche transport de l’émetteur communique directement avec la couche transport de l’hôte récepteur.
Si c’est un peu confus, référez-vous à la section traitant du principe d’encapsulation. Si vous vous souvenez bien, nous avons vu que la couche réseau, par exemple, ajoutait un en-tête au SDU de la couche transport, le transformant ainsi en un PDU. Une fois au niveau de la couche réseau du récepteur, cet en-tête était lu et supprimé. Ces deux couches (réseau) communiquaient donc parallèlement.
L’histoire de Couic le message
Le rôle de la couche transport est bien sûr d’assurer le transport des messages, mais parfois, ces derniers sont trop longs. Pour faire une analogie, une voiture sert au transport routier, mais on ne peut pas y faire rentrer des objets forts volumineux. Celles et ceux qui ont essayé de déménager un lit avec une citadine savent bien de quoi on parle. Eh bien en réseau, l’avantage, c’est qu’on peut découper quand ça ne rentre pas !
Quand l’hôte A envoie un message, il utilise une application comme un client de messagerie. Cette application lui donne accès aux services réseaux pour envoyer un mail, donc le protocole SMTP sera utilisé, par exemple. Une fois ce SDU reçu par la couche transport, il sera converti en un PDU, comme nous l’avons vu. La couche transport, qui est aussi responsable de la fragmentation des unités de données, va « couper » ce SDU en plusieurs chaînes (ou morceaux) qu’on appelle « chunks » en anglais. À chaque « morceau » sera ajouté un en-tête. Le SDU reçu par la couche transport sera donc « brisé » en 4 PDU distincts, par exemple. 
Voici deux schémas illustrant cela :
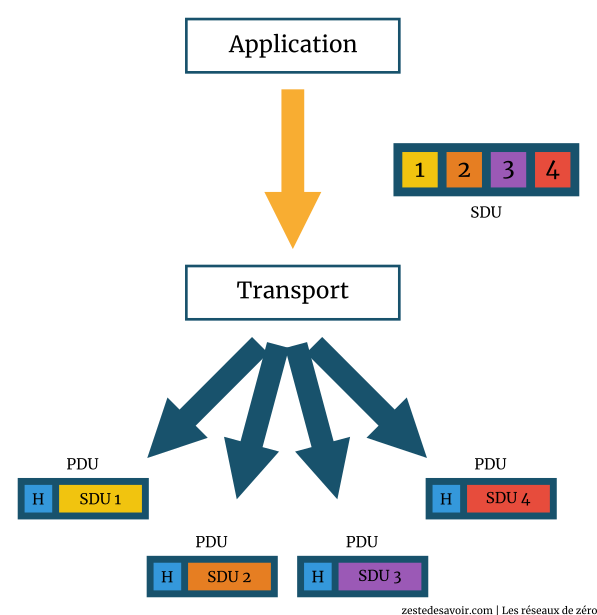
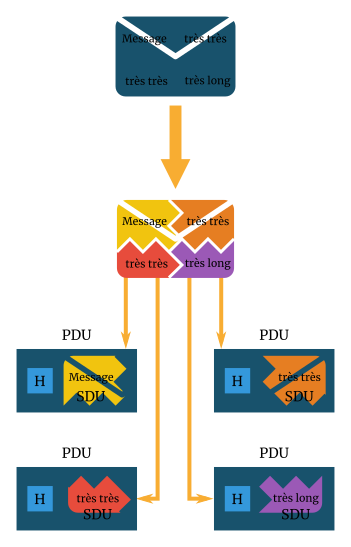
Ces 4 PDU seront envoyés à la couche C-1 (la couche réseau en l’occurrence). Nous allons sauter ce qui se passe au niveau des 3 dernières couches pour l’instant, car nous ne les avons pas encore étudiées en détail. Mais vous devez avoir une idée générale de ce qui se passe grâce au survol des couches du modèle OSI que nous avons effectué dans l’introduction aux modèles de communication.
Du côté de l’hôte récepteur B, voici ce qui va se passer. La couche transport de cet hôte recevra les 4 PDU originaux, lira leurs en-têtes et les rassemblera en une seule unité de donnée, après avoir supprimé les en-têtes bien sûr (n’oubliez pas les règles du principe de l’encapsulation ). Finalement, le « message » sera transmis au processus de l’application réceptrice.
C’est quoi un processus ?
On parle plus de processus en programmation qu’en réseau, mais bon, il est important que vous sachiez ce que c’est. Un processus est une instance d’une application en cours d’exécution (l’application qui est actuellement exécutée). Parfois, un processus peut être constitué de plusieurs threads (des « sous-processus », en quelque sorte) qui exécutent des instructions au même moment.
C’est tout ce que vous avez besoin de savoir pour l’instant.
La relation entre la couche transport et la couche réseau
Vous n’êtes pas sans savoir que, selon le principe des modèles de communication, chaque couche communique avec une couche adjacente (soit supérieure, soit inférieure). Pour vous rafraîchir la mémoire, voici le schéma que nous avons utilisé pour illustrer ce principe de communication entre couches :
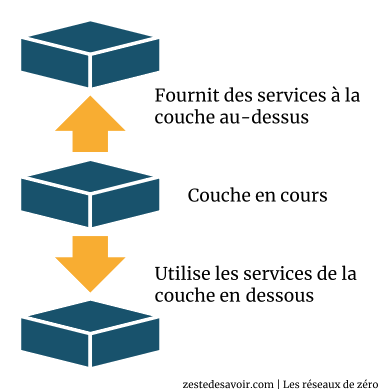
Il se trouve que la couche transport est juste avant la couche réseau dans l’ordre décroissant des couches (de haut en bas, de la couche 7 à la couche 1, de l’application à la couche physique). Il va donc sans dire que la couche transport communique avec la couche réseau.
Nous allons donc voir la relation qui les lie.
Pour commencer, nous avons vu que les deux couches permettent d’établir une communication logique. La couche transport établit une communication logique entre les processus des applications, tandis que la couche réseau établit une communication logique entre les hôtes. Nous allons une fois de plus étudier un scénario.
Nous allons imaginer que, dans notre scénario, il y a deux maisons géographiquement opposées : l’une à l’est et l’autre à l’ouest. Chaque maison héberge une douzaine d’enfants. Dans chacune des maisons vivent des familles, de telle sorte que les enfants de la maison à l’est (appelons-la Maison-Est, originalité quand tu nous tiens… ) et ceux de la maison à l’ouest (Maison-Ouest) soient cousins.
Tout est clair jusqu’alors ? Nous ne voulons pas perdre quelqu’un en chemin.
Chacun des enfants d’une maison écrit à chacun des enfants de l’autre maison, chaque semaine. Chaque lettre est mise dans une enveloppe. Ainsi, pour 12 lettres, nous avons 12 enveloppes. Les lettres sont envoyées par le biais de la poste. Nous avons donc un taux de transmission de 288 lettres par semaine (12 enfants x 12 lettres x 2 maisons). Dans la Ville-Est (celle dans laquelle se trouve Maison-Est), il y a un jeune du nom de Pierre (vous devez avoir l’habitude  ). Dans la Ville-Ouest (celle dans laquelle se trouve Maison-Ouest), il y a un jeune homme du nom de Jean.
). Dans la Ville-Ouest (celle dans laquelle se trouve Maison-Ouest), il y a un jeune homme du nom de Jean.
Pierre et Jean sont tous deux responsables de la collecte des lettres et de leur distribution dans leurs maisons respectives : Pierre pour Maison-Est et Jean pour Maison-Ouest.
Chaque semaine, Pierre et Jean rendent visite à leurs frères et sœurs, collectent les lettres et les transmettent à la poste. Quand les lettres arrivent dans la Ville-Est, Pierre se charge d’aller les chercher et les distribuer à ses frères et sœurs. Jean fait également le même travail à l’ouest.
Vous n’êtes pas largués ? Par prudence, voici un schéma illustrant les étapes d’échanges entre les deux familles :
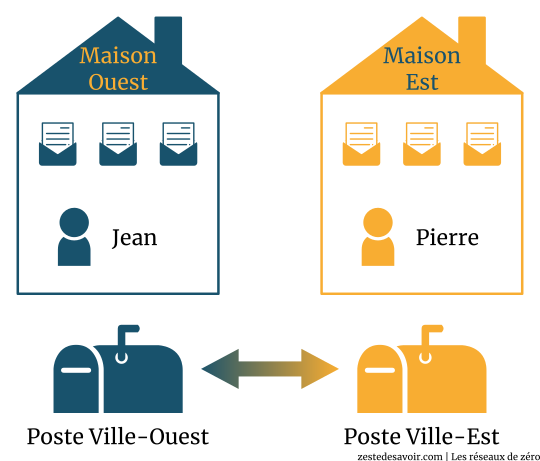
Le schéma est assez explicite, pas besoin de nous y attarder. Les cousins de Maison-Est écrivent des lettres, Pierre (le grand frère) les collecte et les envoie à la poste de sa ville. La poste de la Ville-Est enverra les lettres à la poste de la Ville-Ouest. Jean va les chercher à la poste et les distribue aux cousins de la Maison-Ouest.
Dans le schéma, nous avons fait en sorte que ces « blocs » soient dans un ordre qui explicite la procédure de transmission. Mais, en fait, pour mieux comprendre cela, il faut suivre la structure semblable au modèle OSI ou TCP-IP, donc une structure de pile (couches superposées). Ceci étant, nous allons réarranger ces blocs ou étapes (qui sont en fait des couches) de manière à retrouver la structure du modèle OSI. Cela donne ceci :
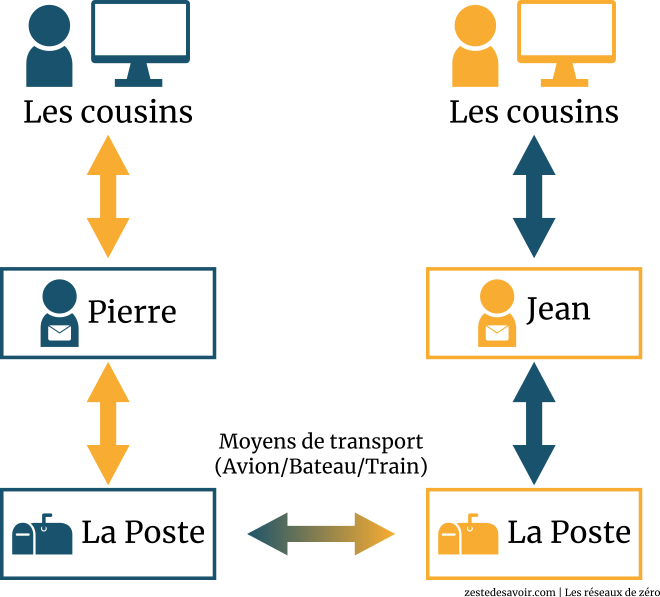
Comme vous pouvez le voir sur le schéma, nous avons mis « Moyens de transport » entre les deux postes. Les deux postes ne sont pas dans la même ville, alors comment les lettres seront-elles envoyées ? Par le train ? Par avion ? Il y a plusieurs moyens disponibles. Retenez bien cela !
Maintenant, remplaçons X par sa valeur.
Dans cet exemple, le bureau de poste pourvoit une connexion logique entre les deux maisons. Le service du bureau de poste transporte les lettres de maison en maison et non de personne en personne directement, car il y a un intermédiaire.
Pierre et Jean établissent une communication logique entre les cousins (les enfants de Maison-Est et les enfants de Maison-Ouest). Ils collectent et distribuent les lettres à leurs frères et sœurs. Si nous nous mettons dans la perspective (vue, vision, conception) des cousins, Pierre et Jean jouent le rôle du bureau de poste, bien qu’ils ne soient que des contributeurs. Ils font partie du système de transmission des lettres ; plus précisément, ils sont le bout de chaque système.
Que vous le croyiez ou non, cette analogie explique très bien la relation qu’il y a entre la couche réseau et la couche transport, ou plutôt l’inverse pour respecter l’ordre. 
- Les maisons, dans notre exemple, représentent les hôtes dans un réseau.
- Les cousins qui vivent dans les maisons représentent les processus des applications.
- Pierre et Jean représentent la couche transport (un protocole de cette couche). Ce sera soit UDP, soit TCP.
- Le bureau de poste représente la couche réseau des modèles de communication (plus précisément, un protocole de cette couche). Le plus souvent, c’est le protocole IP qui est utilisé.
Un schéma n’est jamais de trop.
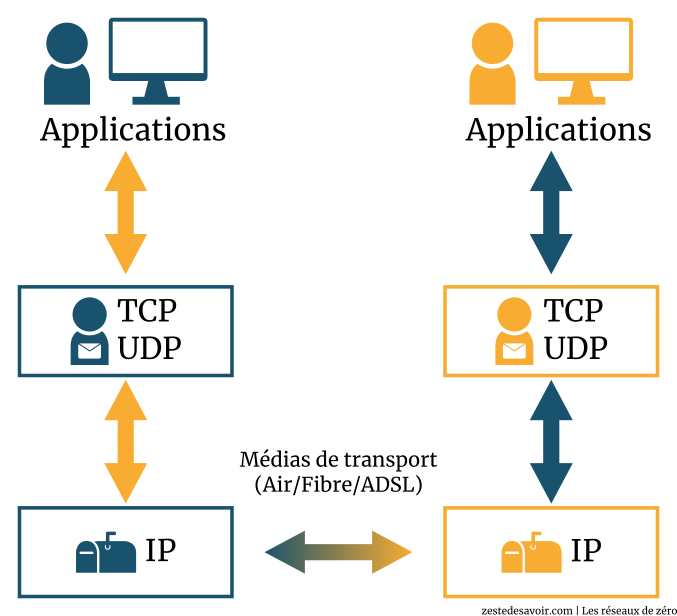
Ainsi, nous pouvons remarquer que le début de la communication (l’écriture des lettres) à l’est commence par des processus d’une application (les cousins). C’est normal, nous sommes dans la couche application. Ensuite, nous nous retrouvons avec plusieurs PDU (les enveloppes) qu’un protocole (TCP ou UDP) de la couche transport (Pierre) prendra et transmettra à un protocole de la couche réseau (le bureau de poste).
Dans la procédure de réception, un protocole de la couche réseau (le bureau de poste) dans le réseau (la ville) de l’hôte récepteur (Maison-Ouest) recevra les PDU (enveloppes) qui proviennent d’un protocole de la couche réseau (le bureau de poste) du réseau (la ville) de l’hôte émetteur.
Tout est clair ? Continuons.
Ce protocole va donc lire les en-têtes et donner les PDU à un protocole de transport (Jean). Ce dernier va transporter les données à l’hôte récepteur (Maison-Ouest) et les distribuer aux processus d’applications (cousins).
Voilà, nous avons remplacé X par sa valeur. Mais ce n’est pas fini, gardez vos ceintures attachées et continuons.
Comme vous pouvez le comprendre à partir de cette analogie, Pierre et Jean ne sont impliqués que dans des tâches précises qui concernent leurs maisons respectives. Par exemple, ils distribuent les lettres et les transmettent à la poste. Mais ils n’ont rien à voir avec les activités propres à la poste, telles que le tri des lettres. Il en est de même pour les protocoles de transport. Ils sont limités au « bout » des échanges. Ils transportent les messages (enveloppes) d’un processus à la couche réseau et de la couche réseau à un processus. Ce sont des fonctions « bout-en-bout » (end-to-end).
Personne n’est perdu ? Ça serait embêtant de faire demi-tour pour chercher ceux qui se sont paumés.
Continuons !
Nous allons supposer qu’un jour, Pierre et Jean partent en vacances. Ils se feront donc remplacer par une paire de cousins, disons Jacques et André. Étant donné que ces deux derniers sont nouveaux, ils n’ont donc pas assez d’expérience dans la gestion et la distribution des lettres. Par conséquent, il peut arriver que, de temps en temps, ils fassent tomber des enveloppes en les emmenant à la poste ou en allant les chercher. Donc, de temps en temps, il y a des pertes d’informations (lettres). Puisqu’ils ont du mal à s’habituer, ils seront plus lents que Pierre et Jean. Donc la transmission des lettres à la poste et leur distribution aux cousins prendront un peu plus de temps.
Il se trouve donc que la paire Jacques et André n’offre pas le même modèle de service que la paire Pierre et Jean.
Par analogie, dans un réseau informatique, il est tout à fait possible qu’il y ait plusieurs protocoles de transport. D’ailleurs, vous savez d’ores et déjà que les plus utilisés sont TCP et UDP. Ces protocoles de transport offrent des modèles de services différents entre applications. Il est important de noter que la qualité des services offerts par Pierre et Jean dépend étroitement de la qualité de service offerte par le bureau de poste. C’est logique, en fait !
Si la poste met trois jours, par exemple, pour trier les courriers reçus, est-ce que Pierre et Jean peuvent être tenus responsables de ce délai ? Peuvent-ils transmettre les lettres aux cousins plus vite que ne peut trier la poste ? Non, bien entendu.
De même, dans un réseau informatique, la qualité de service du protocole de transport dépend de la qualité de service du protocole de réseau. Si le protocole de la couche réseau ne peut garantir le respect des délais pour les PDU envoyés entre les hôtes, alors il est impossible pour les protocoles de transport de garantir le respect des délais de transmission des unités de données (messages) transmises entre applications (processus d’applications).
La qualité de service offert par Pierre et Jean dépend étroitement de la qualité des services offerts par la poste, mais l’inverse n’est pas vrai. C’est logique.
Un exemple ?
Pas de problème ! Jean, par exemple, peut garantir à ses cousins que, coûte que coûte, « vos lettres seront transmises ». Mais la poste peut perdre des lettres lors du tri, par exemple. Jean a offert un service fiable (reliable en anglais ) alors que la poste a offert un service non fiable (unreliable). Un autre exemple est que Jean peut garantir à ses frères qu’il ne lira pas leurs lettres. Mais qui sait ce qui se passera à la poste ? Peut-être qu’un type méchant pourrait ouvrir une enveloppe, lire la lettre, la refermer et la transmettre !  Pire encore, au niveau de la poste, le monsieur peut lire, faire une photocopie et envoyer l’original mais garder une copie. Il a brisé la confidentialité de la transmission. Ceci est un concept très important en sécurité. Un protocole de transmission peut offrir des services de chiffrement pour protéger et garantir la confidentialité des unités de données mais ces dernières peuvent être interceptées au niveau de la couche réseau par l’attaque de l’homme du milieu (MITM, Man In The Middle attack), par exemple.
Pire encore, au niveau de la poste, le monsieur peut lire, faire une photocopie et envoyer l’original mais garder une copie. Il a brisé la confidentialité de la transmission. Ceci est un concept très important en sécurité. Un protocole de transmission peut offrir des services de chiffrement pour protéger et garantir la confidentialité des unités de données mais ces dernières peuvent être interceptées au niveau de la couche réseau par l’attaque de l’homme du milieu (MITM, Man In The Middle attack), par exemple.
Conclusion
Cette première sous-partie est un vrai baptême du feu en contenu, il faut l’avouer. Nous avons vu à quoi servait la couche transport. Ce n’est pas fini ! Ce que nous vous avons montré n’est qu’une présentation introductive. L’exploration de la couche de transport se fera en plusieurs chapitres, donc il y a plein de choses à apprendre. Nous avons simplement vu la différence entre la communication logique offerte par la couche de transport et celle offerte par la couche de réseau. Nous avons profité de notre super exemple ( ) pour introduire subtilement le principe d’une communication fiable et non fiable. Vous l’ignorez peut-être, mais dans cet exemple, il y a de l’UDP inside.  Nous y reviendrons.
Nous y reviendrons.
Ce qu’il faut retenir est que la couche transport établit une communication logique entre processus tandis que la couche réseau établit une communication logique entre hôtes.
À votre service
Continuons notre exploration en nous intéressant à ce que la couche 4 peut faire. Nous avons vu que le rôle de chaque couche était d’offrir des services pour les couches adjacentes. La couche transport n’échappe pas à la règle. Cette couche est un ensemble de services. Ces services sont généralement fournis par un protocole ou une bibliothèque externe. Explorons les concepts les plus importants des services offerts par la couche 4. Nous sommes toujours dans un chapitre d’introduction, il ne s’agit là que d’un passage en revue !
- Communication orientée connexion : de l’anglais connection-oriented communication, ce service est bénéfique pour plusieurs applications, notamment parce qu’il interprète la connexion établie entre processus comme étant un flux de données. Ce flux de données n’est en fait qu’une séquence d’octets (8 bits). Ainsi, il faudrait donc gérer l’orientation des octets, qui est également un service de cette couche. Il est plus facile de gérer ce genre de communication que d’avoir affaire au mode orienté non connexion.
- L'ordre de livraison : nous savons que la couche transport fragmente les données en plusieurs séquences. La couche réseau ne peut pas garantir que les données envoyées arriveront exactement dans l’ordre même de leur envoi. Rappelez-vous, nous avons parlé de cela en introduction aux protocoles, mais sous un autre nom : le contrôle de séquences. Eh oui, c’est la couche transport qui se charge de gérer les séquences, de s’assurer que l’ordre de livraison est le même que l’ordre d’envoi. Cette gestion de séquences se fait en utilisant un numéro de séquence.
- Fiabilité : dans la section précédente, dans l’exemple des cousins et postes, nous avons évoqué implicitement ce qui régissait le principe d’une communication fiable. Le but de ce service est de vérifier l’intégrité des paquets car ces derniers peuvent se perdre en cours de transmission à cause de la congestion du réseau. Cette vérification d’intégrité se fait souvent en utilisant un code de détection d’erreurs tel que la somme de contrôle (checksum). La fiabilité consiste aussi à s’assurer que le récepteur reçoit chaque segment qui lui est envoyé. Il faudrait donc également être en mesure de renvoyer les séquences qui se sont perdues : cela se fait par une requête automatique de renvoi.
- Contrôle de flux : il peut être important de réguler le débit au sein même d’un flux. Un certain protocole est capable de s’adapter à son environnement réseau pour adapter sa propre vitesse de communication.
- Contrôle de congestion : il sert à contrôler le trafic dans un réseau afin de réduire la congestion (saturation) d’un réseau, en évitant que les clients n’utilisent intensivement les liens de connexion qui sont déjà extrêmement utilisés.
- Multiplexing / demultiplexing : nous ne pouvons pas vous parler de multiplexing et demultiplexing sans aborder les ports de communication, ce que nous allons faire dans le chapitre suivant. Patience !
Nous allons nous pencher sur ces services dans les prochains chapitres. Mais vu la quantité d’informations contenues dans celui-ci, on va faire une pause, d’abord ! 
Ne passez pas tout de suite au chapitre suivant ! Prenez d’abord le temps de bien assimiler tout ce que vous avez appris dans ce chapitre.
…
Ça y est ? Alors l’exploration continue !