Descendons une marche supplémentaire pour arriver sur la couche 3 : le réseau. Le sujet est tellement vaste que nous nous focaliserons essentiellement sur sa fonction principale : le routage.
- Rôle et matériel
- Les codes de la route
- Quand utilise-t-on la passerelle ?
- C'est quoi, ton type de routage ?
- Introduction aux protocoles de routage
Rôle et matériel
Le routage, qu’est-ce que c’est ?
Regardons le mot routage de plus près. Ça ne vous fait pas penser à routeur ? Ça devrait. 
Le routage consiste à faire passer des données à travers des routeurs, dans le but de les faire parvenir d’un point A à un point B.
Si vous n’avez pas compris, une analogie s’impose. Supposons que vous vous trouviez à Lyon1 et que vous vouliez aller à Paris en voiture, mais vous ne connaissez pas la route. Vous allumez donc votre GPS et lui demandez comment aller jusqu’à Paris. Votre appareil va effectuer une série de calculs pour déterminer la route à suivre. Quand vous serez invité à tourner à droite ou à gauche, vous le ferez, car vous ne voulez pas vous perdre. On peut comparer ces instructions au routage, car ils ont le même but : vous faire prendre la meilleure route pour arriver à bon port. Dans le détail, le fonctionnement est très différent, mais en surface, ça y ressemble. On aura tout le loisir de voir comment ça fonctionne après.
Le routage est donc l’action de router des paquets d’un réseau à un autre. Nous avons vu que lors de la transmission des paquets, les hôtes utilisaient un processus appellé ANDing, ou ET logique. Maintenant que nous sommes dans l’étude des couches du modèle OSI, il est temps d’être plus précis dans les termes. C’est le protocole IP (Internet Protocol), que nous allons étudier, qui effectue cette vérification. Souvenez-vous que chaque couche ajoute des informations en en-tête dans ce qui finit par devenir les paquets, en descendant de la couche applicative à la couche réseau. Au niveau de la couche réseau, IP doit vérifier s’il s’agit d’une communication intra-réseau ou d’une communication inter-réseau. Quelque part, c’est comme lorsque vous passez un appel. Il y a des procédures techniques au niveau de votre opérateur qui vérifient s’il s’agit d’un appel local ou international.  Par analogie, c’est ce que fait le protocole IP au niveau de la couche 3. Quand il s’agit d’une transmission en dehors du réseau, les paquets sont transmis au routeur qui se chargera du reste. Cette transmission de paquets d’un réseau à un autre est la définition de base du « routage ».
Par analogie, c’est ce que fait le protocole IP au niveau de la couche 3. Quand il s’agit d’une transmission en dehors du réseau, les paquets sont transmis au routeur qui se chargera du reste. Cette transmission de paquets d’un réseau à un autre est la définition de base du « routage ».
Rôle de la couche
La couche réseau ou couche 3 du modèle OSI, qui correspond à la couche Internet du modèle TCP-IP, est responsable du routage. C’est même la fonction principale de cette couche. Une fois que la couche transport a assuré son rôle, les données sont envoyées à la couche réseau. Cette dernière se chargera d’ajouter toutes les informations en rapport avec le routage, dont notamment l’adresse IP du destinataire. C’est la seule couche du modèle OSI qui utilise la connexion logique entre hôtes. En fait, bien que cette couche ait pour rôle de déterminer le chemin physique à emprunter en se basant sur l’adresse IP du destinataire, les conditions du réseau et plusieurs autres facteurs, elle ne peut pas établir une connexion physique. Son rôle se limite à la connexion logique. Une fois qu’elle a ajouté à l’en-tête du paquet des informations qui lui sont spécifiques, ce dernier suit son cours et descend donc dans la couche 2, celle qui se chargera de liaison des données.
Et le matos ?
Le matériel principal de la couche 3 est le routeur. Nous avons déjà vu ce qu’était un routeur. Il s’agit d’un matériel dont la fonction principale est d’assurer l’acheminement des paquets vers leurs destinataires en effectuant des décisions logiques déterminées par le protocole de routage utilisé.
D’autres matériels peuvent être utilisés, tels que les commutateurs avancés (advanced switches), aussi appelés par l’oxymore "switch de niveau 3", et les passerelles applicatives dont la fonction est de relier deux réseaux différents. Le commutateur avancé est un matériel qui fonctionne de la couche physique à la couche réseau voire transport du modèle OSI. La passerelle applicative, quant à elle, couvre toutes les 7 couches du modèle OSI, comme son nom l’indique. Elle va donc de la plus basse (couche 1, physique) à la couche applicative d’où elle tire son charmant petit nom.
Le routeur, par contre, est un matériel qui fonctionne entre les couches 1 et 3.
Voici un schéma illustrant cela :

- Pour ceux qui ne connaissent pas bien la France, Paris est sa capitale et Lyon en est une des plus grandes villes.↩
Les codes de la route
La table de routage
Le routage est la fonction principale d’un routeur. Imaginez un réseau de milliers d’hôtes segmentés en une dizaine de sous-réseaux. Il faudrait beaucoup de routeurs pour assurer la communication entre ces 10 sous-réseaux. Les routeurs doivent s’assurer que chaque hôte de n’importe quel sous-réseau communique avec les hôtes de tous les sous-réseaux. Pour implémenter un routage effectif, il faut que les routeurs sachent prendre des décisions, pour savoir par quel routeur passer pour arriver à tel sous-réseau. Les routeurs, pour ce faire, utilisent ce qu’on appelle une table de routage. Quand un hôte X du réseau A veut communiquer avec un hôte Y du réseau B, les paquets seront envoyés au routeur AB qui relie le réseau A et le réseau B. Dans l’en-tête du paquet (nous allons le voir bientôt) se trouve l’adresse IP de l’émetteur et celle du destinataire. Le routeur devra donc vérifier dans sa table de routage comment faire pour arriver au sous-réseau dans lequel se trouve l’adresse IP du destinataire. Cette table de routage contient les network ID de tous les routeurs qui sont directement connectés au routeur AB. La table de routage contiendra également tous les chemins possibles pour atteindre un sous-réseau donné, ainsi que le coût que cela implique.
Ça coute cher de router un paquet ? 
Oui, router un paquet implique un coût. Mais ne vous inquiétez pas, il ne s’agit pas d’argent.  En termes de routage, plusieurs facteurs déterminent le coût d’un chemin. Dans la plupart des cas, le coût est déterminé par le nombre de sauts.
En termes de routage, plusieurs facteurs déterminent le coût d’un chemin. Dans la plupart des cas, le coût est déterminé par le nombre de sauts.
Mais non, les routeurs ne peuvent pas sauter ! Si ? 
Avec un trampoline, pourquoi pas…  Un saut, dans les termes du routage, est défini par le passage d’un paquet par un routeur. Chaque fois qu’un paquet passe par un routeur, on dit qu’il effectue un saut (hop en anglais).
Un saut, dans les termes du routage, est défini par le passage d’un paquet par un routeur. Chaque fois qu’un paquet passe par un routeur, on dit qu’il effectue un saut (hop en anglais).
Ainsi, dans notre exemple, le routeur AB va considérer tous les chemins qu’il a dans sa table de routage, voir quel est le chemin le moins couteux en termes de sauts et va emprunter ce dernier pour router le paquet transmis par X.
N’y allons pas par quatre chemins
Nous avons plusieurs fois employé le terme de chemin. C’est quoi, un chemin ? En réseau, c’est la même chose qu’un chemin dans le contexte naturel. Pour aller à l’école, au travail ou autre, il y a souvent plusieurs itinéraires possibles. Comme on dit : « tous les chemins mènent à Rome ». Cela veut dire qu’il y a plusieurs moyens pour arriver quelque part. En réseau, pour que vous visualisiez ce qu’est un chemin, nous vous avons fait un joli schéma illustratif.
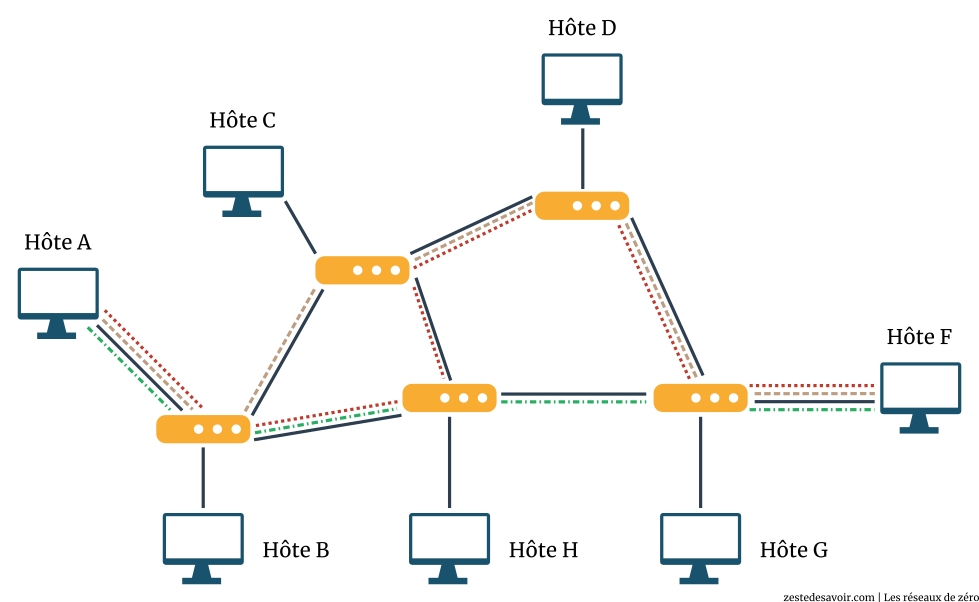
- Les traits en noir représentent les câbles qui relient les routeurs entre eux et les hôtes aux routeurs.
- Les autres traits représentent chaque chemin possible qu’un paquet allant de A à F peut suivre.
Pouvez-vous remarquer la corrélation qu’il y a entre un chemin et le nombre de saut ? En effet, plus le chemin est long, plus grand est le nombre de sauts, ce qui est logique.
- Vous pouvez voir que le chemin en vert ne coute que 3 sauts. Il faut « traverser » 3 routeurs pour arriver à F. C’est le chemin le moins couteux dans ce réseau.
- Le chemin en marron coute 4 sauts, on passe par 4 routeurs avant d’atteindre F. C’est le deuxième chemin le moins couteux.
- Par contre, le chemin en rouge est le chemin le plus couteux. Il faut passer par 5 routeurs avant d’arriver à F.
Une table de routage contiendra toutes ces informations, et c’est par rapport à cette table qu’un routeur prendra la décision effective pour transmettre un paquet. L’intelligence qui est derrière les décisions des routeurs est fournie par les protocoles de routage Nous allons aborder cette notion dans ce chapitre.
Dans cette section, nous allons jeter un coup d’œil sur la commande « route » que nous pouvons retrouver dans les systèmes Windows et Linux.
Ça sert à quoi, cette commande ?
La commande « route » sert à manipuler les tables de routage. Nous avons beaucoup parlé de tables de routage sans savoir à quoi ça ressemblait. Maintenant, c’est le moment de vérité !
Notez que cette commande nous permet en fait de faire du routage statique, car grâce à elle nous pouvons modifier les entrées de la table de routage, en ajoutant des routes, en en supprimant, etc…
À l’aide, j’ai perdu ma route !
Pour avoir plus d’informations sur la commande « route » sur Windows, ouvrez votre invite de commande et tapez route /?.
Dans cette syntaxe, on dit que route est la commande de base et /? le switch (rien à voir avec le matériel réseau). D’ailleurs, ce switch fonctionne avec toutes les autres commandes. Il sert à afficher les informations sur l’utilisation de la commande qui le précède.
Pour les Linuxiens, ouvrez votre terminal et tapez route --help.
Vous obtiendrez quelque chose similaire à la capture ci-dessous :
Vous pouvez vous servir de ces informations pour apprendre à utiliser les différentes commandes. Pour ce tuto, nous allons utiliser les commandes nous permettant d’ajouter, de supprimer, de modifier une route et d’afficher le contenu de la table de routage.
Afficher le contenu de la table
Vous vouliez voir à quoi ressemble une table de routage ? Sous Windows, tapez route print dans votre invite de commande. Sous Linux, ouvrez votre terminal et tapez route –n.
Vous obtiendrez naturellement une table différente de la nôtre. Voici une capture de ce que nous obtenons sous Windows.
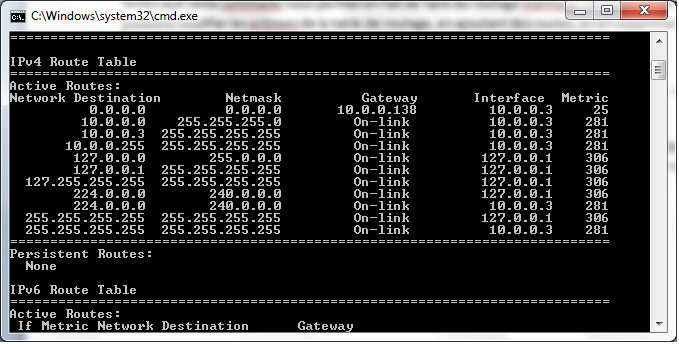
Examinons chacune des colonnes de cette fameuse table :
- Network Destination : cette colonne correspond au réseau ou à l’adresse de destination.
- Netmask : diminutif de « Network Mask », cette colonne correspond au masque du réseau. C’est le masque utilisé pour déterminer le network ID de l’adresse IP du destinataire.
- Gateway : aussi appelé « next hop » (prochain saut), cette colonne est l’adresse IP de la passerelle conduisant au réseau spécifié dans la colonne Network Destination.
- Interface : comme vous le savez, un routeur a plusieurs interfaces. Cette colonne spécifie quelle interface est utilisée pour transmettre les paquets dans le réseau spécifié par la première colonne.
- Metric : voilà notre fameuse métrique ! Il s’agit d’une valeur numérique, et comme vous pouvez le constater, les différentes entrées de la table ont des différentes valeurs de métriques. Quand plusieurs chemins conduisent au même réseau de destination, le routeur se base sur le chemin qui a la plus petite valeur dans la colonne métrique de sa table.
Les différents types de routes
Nous pouvons avoir plusieurs types de route dans une table de routage et nous allons essayer de voir en quoi elles consistent.
Network ID d’un réseau distant
Il s’agit ici de l’ID d’un réseau qui n’est pas directement lié au routeur, d’où son appellation réseau distant. Il peut alors être atteint via les autres routeurs voisins. Dans ce genre d’entrée, la colonne passerelle de la table de routage correspondra au routeur local par lequel il faudra passer (notre prochain saut).
Network ID d’un réseau voisin
Il s’agit de l’ID d’un réseau qui est directement lié au routeur local. La colonne Gateway de la table correspondra alors à l’adresse IP de l’interface du routeur qui est liée à ce réseau avoisinant. Dans l’illustration ci-dessous, B est une route directe pour A. C et D sont des routes distantes que A peut atteindre via B.

Route-hôte (host route)
Il s’agit d’une route vers une adresse IP précise, ce qui permet d’effectuer un genre de routage plus direct. Pour ce type de route, la colonne Network Destination est l’adresse IP de l’hôte destinataire, et la colonne Netmask aura pour valeur numérique 255.255.255.255.
255.255.255.255 ? Mais c’est un broadcast, non ?
Quelle bonne mémoire. Si c’était une adresse IP, ce serait ça, mais là, on parle d’un masque. Dans celui-ci, tous les bits sont allumés, ce qui signifie que le réseau de destination ne comporte que l’adresse indiquée. En effet, tous les bits doivent être rigoureusement identiques à l’adresse fournie pour correspondre au cas, ce qui signifie donc que seul l’hôte ayant cette adresse est concerné par l’entrée de la table de routage.
Route persistante
Toutes les routes que vous ajoutez manuellement dans votre système sont supprimées lorsque vous redémarrez votre ordinateur. Si vous voulez qu’une route « persiste » il faudrait donc ajouter une route… persistante.  Pour ajouter une route persistante dans votre table de routage sous Windows, il suffit d’ajouter le switch
Pour ajouter une route persistante dans votre table de routage sous Windows, il suffit d’ajouter le switch -p à la fin d’un ajout statique. En voici un exemple :
route add 192.161.88.0 mask 255.255.255.0 192.160.36.1 metric 20 if 1 -p
Sous Linux, cela dépend des distributions. Une méthode pour les systèmes Debian consiste à ajouter la commande précédée du mot-clé "up" à la fin du fichier /etc/network/interfaces. Exemple :
up route add -net 172.17.250.0/24 gw 172.17.10.141 dev eth0
Route par défaut
En toute logique, c’est la route qui est utilisée lorsque la table de routage ne comprend aucune route valable vers le réseau de destination. Dans ce type de route, les colonnes Network Destination et Netmask auront une valeur numérique de 0.0.0.0. En théorie, n’importe quel réseau destination devrait fonctionner avec un masque 0.0.0.0. En effet, un ANDind avec un tel masque nous donne toujours le même résultat : n’importe quel bit peut prendre n’importe quelle valeur.
Quand utilise-t-on la passerelle ?
Nous allons à présent étudier l’algorithme de sélection de route. Nous avons déjà vu ce qu’était le routage et les chemins dans une table de routage. Il nous faut maintenant étudier comment le protocole IP sélectionne une route dans une table lors de la transmission des données entre un hôte A et un hôte B. Pour ce faire, nous allons reprendre notre schéma illustrant les différents chemins. Ce sera notre étude de cas.
C’est quoi un algorithme ?
Pour faire simple, un algorithme est une suite d’instructions précises et ordonnées conduisant à l’accomplissement d’une tâche précise. Par exemple, pour faire une omelette, il vous faut casser des œufs, les battre, mettre du sel, etc. Il y a une suite d’étapes distinctes qui doivent être respectées dans un ordre précis.
Ainsi, par "algorithme de sélection de route", nous voulons simplement désigner la suite d’étapes que le protocole IP utilise pour choisir une route.
Dans la partie I du cours, plus précisément dans le chapitre « La passerelle : les bases du routage », nous avons métaphoriquement expliqué le processus de routage d’un paquet. Maintenant que vous êtes plus avancé, nous pouvons détailler ce qui se passe dans les coulisses du protocole IP.
Pour commencer, regardons à nouveau les étapes que nous avions énoncées dans ce chapitre. En résumé, nous avions dit que si un hôte A voulait communiquer avec un hôte B, grâce au ANDing, il déterminerait si son destinataire (l’hôte B en l’occurrence) était dans le même réseau que lui. Si oui, il lui envoyait les données directement, sinon il envoyait les données à une passerelle qui se chargerait de les router.
Schématiquement, ça donnait ceci :
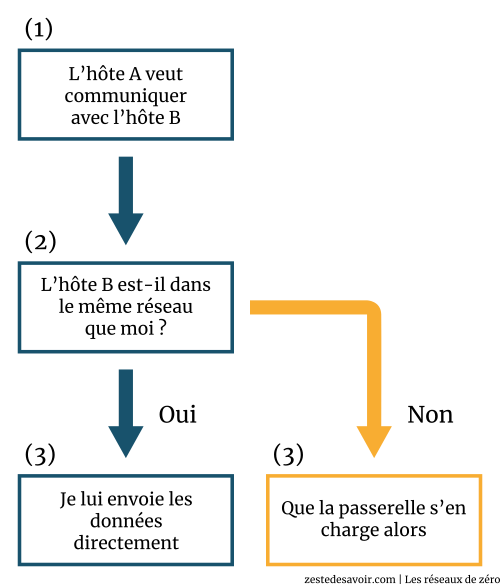
Maintenant que vous êtes des grands, nous allons voir plusieurs autres étapes distinctes comme illustré dans le schéma ci-dessous.
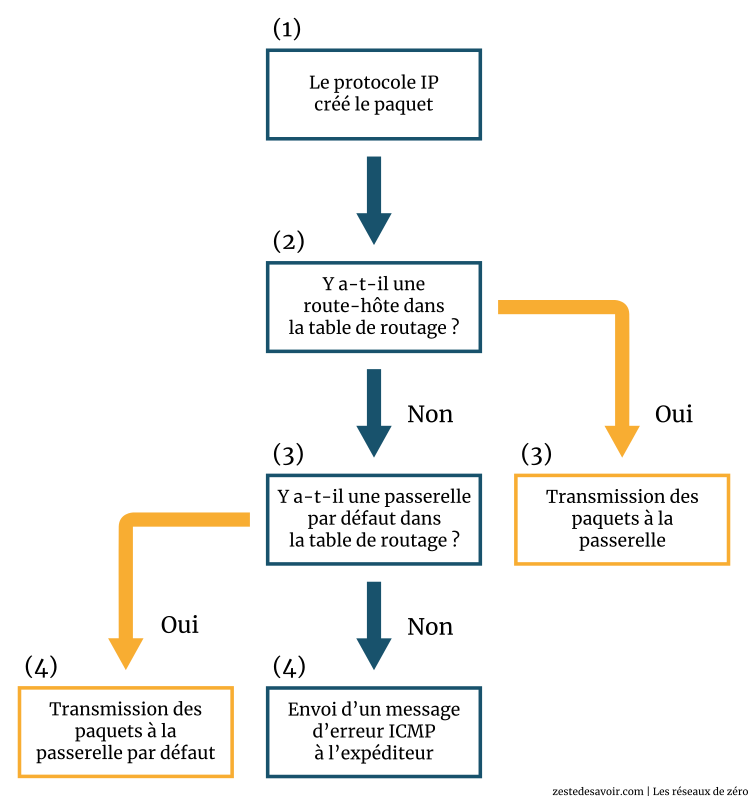
La procédure de routage
Pour sélectionner une route, le protocole IP suit les étapes suivantes :
- Le protocole IP fouille les entrées de la table de routage afin de déterminer la route-hôte qui correspond à l’IP du destinataire. L’adresse IP se trouvera dans l’en-tête IP du paquet. Souvenez-vous que la route-hôte a l’adresse IP de destination dans la colonne Adresse Réseau et la valeur 255.255.255.255 dans la colonne du masque.
- Si le protocole IP ne trouve aucune route-hôte, il va scanner les colonnes « Adresse Réseau » et « Masque » pour chercher la route qui peut mener au réseau du destinataire. Mais que se passe-t-il s’il y a plusieurs chemins possibles pour arriver au destinataire, comme c’est le cas dans le schéma illustratif des chemins ? Est-ce qu’une route est choisie au hasard ? Non, c’est la route ayant le plus grand nombre de bit masqués qui sera choisie, car on cherche le cas le plus précis. Et s’il y a deux routes ayant le même nombre de bit masqués ? La décision sera alors déterminée par la route ayant la plus petite métrique, ce qui est dépend intimement du protocole de routage utilisé.
- Si, dans la table de routage, il n’y a aucune route conduisant au destinataire, la dernière option sera alors de localiser la passerelle par défaut. Ce cas peut être intégré au point précédent, puisqu’il correspond techniquement à prendre le cas le moins précis (destination : 0.0.0.0/0), celui qui autorise tous les bits à ne pas correspondre au network ID de destination.
- Si par contre, il n’y a pas de passerelle par défaut, le paquet à ce stade est « délaissé » et une erreur ICMP est envoyée à l’émetteur. Il s’agira d’une erreur « destination inaccessible ».
Si le système a pu localiser une route conduisant au sous-réseau du destinataire, il va alors falloir déterminer l’adresse physique (MAC) du routeur qui conduira le paquet au bon endroit. Souvenez-vous que la transmission des données dans un réseau local se fait en utilisant les adresses MAC. Si le protocole IP trouve le routeur qu’il faut, cela veut dire qu’il est dans le même sous-réseau que l’émetteur, donc il faudra trouver son adresse physique ! C’est ici qu’intervient le module ARP (Address Resolution Protocol) qui est un protocole à cheval sur les couches 2 et 3.
ARP est spécifique à IPv4. En IPv6, on utilise Neighbor Discovery Protocol (NDP).
Une table ARP contient une correspondance entre les IP et leurs adresses physiques respectives. Plus précisément, elle définit à quelle adresse physique la couche 2 doit s’adresser pour joindre une adresse IP donnée.
Voici à quoi peut ressembler une table ARP sous Windows. Vous pouvez essayer vous-mêmes avec la commande arp -a (valable pour Windows et Linux).
Interface : 192.168.1.14 --- 0x13
Adresse Internet Adresse physique Type
192.168.1.1 c0-d3-8e-93-10-5c dynamique
192.168.1.255 ff-ff-ff-ff-ff-ff statique
224.0.0.2 01-00-5e-00-00-02 statique
224.0.0.22 01-00-5e-00-00-16 statique
224.0.0.251 01-00-5e-00-00-fb statique
224.0.0.252 01-00-5e-00-00-fc statique
239.255.255.250 01-00-5e-7f-ff-fa statique
255.255.255.255 ff-ff-ff-ff-ff-ff statique
Pour IPv6, on parle plutôt de table de voisinage. On peut la visualiser avec la commande netsh int ipv6 show neigh sous Windows ou ip -6 neigh show sous Linux.
Interface 19 : Ethernet
Adresse Internet Adresse physique Type
-------------------------------------------- ----------------- -----------
fe80::b2b2:8fff:fe73:c05a c0-d3-8e-93-10-5c Joignable (Routeur)
ff02::1 33-33-00-00-00-01 Permanent
ff02::2 33-33-00-00-00-02 Permanent
ff02::16 33-33-00-00-00-16 Permanent
ff02::fb 33-33-00-00-00-fb Permanent
ff02::1:2 33-33-00-01-00-02 Permanent
ff02::1:3 33-33-00-01-00-03 Permanent
ff02::1:ff43:b83e 33-33-ff-43-b8-3e Permanent
ff02::1:ff73:c05a 33-33-ff-73-c0-5a Permanent
ff02::1:ffde:aa0d 33-33-ff-de-aa-0d Permanent
ff05::c 33-33-00-00-00-0c Permanent
Vous remarquerez des adresses un peu étranges, qui commencent par exemple par 224 ou ff02. Elles sont utilisées pour des types de communication particuliers que nous allons voir maintenant.
C'est quoi, ton type de routage ?
Il existe 4 types majeurs de routage ou méthodologies de routage : unicast, multicast, broadcast et anycast. Vous avez possiblement déjà entendu ces termes. Nous allons aborder chacun d’eux.
Unicast : un seul destinataire
L’unicast consiste à transmettre les paquets à un seul destinataire (uni comme unique, un). Un exemple de routage unicast est lorsque vous visitez une page web toute bête, du genre perdu.com. Pas de grosse infrastructure, on est à peu près certain que la requête ne peut aller que d’un client à un serveur précis.
Multicast : restriction à un groupe
Le multicast, c’est un peu comme effectuer plusieurs unicast à un groupe déterminé, mais en n’utilisant qu’une seule adresse. Sur un réseau, différents hôtes peuvent s’abonner ou se retirer d’un groupe pour recevoir des données sans que l’émetteur n’ait quoi que ce soit à changer. Cela a diverses applications, comme la transmission d’informations de routage ou encore la diffusion de flux multimédia. Les récepteurs sont alors sous une même adresse IP multicast. L’adresse logique utilisée dépend intimement du protocole utilisé. Dans le cas de protocoles de routage, RIPv2 utilisera l’adresse 224.0.0.9 pour multicaster des paquets, tandis qu’OSPF utilisera l’adresse 224.0.0.5 pour envoyer de paquets de signalisation « Hello » aux routeurs du réseau physique.
En IPv4, les adresses multicast sont forcément de classe D. En IPv6, elles commencent par le préfixe ff00::/8.
Voici une liste de quelques adresses multicast et leur utilisation.
Le broadcast
Le broadcast, c’est simple : on envoie à tout le monde. Bon, en vrai, il y a quelques subtilités.
On peut envoyer des paquets en broadcast sur son réseau logique. Nous avons vu lors des chapitres sur l’adressage que, conventionnellement, la dernière adresse IP d’un sous-réseau était son adresse de broadcast. On peut donc l’utiliser pour communiquer avec tous les hôtes de son propre sous-réseau.
Mais il y a une autre possibilité. On peut utiliser l’adresse 255.255.255.255. Avec celle-là, vous pouvez contacter tout le monde. Enfin presque. Si ça se retrouvait sur Internet, ce serait un sacré bordel. Les routeurs ne laissent pas passer ces broadcasts, mais cette adresse permet d’arroser tous les hôtes de votre réseau physique. Vous vous souvenez de la différence entre un réseau logique et physique ? Dans le cas présent, vous pouvez contacter un hôte dans un réseau logique différent du vôtre s’il est dans le même réseau physique.
Et en IPv6 ?
Au risque de vous surprendre, ce n’est pas possible. Le broadcast n’existe pas en IPv6. 
Anycast : à n’importe qui ?
Nous finissons par le plus compliqué. Le préfixe « any », dans anycast, est un mot anglais qui signifie « n’importe ». On pourrait croire, à première vue, que ce type de routage consiste à router des paquets à n’importe qui, ce qui n’aurait aucun sens. Vous ne pianoteriez pas un numéro au pif sur votre téléphone, sans savoir à qui il est ni même si le numéro est attribué (ou alors vous être sacrément tordu-e ).
Le principe de l’anycast, c’est de router des paquets au destinataire le plus proche lorsqu’il existe plusieurs chemins conduisant au même réseau. Si trois routeurs B, C, D conduisent tous les trois au routeur E, un routeur A enverra alors les paquets en anycast. Ainsi le plus proche de ces 3 routeurs recevra les paquets et les acheminera au destinataire final. Le routeur le « plus proche » est déterminé par le protocole qui est utilisé. Dans le cas de RIP qui mesure la distance par le nombre de sauts, le routeur le plus proche serait celui qui nécessite le plus petit nombre de saut.
Quand on effectue ce genre de routage, on dit que l’on « anycaste » (du verbe « anycaster » ) les paquets. C’est pas dit que le dictionnaire soit très d’accord, donc ça reste entre nous !
Un exemple de l’application de ce plan de routage
Vous ne voyez pas encore les avantages de l’anycast ? Essayons d’illustrer cela.
Nous allons décrire une architecture possible de Zeste de Savoir. Ce n’est pas celle actuellement en place, mais elle permet de montrer les avantages de l’anycast.
Zeste de Savoir, à en croire les stats, compte 10.310 membres au moment de la rédaction de ces lignes. Heureusement que ces derniers ne se connectent pas tous au même moment, cela augmenterait considérablement le nombre de requêtes que le serveur principal doit recevoir. Nous allons supposer que l’architecture de ZdS est comme suit :
-
2 serveurs de contenus : nous allons considérer que le site a des milliers de contenus (cours, articles, billets, …) disponibles. ZdS décide donc d’avoir deux serveurs : un serveur principal « normal » qui héberge les cours et autres, et un autre serveur « miroir » qui est une copie conforme de tous les contenus hébergés par le premier. Appelons le serveur principal « contenus_serveur » et le miroir « contenus_bis ».
-
1 serveur de membres : ce dernier appelé « membres_serveur » héberge tous les membres du site et leurs informations associées (pseudo, mot de passe, signature, avatar, etc.), sous forme d’une base de données.
-
2 serveurs d’images : rien qu’à voir le nombre d’images par tutoriel, sur le forum, etc., on va supposer que ZdS a déployé deux serveurs d’images, le deuxième servant de miroir. Nous allons les appeler « images_serveur » et « images_bis ».
-
2 serveurs web : ces deux serveurs hébergent toutes les pages web du site. C’est donc le serveur qui se charge de vous afficher les pages selon vos requêtes HTTP envoyées via votre navigateur. Appelons les « zds» et « zds_bis ».
-
1 serveur front-end : ce serveur n’héberge pas les données du site, il sert de gestionnaire de requête. C’est ce dernier qui va intercepter vos requêtes et les transmettre aux autres serveurs.
Voici un schéma de l’architecture décrite.
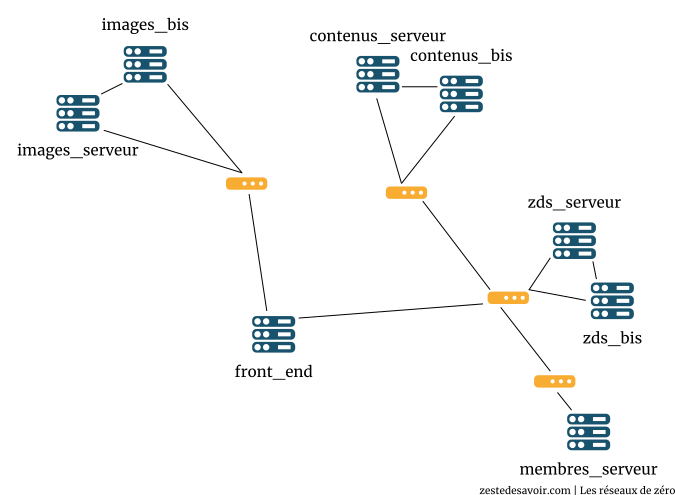
L’anycast a de l’intérêt dans des grands réseaux avec un certain nombre de routeurs. On va considérer que les serveurs de ZdS sont dispatchés dans un plus grand ensemble et que les liens ne sont pas directs.
Que se passerait-t-il si tous les membres essayaient de se connecter au même moment ? Cela ferait plus de 10.000 requêtes à gérer simultanément par ressource demandée ! Les serveurs sont peut-être assez robustes pour faire cela, néanmoins, on peut minimiser la charge en décentralisant les ressources. Par exemple, on a 2 serveurs pour les images. On peut les grouper sous une adresse anycast logique. En d’autres termes, de « l’extérieur » on ne verra qu’un seul serveur d’images (une seule adresse logique, adresse d’anycast). Cependant, sous cette adresse, il y aura 2 serveurs distincts auxquels on peut anycaster les paquets.
Ainsi, lorsque ZdS aura à gérer 10.000 requêtes vers des images de façon simultanée, le serveur front-end diffusera les requêtes en les anycastant au serveur d’images le plus proche en termes de « distance ». La distance peut être déterminée par le nombre de sauts, si c’est le protocole RIP qui est utilisé.
Cette nouvelle architecture va optimiser la gestion des requêtes et la performance des serveurs.
Un protocole pratique comme EIGRP fait encore mieux : il peut considérer également la saturation d’un lien pour déterminer à quel serveur envoyer les requêtes. Ainsi, les deux serveurs d’images pourront se partager les tâches, au lieu de laisser un seul serveur faire tout le boulot.
L’implémentation d’un plan de diffusion anycast dans une partie du réseau est assez complexe et prend plusieurs autres paramètres en considération. Si le plan de routage est mal fait, il y aura logiquement des sérieux problèmes de communication. Nous n’allons pas rentrer dans les détails techniques des contraintes de l’anycast, ça fait déjà beaucoup à intégrer pour le moment !
Nous avons commencé à évoquer des protocoles de routage. Il est maintenant temps d’introduire proprement cette notion.
Introduction aux protocoles de routage
Commençons par préciser qu’il y a deux manières de faire du routage : le routage statique et le routage dynamique.
Routage statique
Les routeurs dans un réseau doivent communiquer normalement et s’échanger des informations telles que le contenu de la table de routage, que nous avons déjà évoquée. Le processus d’échange d’informations entre routeurs dépend du genre de routage utilisé. Dans un routage statique, c’est vous, l’administrateur réseau, qui devez construire et mettre à jour manuellement vos tables de routage. Donc dans un routage statique, le contenu des tables de routage est également statique. Ce genre de routage n’est pas vraiment pratique pour des raisons évidentes :
- Les routeurs ne découvriront pas automatiquement les Network ID des autres réseaux, ce sera à vous de les leur apprendre par une configuration manuelle ;
- Les routeurs ne pourront pas communiquer entre eux pour s’échanger des informations, ce sera à vous de modifier les changements des données de votre réseau dans chaque routeur, manuellement ;
- Les routeurs ne seront pas intelligents et pourront garder des données erronées dans leur table. Étant donné qu’ils ne communiquent pas entre eux dans un routage statique, cela veut dire que si un chemin vers un réseau n’est plus praticable, un routeur continuera à considérer ce chemin comme étant valable, du moins, tant que vous ne l’aurez pas changé.
En bref, le routage statique, cela signifie que le routage est défini manuellement par l’administrateur.
Routage dynamique
Le routage dynamique est exactement le contraire du routage statique. Tout se fait automatiquement grâce à un protocole de routage. Cette section vous servira d’introduction aux protocoles de routage. Le chapitre qui suit sera dédié à ces derniers, il est donc important de poser une bonne base de connaissance avant de s’y attaquer. Introduisons d’abord ce concept.
Il est possible d’avoir un réseau composé de plusieurs dizaines de routeurs. Ces derniers doivent constamment communiquer en s’échangeant des informations sur les routes. Comme vous le savez certainement, en réseau ce sont des protocoles qui permettent la communication entre les hôtes. Le rôle d’un protocole de routage consiste donc à définir les règles et principes de communication entre routeurs, pour ce qui concerne le seul routage.
En résumé, un protocole de routage, c’est l’intelligence qui régit la manière dont les routeurs communiquent entre eux pour nous offrir le meilleur service de routage possible, c’est-à-dire le moins couteux, le plus rapide, le plus pratique.
Les différents protocoles de routage
Il existe de nombreux protocoles de routage. Un routeur peut supporter plusieurs protocoles en même temps. Pourquoi en avoir plusieurs, s’ils servent tous à faire la même chose ? La réponse se trouve dans la méthodologie. Ces protocoles font certes la même chose, mais certains sont plus pratiques que d’autres, d’autres ont des contraintes plus couteuses par exemple. Citons pêle-mêle les protocoles les plus célèbres : RIPv1 et RIPv2, OSPF, EIGRP, IGRP, BGP, IS-IS.
Ces protocoles peuvent se classer dans des « familles » . Il en existe deux :
- IGP (Interior Gateway Protocol, protocole de routage interne) : c’est la famille des protocoles qui peuvent échanger des informations de routage avec des systèmes autonomes (AS, Autonomous Systems). Il s’agit, pour faire simple, d’un ensemble de réseaux IP contrôlés par une organisation ou une entreprise.
- EGP (Exterior Gateway Protocol, protocole de routage externe) : c’est la famille des protocoles qui déterminent la disponibilité d’un réseau entre deux systèmes autonomes. Il s’agit des protocoles permettant le routage entre deux systèmes autonomes différents. Les fournisseurs d’accès à Internet, par exemple, utilisent un protocole de cette famille pour effectuer un routage externe. C’est la famille du principal protocole de routage utilisé par Internet, BGP (Border Gateway Protocol).
Voici un schéma illustrant quel type de protocoles est utilisé à quel moment. Nous avons schématisé un réseau constitué de deux systèmes autonomes (Myrtille et Citron).
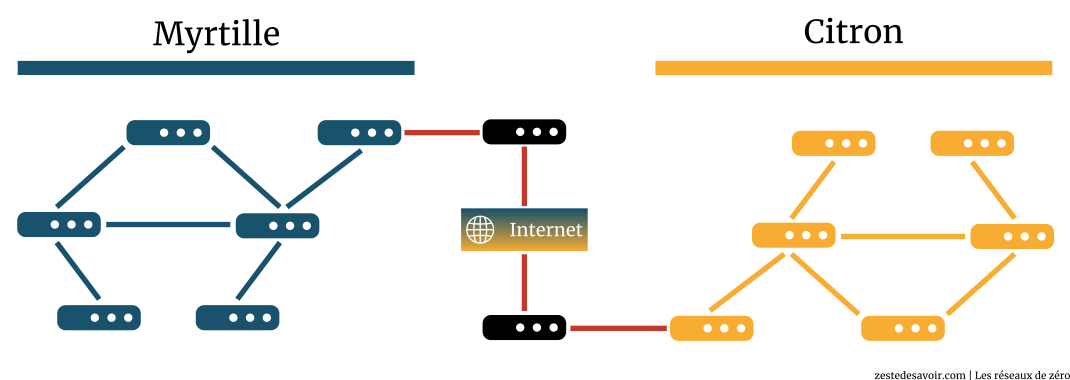
Les traits centraux en rouge représentent les protocoles de la famille EGP, ceux qui se chargent du routage sur Internet. En bleu et jaune, sur les côtés, vous avez des protocoles de type IGP, pour le routage interne.
Vous arrivez à suivre ? Dans un futur chapitre, nous allons étudier quelques protocoles de routage. 
Que d’aventures ! La couche 3 est un domaine d’étude conséquent, et dans ce tutoriel, nous n’en voyons qu’une partie. Dans ce chapitre, nous avons posé les bases du routage, ce processus d’acheminement des données au travers des réseaux. Nous avons vu ce qu’était une route, dans quels cas nous avons besoin d’une passerelle, les possibilités d’adressage en fonction de qui on souhaite contacter, et enfin, nous avons introduit la notion de protocole de routage.
Le chapitre suivant est beaucoup plus léger et amusant. Nous allons illustrer le routage au travers d’exemples sans rentrer dans la technique. Profitez-en bien !