Nous avons étudié la couche 3 et le routage, mais nous n’avons pas encore étudié le protocole IP dans le détail. Ce sera l’objet de ce dernier chapitre sur la couche réseau. Après ce que vous avez subi précédemment, ça va vous paraitre tellement simple ! 
L'en-tête IPv4
Commençons par regarder à quoi ressemble un paquet IP, en particulier au niveau en-tête. Spoiler : ça commence par le numéro de version.
Ah oui, on avait vu qu’il y a IPv4 et IPv6 ! Mais c’est pas juste une histoire d’adresses ?
Hm, c’est un peu plus complexe que ça.  En premier lieu, regardons l’en-tête d’un paquet IPv4.
En premier lieu, regardons l’en-tête d’un paquet IPv4.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Version | IHL | DSCP | ECN | Longueur totale | |||||||||||||||||||||||||||
4 | 32 | Identification | Flags | Fragment offset | |||||||||||||||||||||||||||||
8 | 64 | Time To Live | Protocole | Somme de contrôle de l’en-tête | |||||||||||||||||||||||||||||
12 | 96 | Adresse IP source | |||||||||||||||||||||||||||||||
16 | 128 | Adresse IP destination | |||||||||||||||||||||||||||||||
20 | 160 | Options si IHL > 5 (facultatif) | |||||||||||||||||||||||||||||||
24 | 192 | ||||||||||||||||||||||||||||||||
28 | 224 | ||||||||||||||||||||||||||||||||
32 | 256 | ||||||||||||||||||||||||||||||||
Comme évoqué, le premier élément qu’on trouve est le numéro de version, sur 4 bits. Avec IPv4, ce champ vaut… 4, il n’y a pas de piège.
Vient ensuite l’IHL, pour Internet Header Length. Cette information correspond à la longueur de l’en-tête du paquet, et est stockée sur 4 bits.
…
…
On peut apercevoir vos mines sceptiques depuis très, très loin. Quel est l’intérêt de cette information, pourquoi à cet endroit, comment peut-on indiquer une taille d’en-tête sur 4 bits, ce qui donne une valeur maximale de 15, alors qu’il semble bien plus gros, pourquoi certaines clémentines ont des pépins et pas les autres !?
Pour les clémentines, le mystère reste entier. Pour le reste, on peut constater que le protocole IPv4 n’a pas été conçu pour être un modèle de sobriété. IPv4 connait un système d’options qui viennent s’ajouter au bout de l’en-tête. On ne sait pas, a priori, quelle taille ces options représentent, ni même combien il y en a. Pour délimiter où s’arrête l’en-tête, et donc savoir quand commence le SDU, il faut connaitre la longueur du header. Le processus de la couche réseau qui reçoit ce paquet s’arrêtera de décapsuler une fois l’en-tête parcouru grâce à cette information.
Maintenant, passons au problème de taille. 4 bits pour un en-tête qui fait minimum 20 octets, c’est peu. L’astuce, c’est que cette valeur correspond au nombre de blocs de 4 octets. Autrement dit, il faut multiplier cette valeur par 4 pour savoir le nombre d’octets total de l’en-tête. Et si le header ne fait pas un nombre d’octets multiple de 4 à cause d’options, on rajoutera des zéros au bout pour que ça fasse quand même un multiple de 4. Oui, Internet a été conçu en partie par des gens tordus. 

Vient ensuite le DSCP, pour Differentiated Services Code Point. Il s’agit d’un code, sur 6 octets, qui indique le type de service contenu dans le paquet. Il est utilisé à des fins de qualité de service. Pour bien comprendre de quoi on parle, explicitons ces notions.
Différentes applications n’ont pas nécessairement les mêmes besoins en termes de qualité de réseau pour fonctionner. Nous avons vu, quand nous parlions des protocoles de transport, que la VoIP a besoin que les données soient transmises avec régularité et avec peu de délai. Par contre, des flux de contrôle du réseau peuvent nécessiter d’être transmis le plus rapidement possible mais sans contrainte de gigue. À l’inverse, certaines transmissions comme des e-mails peuvent se permettre d’arriver plus tard, ce mode de communication n’étant pas prévu pour être instantané. On a là divers degrés de priorité. C’est tout l’objet de la problématique de la qualité de service, abrégée QoS : comment prioriser certains flux par rapport à d’autres quand il y a des besoins particuliers ? Le champ DSCP est une solution : les routeurs le lisent et, s’ils ne peuvent pas traiter tous les paquets en même temps, vont prioriser en fonction du type de service. Vous vous souvenez des histoires de cousins qui s’envoient des lettres ? La Poste correspondait à la couche réseau, dans notre analogie. Ici, le champ DSCP, c’est un peu comme le type de timbre utilisé : il peut être prioritaire, économique, etc.
Mais, parce qu’il y a un mais, on ne peut pas faire n’importe quoi. Vous n’imaginez quand même pas qu’on peut mettre un tag de priorité à nos paquets qu’on envoie sur Internet ? Techniquement, on peut, mais notre opérateur aura vite fait de le remettre à zéro. Ce système ne fonctionne que sur un réseau DiffServ, c’est-à-dire qui opère une différenciation entre les services. Si un routeur, à un endroit, a décidé1 de ne pas faire le DiffServ, au mieux tous les paquets sont traités de manière égale à cet endroit, au pire le champ est remis à zéro. Le DSCP est donc réservé aux réseaux d’entreprise qui ont besoin d’assurer une qualité de service à certaines applications.
Le champ suivant est l’ECN. Nous l’avons déjà étudié avec le contrôle de congestion. Il n’y a pas grand-chose à ajouter, sinon qu’il est codé sur 2 bits et peut donc prendre 4 valeurs différentes. 00 signifie que l’ECN n’est pas supporté, 01 et 10 indiquent tous deux que l’ECN est supporté, et 11 alerte le destinataire d’une congestion sur le réseau, comme expliqué dans le chapitre précédemment cité.
La valeur qui vient ensuite correspond à la longueur totale du paquet, en-tête et données inclus. Pas de bizarreries ici, elle correspond bien au nombre d’octets total et s’exprime sur 2 octets (16 bits).
Vous êtes toujours là ? Félicitations, vous savez maintenant interpréter les 4 premiers octets d’un paquet IP ! Les 4 octets suivants concernent la fragmentation, nous y consacrerons une section entière. Passons tout de suite à la troisième ligne du tableau représentant le header.
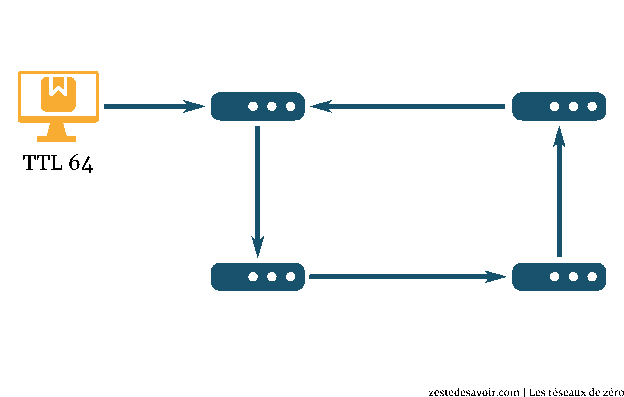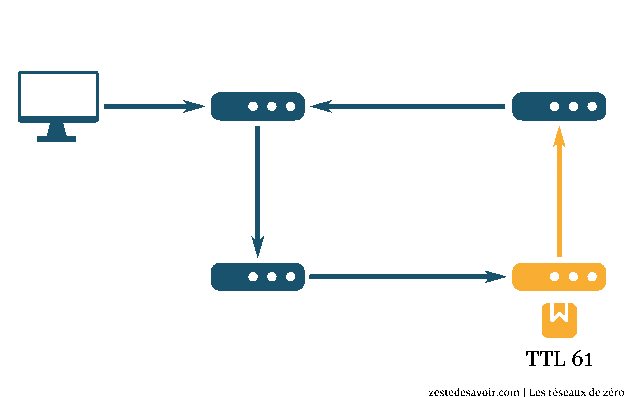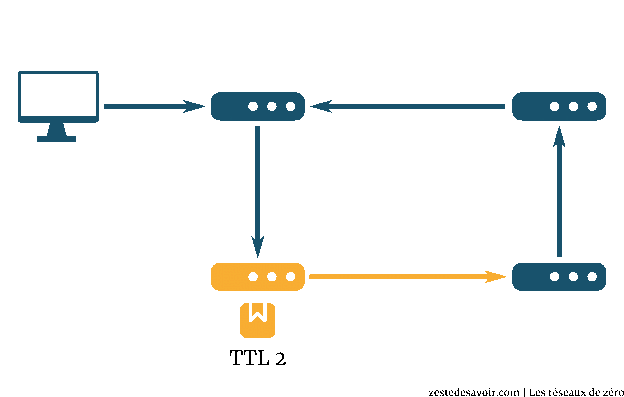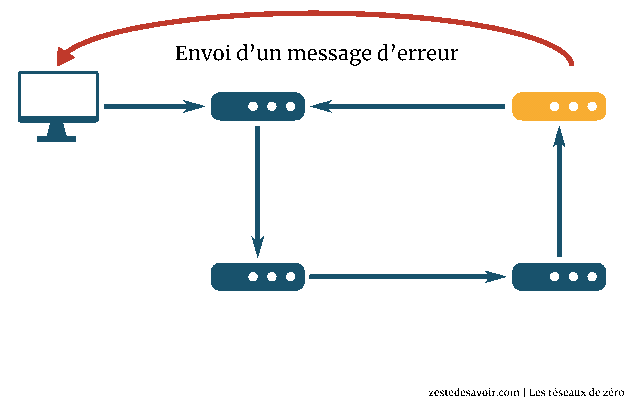
Nous rencontrons alors le TTL. C’est la durée de vie du paquet. Il ne s’agit pas d’un nombre de secondes ou de minutes, mais d’un nombre de sauts. Nous avons vu dans les chapitres sur le routage que lorsqu’un paquet passe un routeur dans le but d’atteindre sa destination, cela correspond à un saut. À chaque saut, le routeur décrémente ce TTL, c’est-à-dire retire 1 à sa valeur. Quand elle atteint zéro… Boum ! Le paquet est jeté comme un malpropre.
Quoi ? Mais c’est dégueulasse ! Ça veut dire que les paquets peuvent disparaitre sans raison comme ça, dans l’indifférence générale ? 
Sans raison, certainement pas. Ce système existe afin d’éviter qu’un paquet ne se retrouve pris au piège dans une boucle. Si, pour une raison quelconque comme une erreur de configuration, des routeurs sont amenés à se renvoyer indéfiniment un paquet, le pauvre est condamné à tourner tel un satellite en orbite. En étant terre-à-terre, le problème ici est que les routeurs vont travailler et finir par saturer pour rien. Le système de TTL permet d’éviter ces conséquences : au bout d’un certain nombre de sauts, le paquet est jeté. Cette valeur est stockée sur 1 octet, elle peut donc aller jusqu’à 255. Les valeurs les plus courantes sont 64, 128 et 255.
Toutefois, le paquet n’est pas juste effacé. Le routeur qui élimine un paquet envoie un message à l’expéditeur (l’adresse IP source) pour le prévenir que la destination est injoignable. Pour ce faire, il utilise le protocole ICMP, que nous étudierons en fin de chapitre.
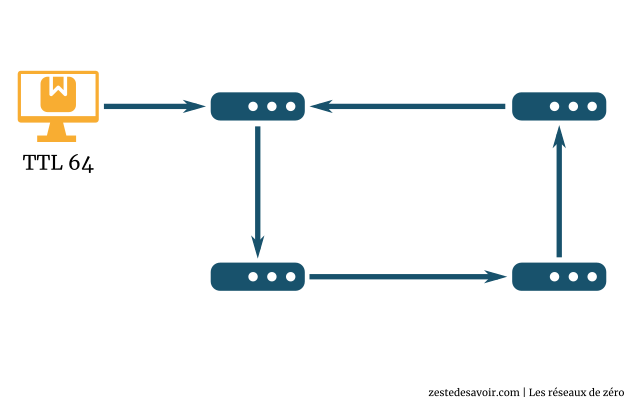
Si l’animation ci-dessus ne s’affiche pas ou ne se lance pas, cliquez ici.
{kind=link}
Le champ suivant porte bien son nom : « protocole ». Il précise quel est le protocole utilisé dans les données utiles. Cela peut être TCP, UDP, OSPF ou bien d’autres. Cette valeur, sur un octet, permet au destinataire de savoir à quel processus transmettre le SDU.
Nous en arrivons à la somme de contrôle de l’en-tête, en anglais « header checksum ». Il s’agit de la somme de contrôle de l’en-tête du paquet. Oui, juste de l’en-tête. IP est un peu fainéant et considère que ce n’est pas à lui de faire la checksum de son SDU. Pour ne pas vous noyer, le détail de la méthode utilisée est dans l’annexe sur les sommes de contrôle.
Comme le TTL varie à chaque saut, et qu’il fait partie de l’en-tête, cette somme de contrôle est forcément modifiée par chaque routeur.
On approche de la fin de l’en-tête IPv4. Passons sur les adresses source et destination, vous en avez assez soupé dans la partie 3 du cours.
Enfin, nous arrivons aux options. Et nous ne nous attarderons pas dessus : soit elles ne servent à rien, soit elles sont expérimentales, soit elles ne sont pas supportées. Pour la culture, nous vous renvoyons vers cette fiche de FrameIP pour que vous vous fassiez une idée du sujet.
Un sacré bazar, cet en-tête IPv4. Rassurez-vous, à ce niveau, IPv6 est beaucoup mieux fichu !
- Ou plutôt, a été configuré pour. ↩
L'en-tête IPv6
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Version | Classe de trafic | Flow label | |||||||||||||||||||||||||||||
4 | 32 | Payload length | Next header | Hop limit | |||||||||||||||||||||||||||||
8 | 64 | Adresse source | |||||||||||||||||||||||||||||||
12 | 96 | ||||||||||||||||||||||||||||||||
16 | 128 | ||||||||||||||||||||||||||||||||
20 | 160 | ||||||||||||||||||||||||||||||||
24 | 192 | Adresse destination | |||||||||||||||||||||||||||||||
28 | 224 | ||||||||||||||||||||||||||||||||
32 | 256 | ||||||||||||||||||||||||||||||||
36 | 288 | ||||||||||||||||||||||||||||||||
Et on entame avec une bonne nouvelle : une bonne partie des champs sont les mêmes que pour IPv4 ! « Version », comme son nom l’indique, correspond à la version d’IP : on aura donc toujours 6 ici. « Classe de trafic » est un champ représenté sur 8 bits dans le tableau. En réalité, les 6 premiers correspondent au DSCP, les 2 derniers à l’ECN. « Hop limit » est équivalent au TTL. Quant aux adresses source et destination, inutile de s’y attarder…
Les nouveautés sont donc « flow label », « payload length » et « next header ». Commençons par ce dernier. Ce champ sur un octet désigne ce qui se trouve après l’en-tête.
C’est-à-dire le protocole encapsulé, comme le champ « protocole » en IPv4, en somme ! Pourquoi compliquer les choses et appeler ça différemment ? 
Hmm, ce n’est pas exactement ça. Dans la plupart des cas, on aura effectivement un code représentant le protocole du SDU. Mais il peut aussi faire référence… à une extension d’en-tête.
La structure de l’en-tête IPv6 est beaucoup plus claire et moins fouillis qu’avec IPv4. Ici, le header peut être complété par des informations additionnelles, comparable aux options IPv4. On parle alors d’en-tête additionnel. L’avantage, c’est que comme ces « options » sont considérées comme des headers, elles incluent aussi un champ « next header », et ainsi de suite ! On a donc une chaine d’en-têtes beaucoup plus faciles à identifier et séparer qu’en IPv4, d’autant plus que leur taille est toujours de 8 octets ou un multiple (16, 24 octets…).
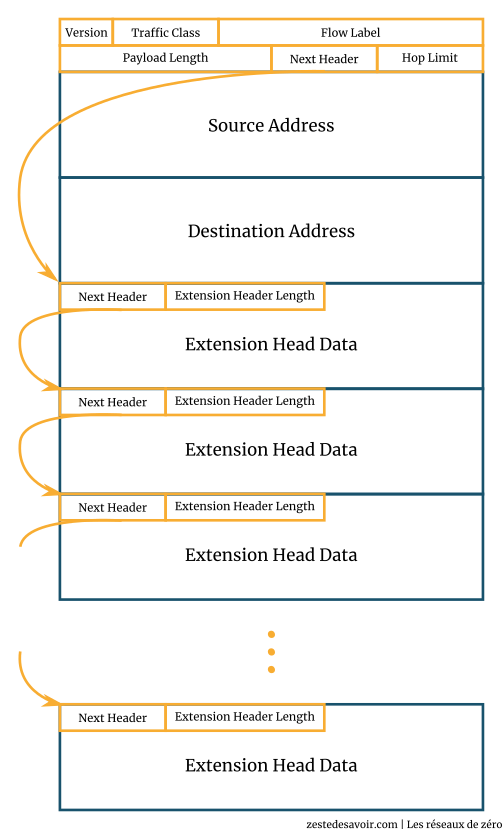
Ce système de chaine d’en-têtes permet de détacher facilement les éléments du paquet, un peu comme un mille-feuille. Pour le premier header, qui contient la plupart des informations, tout ce qui suit est considéré comme payload (données utiles). Logique, puisque tout ce qui se trouve après les adresses IP relève du « prochain en-tête ». La valeur du champ « payload length », sur 2 octets, correspond donc à la taille des données utiles, c’est-à-dire tout ce qui vient après l’adresse de destination. Et pas de bizarrerie ici, cette valeur est bien exprimée en octets.
La dernière nouveauté de l’en-tête IPv6 est le « flow label », littéralement « étiquette de flux ». Ce champ sur 20 bits peut prendre n’importe quelle valeur. Il sert à identifier, et plus précisément à étiqueter des paquets qui font partie d’un même flux, comme une communication VoIP. L’intérêt est que les routeurs qui font transiter ce flux peuvent, selon leur configuration, appliquer un traitement particulier. Par exemple, on peut imaginer que des routeurs vont faire en sorte que les paquets d’un flux audio vont arriver dans le même ordre qu’ils ont été émis.
Ce système peut fonctionner dans un réseau d’entreprise, mais nécessite d’appliquer une configuration particulière sur tous les routeurs. Il n’est pas utilisable sur Internet, car on se retrouve avec une problématique comparable au DiffServ en IPv4 : en mettant n’importe quoi comme valeur, on pourrait altérer la qualité de nos communications ou celle d’autres utilisateurs du réseau.
Pour des explications plus détaillées et plus poussées sur le flow label, vous pouvez vous référer à la RFC 6437 qui fait autorité à ce sujet.
Nous venons de voir de nombreuses propriétés des paquets IP. Il en est une qui est plus complexe et que nous avons laissée de côté pour le moment : la fragmentation.
La fragmentation
Lors de notre passage en revue de l’en-tête IPv4, nous avons éludé la deuxième ligne du tableau, qui concerne la fragmentation. Vous vous demandez certainement, mais qu’est-ce que c’est ?
Oui, qu’est-ce que c’est ?
Selon le modèle OSI, les paquets IP sont encapsulés dans un protocole de niveau 2 (liaison de données) avant d’être physiquement envoyés. En fonction du matériel utilisé (câble Ethernet, satellite, …), le volume de données envoyées en une fois peut être limité. IP doit prendre en considération cela et adapter la taille de ses paquets. C’est pourquoi il va parfois découper un paquet d’origine en plusieurs morceaux plus petits. C’est cela, la fragmentation.
Entre un hôte source et sa destination, les réseaux traversés peuvent être divers. L’émetteur ne sait pas forcément que son paquet va coincer à un moment. Ainsi, la fragmentation peut avoir lieu pendant le transit. Dans cette éventualité, l’émetteur donne un identifiant à chaque paquet. Ce numéro est codé sur deux octets : c’est le champ identification.
Dans l’en-tête, on trouve ensuite 3 bits regroupés sous le nom flags (drapeaux). Le premier d’entre eux est réservé, il ne sert à rien pour le moment et vaut toujours 0. Le deuxième est le flag DF (Don’t Fragment, ne pas fragmenter). S’il est allumé, les routeurs ne doivent pas fragmenter le paquet. S’il est trop gros et ne peut pas passer à un endroit, le routeur concerné le jette et informe l’émetteur que son paquet n’a pas pu être transmis car non fragmentable. Cette information se fait par le protocole ICMP, que nous étudierons dans la section suivante.
A contrario, le troisième drapeau est MF : More Fragment (davantage de fragment). S’il est allumé, cela signifie que le paquet d’origine est fragmenté et que celui-ci n’est pas le dernier.
Comment ça ? Qu’est-ce que ça change que ce soit le dernier ?
Avec le protocole IP, il n’y a pas de notion de connexion ou d’acquittement comme avec TCP. Les paquets peuvent arriver dans le désordre voire ne pas arriver du tout. Un flag MF allumé permet d’indiquer que, pour un paquet identifié X, il faut s’attendre à davantage de fragments. Pour ce même paquet X, le drapeau MF éteint signifie que c’est le dernier de la série et qu’il ne faut pas en attendre d’autre.
Pour déterminer si le paquet complet peut être reconstitué, IP se base sur le champ fragment offset (position du fragment), sur 13 bits. Il indique simplement la position du fragment dans le paquet d’origine, sa valeur correspond au nombre d’octets avant lui.
Faisons tout de suite un exemple pour clarifier ces dernières notions quelque peu nébuleuses. Le paquet IP d’origine a pour numéro d’identification 4284. Il contient uniquement, en plus de son en-tête, les données suivantes : ABCDEFGHIJKLMNOPQRSTUVWXYZ. Cela correspond à 26 octets. Considérons que ce paquet est fragmenté en blocs de 10 octets maximum. Après fragmentation, on aura les 3 paquets suivants :
| Identification | DF | MF | Fragment offset | Données |
|---|---|---|---|---|
| 4284 | 0 | 1 | 0 | ABCDEFGHIJ |
| 4284 | 0 | 1 | 10 | KLMNOPQRST |
| 4284 | 0 | 0 | 20 | UVWXYZ |
Seuls les champs qui nous intéressent sont représentés dans ce tableau.
Le premier fragment a le flag MF levé, car il y en a deux autres à venir derrière. L'offset est zéro, car c’est le premier fragment, il n’y en a pas à placer avant lors de la reconstitution.
Le deuxième fragment a aussi le flag MF levé, car il y a encore un fragment à venir derrière. L’offset est 10, car il y a 10 octets qui doivent être placés avant lors de la reconstitution.
Enfin, le troisième fragment a le flag MF baissé, car il n’y a pas davantage de fragment, c’est le dernier de la série. L’offset est 20, car il y a 20 octets à placer avant lors de la reconstruction. Il n’y en aura pas plus, le destinataire ne doit pas en attendre d’autre. Bien sûr, si ce 3e fragment n’est pas reçu en dernier, IP va calculer qu’il en manque et les attendre. Mais sitôt le reste reçu, la reconstitution aura lieu.
Pour ne pas vous embrouiller, on a volontairement occulté un détail. En réalité, la valeur du champ fragment offset ne s’exprime pas en octets, mais en blocs de 8 octets.
Ça, c’est pour IPv4. Vous aurez peut-être remarqué que ces champs ne se retrouvent pas dans l’en-tête IPv6. Comment gère-t-on alors la fragmentation en IPv6 ?
Eh bien, en réalité, les routeurs IPv6 ne gèrent pas la fragmentation. En IPv6, la responsabilité de la fragmentation incombe forcément à l’émetteur. En cas de paquet trop lourd pendant le routage, le routeur qui pose problème va simplement informer l’expéditeur que son paquet est trop volumineux, puis le jeter. Pour ce faire, il utilise le protocole ICMP. C’est comme quand il reçoit un paquet IPv4 avec le drapeau Don’t Fragment. Cette technique s’appelle Path Maximum Transmission Unit Discovery (PMTUD).
Quand un hôte reçoit ce message ICMP lui disant que son paquet est trop gros, il s’occupe de le découper selon la taille maximale qui lui a été transmise. L’en-tête d’origine reste inchangé, à part le champ Next header : on va lui rajouter une option. Dans le cas de la fragmentation, ce champ prend la valeur 44.
L’en-tête de l’option fragmentation est la suivante :
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Next header | réservé | Fragment offset | réservé | MF | |||||||||||||||||||||||||||
4 | 32 | Identification | |||||||||||||||||||||||||||||||
Son fonctionnement est similaire à IPv4 : l’identifiant du paquet sur 4 octets, l’offset sur 13 bits, le drapeau MF pour More Fragment. Fatalement, il ne peut pas y avoir de drapeau Don’t Fragment. Les champs réservés doivent rester à 0.
Du reste, c’est comme IPv4 pour le réassemblage. 
ICMP, l'ange gardien
Nous l’avons évoqué à plusieurs reprises, il est temps de se pencher dessus ! Ce fameux ICMP, pour Internet Control Message Protocol, est un protocole de niveau 3, c’est-à-dire de la couche réseau. Il fonctionne directement sur IP, sans protocole de transport. Son rôle est de transmettre des messages d’information et d’erreur liés directement au réseau.
Un des cas que peut prendre en charge ICMP et que nous avons vu juste avant, c’est le problème de fragmentation. Parmi les autres cas courants pris en charge, il y a la congestion, un destinataire inaccessible, un problème de routage, ou encore un TTL expiré (tombé à 0).
Pour ce faire, ICMP émet un message très simple, composé de deux numéros. Le premier est le type d’erreur ou de demande : destinataire inaccessible (3), TTL expiré (11)… Le deuxième est le code, il vient apporter une précision selon le type. Avec un message de type 3, c’est-à-dire de destination injoignable, le code 0 précise que le réseau est inaccessible, le code 4 indique que la fragmentation est nécessaire mais impossible à cause du drapeau DF, etc. La liste est longue et pas forcément utile à connaitre par cœur : certains cas sont rarissimes, d’autres sont obsolètes. Vous pouvez consulter tous les types et codes pour IPv4 et pour IPv6 sur le site de l'IANA.
Pour indiquer aux hôtes qu’il s’agit d’un message ICMP, l’en-tête IP prend dans son champ « protocole » la valeur 1.
Si on veut être exhaustif, un message ICMP comporte aussi une somme de contrôle ainsi que, de manière facultative, des données additionnelles.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Type | Code | Somme de contrôle | |||||||||||||||||||||||||||||
4 | 32 | Données (taille variable, facultatif) | |||||||||||||||||||||||||||||||
… | … | ||||||||||||||||||||||||||||||||
Les paquets ICMP pour IPv6 (on abrège en ICMPv6) sont structurés de manière identique à ceux pour IPv4.
Une utilisation très pratique et visuelle d’ICMP est l'écho. Cela consiste à envoyer un petit paquet ICMP avec quelques données à un destinataire, qui est censé nous répondre la même chose. Ça sert à savoir, par exemple, si un hôte est présent sur le réseau, ou bien à mesurer le temps de transit aller-retour entre deux hôtes. Cela vous dit quelque chose ? Eh bien, l’écho ICMP est ce qu’on appelle vulgairement un ping.
En réalité, ping est le nom donné à l’outil permettant d’exploiter ces messages. Ce petit programme est normalement présent sur tous les systèmes. Ouvrez votre console et tapez la commande suivante : ping zestedesavoir.com. Si des lignes continuent à défiler après plusieurs secondes, arrêtez le programme avec la commande clavier CTRL + C (ou ⌘ + C sous Mac).
Vous aurez un résultat semblable au suivant (si Zeste de Savoir n’est pas en rade à ce moment précis ) :
Envoi d’une requête 'ping' sur zestedesavoir.com [2001:4b98:dc0:41:216:3eff:febc:7e10] avec 32 octets de données :
Réponse de 2001:4b98:dc0:41:216:3eff:febc:7e10 : temps=11 ms
Réponse de 2001:4b98:dc0:41:216:3eff:febc:7e10 : temps=11 ms
Réponse de 2001:4b98:dc0:41:216:3eff:febc:7e10 : temps=10 ms
Réponse de 2001:4b98:dc0:41:216:3eff:febc:7e10 : temps=10 ms
Statistiques Ping pour 2001:4b98:dc0:41:216:3eff:febc:7e10:
Paquets : envoyés = 4, reçus = 4, perdus = 0 (perte 0%),
Durée approximative des boucles en millisecondes :
Minimum = 10ms, Maximum = 11ms, Moyenne = 10ms
On peut voir que 4 paquets ont été envoyés. Il s’agit uniquement de requêtes écho ICMP (echo request). Le serveur a répondu avec des réponses écho (echo reply). Avec des paquets aussi simples, on peut savoir que le serveur est en ligne et que le temps de transit aller-retour moyen est de 10 millisecondes.
Le temps est calculé par le programme ping, le protocole ICMP ne joue pas de rôle dans ces calculs. De même, la récupération de l’adresse IP n’a rien à voir avec ICMP.
Certains réseaux, notamment en entreprise, bloquent les requêtes ICMP pour des raisons de sécurité. Si vous êtes au boulot et que le ping n’a pas marché, vous pouvez réessayer depuis chez vous.
Avant de terminer ce chapitre, vous devez savoir quelque chose… Nous vous avons déjà fait utiliser ICMP dans ce cours. Eh oui ! Dans Le routage par l’exemple, nous vous avons fait faire un traceroute. Figurez-vous que ce programme ne fait qu’émettre des requêtes écho !
Mais comment cela peut permettre de déterminer les routeurs intermédiaires ? 
ICMP gère le cas où le TTL est dépassé. Pour rappel, cette valeur fait partie de l’en-tête IP et indique le nombre maximum de sauts autorisés. Quand cette valeur atteint 0, le paquet ne peut plus être routé et il est jeté par le routeur. Mais avant cela, ce dernier envoie un message ICMP à l’expéditeur, histoire qu’il soit quand même au courant.
Vous ne voyez pas où on veut en venir ? Ok, supposons qu’on fasse un ping zestedesavoir.com mais en forçant le champ TTL à 1 niveau IP. Que va-t-il se passer ? Le paquet va arriver au premier routeur. Il retire 1 au TTL, qui tombe à 0. Ne pouvant plus router ce paquet, il envoie un message d’erreur à l’expéditeur. Niveau IP, ce message a pour adresse source ce premier routeur, et pour destination, l’émetteur du ping.

Faisons la même chose en forçant le TTL à 2. On aura un message d’erreur du deuxième routeur. Adresse source : le deuxième routeur, adresse de destination : l’émetteur.
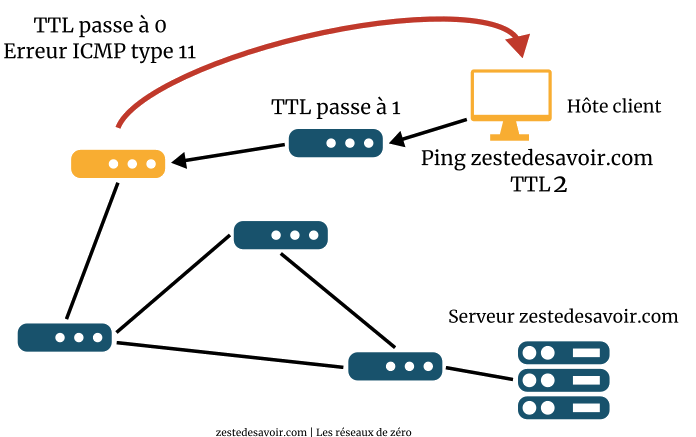
Si on continue ainsi en augmentant à chaque fois le TTL, l’émetteur du ping va recevoir un message d’erreur de chaque routeur, jusqu’à ce qu’il n’y ait plus d’erreur. Il peut donc lister tous les routeurs intermédiaires. C’est exactement ce que fait traceroute ! Ce programme fait exprès de provoquer des erreurs pour générer des messages ICMP et ainsi déterminer par où passent les paquets.
Les tables de routage peuvent varier subitement sans prévenir, surtout sur Internet. Il est possible que, pour un même traceroute, les paquets empruntent des chemins différents. Vous n’obtiendrez peut-être pas le même résultat pour un même test selon les jours voire selon les heures. De plus, certains routeurs peuvent ne pas émettre de message d’erreur ICMP : on verra alors des étoiles dans le retour du traceroute.
Nous nous arrêtons là pour ce protocole qui, avec seulement deux valeurs, rend bien des services !
IP est incontournable dans le domaine des réseaux depuis des décennies. Tout l’écosystème d’Internet tourne autour de lui. En revanche, pour assurer la communication d’un point de vue physique, on a le choix ! Ce sera le sujet de la prochaine partie.