Nous venons de passer deux chapitres à étudier la couche transport dans le principe. Pour mettre en œuvre tous les services qu’elle offre, elle exploite deux protocoles incontournables qu’il est essentiel de connaitre.
Dans ce chapitre, nous allons nous focaliser sur les deux protocoles principaux de cette couche : TCP (Transmission Control Protocol) et UDP (User Datagram Protocol). Nous commencerons par étudier UDP, qui est assez simple, ensuite nous nous focaliserons sur TCP. Finalement, nous comparerons les deux protocoles afin de déterminer dans quels cas il faut privilégier l’un au détriment de l’autre. TCP étant un protocole richissime, nous allons voir seulement quelques-unes de ses fonctionnalités dans ce chapitre.
UDP, un protocole irresponsable
UDP est l’un des protocoles les plus utilisés au niveau de la couche transport, juste après TCP. Les deux sont des protocoles dont la vocation est de transporter les données d’une application à une autre comme nous l’avons vu. Dans cette sous-partie, nous allons nous concentrer sur UDP.
UDP par l’analogie
Pour bien aborder une notion importante, une analogie (vous commencez à être habitués  ).
).
Supposons que vous allez participer à une grande fête chez un ami, Pierre. Votre ami vous a donné la permission d’inviter vos amis, même s’il ne les connait pas. Vos amis, ne connaissant pas Pierre, ne savent pas comment arriver chez lui. Vous leur avez demandé de vous rejoindre chez vous à 17h, afin de vous rendre à la fête ensemble. Le jour J arrive et tous vos amis sont chez vous. Vous décidez alors d’emprunter des taxis pour aller chez Pierre. En sortant de chez vous, il y a une file de plusieurs taxis disponibles. Vous allez donc vous séparer en plusieurs groupes. Chaque groupe prendra son propre taxi. Le but est le même pour tous : arriver chez Pierre. Mais il est fort probable que d’autres arrivent plus tôt que les autres (à cause de feux de circulation, …). Il est aussi probable que les taxis n’empruntent pas la même route pour arriver à la destination finale. Pour les malchanceux, il se peut même qu’ils aient un accident en route, les empêchant ainsi d’arriver à destination. Ainsi, les taxis ne peuvent pas garantir que tout le monde arrivera à temps, dans les délais voulus, et surtout que tous vont emprunter le même chemin ou arriver au même moment.
Diverses raisons peuvent faire que plusieurs taxis allant d’un point A à un point B ne se suivent pas les uns les autres. Un ralentissement soudain, un accrochage, un contrôle de police peuvent altérer la fluidité de la circulation et faire changer l’itinéraire d’un ou plusieurs véhicules pour arriver plus rapidement à destination.
Un autre exemple ?
On décrit souvent UDP comme étant un protocole fire and forget, ce qui signifie en français tire et oublie. Imaginez que vous entendiez un bruit dans la cour de votre villa. Vous allez dans la cour, mais il fait sombre. Vous remarquez quelques mouvements, et vous prenez votre arme et tirez. Vous supposez que ce bandit qui essaie de vous cambrioler est mort et vous rentrez vous recoucher. Vous avez appuyé sur la gâchette et vous êtes rentré sans vous soucier de quoi que ce soit. Est-ce que la balle a atteint la cible ? Ce n’est pas votre problème. Vous avez tiré et après, si la cible est touchée tant mieux, sinon tant pis.
UDP signifie User Datagram Protocol (protocole de datagramme utilisateur). C’est un protocole de transport qui ne peut pas garantir que les données arriveront toutes à destination. C’est d’ailleurs l’un des principaux défauts de ce protocole. On ne peut pas être sûr que les données arriveront au destinataire, car UDP n’a pas de mécanisme de retransmission quand un paquet se perd. C’est un protocole non orienté connexion.
Dans notre premier exemple, lorsque le taxi a un accident, est-ce qu’il peut soigner ses passagers et ensuite continuer la course vers la destination ? Non ! Donc les passagers n’arriveront pas à destination, en d’autres termes, ils ne seront pas retransmis, donc se perdent. Voilà une petite introduction à ce protocole.
Pourquoi « non orienté connexion » ?
Nous avons vu que dans la couche transport, le mode d’envoi était choisi : mode orienté connexion ou non orienté connexion. Pour comprendre le principe de ces deux modes, il nous faut aborder la notion de la poignée de main (handshake).
Le principe de la poignée de main

Pourquoi vous faites cette tête-là ? Ça vous étonne qu’on parle de poignée de main en réseau ?  Nous ne le dirons jamais assez, la technologie s’inspire du monde réel.
Nous ne le dirons jamais assez, la technologie s’inspire du monde réel.  Alors qu’est-ce qu’une poignée de main ?
Alors qu’est-ce qu’une poignée de main ?
Non, c’est pour de vrai, la question est sérieuse.
Une poignée de main est une action qui se fait en deux mouvements : on tend la main et l’autre personne la prend (elle aussi nous tend la main). On se sert de ce rituel dans plusieurs domaines. Par exemple dans la vie quotidienne, la poignée de main est utilisée lors d’une salutation, alors qu’en business, c’est pour signifier une entente, un contrat conclu.
Et en réseau ?
En réseau, on se sert du principe de la poignée de main pour l’initialisation d’une connexion.
Vous vous souvenez du tout premier chapitre sur les protocoles ? Nous avons vu, par l’exemple d’une conversation au téléphone, comment opéraient les protocoles. La première étape d’une communication était l’établissement de la connexion, n’est-ce pas ?
En effet, lorsque vous téléphonez à un ami, il décroche en disant « Allô » et vous répondez « Allô ». C’est le même principe que la poignée de main, vous vous êtes mis d’accord sur le fait que vous allez engager une conversation.
En réseau, le principe reste fondamentalement le même. Quand vous voulez communiquer avec un autre hôte dans un réseau, il faut que les deux hôtes se mettent d’accord. Cette entente se fait par la poignée de main. En fait, l’hôte émetteur envoie un paquet qui dit « Est-ce qu’on peut parler ? » et l’hôte récepteur répond « Vas-y, j’écoute ». Et là les deux peuvent s’échanger des données !
Le rapport avec UDP ?
Justement, UDP n’est pas orienté connexion du fait qu’il n’implémente pas ce principe de la poignée de main. En d’autres termes, lorsqu’une application utilise UDP comme protocole, les données sont envoyées sans au préalable établir une session ou une connexion avec l’hôte récepteur. C’est pour cela que UDP ne garantit pas que les données vont arriver.
Quand vous utilisez UDP, c’est comme si vous parliez à quelqu’un qu’il soit éveillé ou endormi. S’il est éveillé tant mieux, il vous écoute, il reçoit votre message. Par contre s’il dort, tant pis, vous aurez beau parler, il ne recevra rien. Voilà pourquoi UDP est un protocole dit orienté transaction. En d’autres termes, il se contente d’envoyer le message et d’espérer que tout se passe bien.
La structure d’un datagramme UDP
UDP a été créé par David Reed en 1980 et est spécifié par la RFC 768. Comme tout protocole, il a un en-tête qui lui est propre. Dans le chapitre précédent, nous vous avons schématisé quelques champs d’un segment de protocole de transport. Ces champs sont en fait communs à UDP et TCP. Maintenant, nous allons voir de quoi est constitué un datagramme UDP entier. Pour rappel, voici à quoi ressemble une unité de protocole de transport :
Champ | Port source | Port destination | SDU |
Partie concernée | En-tête | Message | |
Les champs présents dans le tableau résultent de la fonction de multiplexage et démultiplexage comme nous l’avons vu. Mais UDP ajoute deux champs de plus. Voici la structure d’un datagramme UDP :
Bits | 0 - 15 | 16 - 31 |
|---|---|---|
0 | Source port | Destination port |
32 | Length | Checksum |
64 | SDU | |
Nous n’allons pas revenir sur les champs « source port » et « destination port », nous y avons déjà passé un bout de temps. Cependant, les deux autres champs « length » (longueur) et « checksum » (somme de contrôle) vous sont inconnus. Chacun des champs de l’en-tête UDP vaut 2 octets, soit 16 bits chacun.
- Length : ce champ spécifie la longueur de tout le datagramme. Un datagramme est le nom que l’on donne à un PDU envoyé par un protocole non fiable, comme nous l’avons dit dans les chapitres précédents. Étant donné qu’UDP n’est pas fiable, on appelle donc les données à ce niveau « datagramme » (datagram en anglais). Ainsi, le champ « length » contiendra la longueur du datagramme. Puisque nous savons déjà que chaque champ de l’en-tête vaut 2 octets, il est donc logique que la valeur minimum de ce champ est de 8 octets (2 octets x 4 champs) soit 64 bits (16 bits x 4 champs).
- Checksum : ah, vous vous souvenez de l’expression somme de contrôle ? La valeur présente dans ce champ indiquera si une erreur s’est produite durant la transmission du datagramme. Nous verrons comment cela fonctionne dans un prochain chapitre.
L’essentiel du protocole UDP
Pour commencer, jetons un coup d’œil aux caractéristiques du protocole UDP :
- Mode non connecté : nous avons dit que UDP n’utilisait pas un mode orienté connexion, donc il n’implémente pas le principe de connexion par poignée de main.
- État de connexion : l’état de connexion est un sujet un peu complexe pour l’instant, et il est propre à TCP. Alors nous n’allons pas vous faire souffrir pour rien. Retenez juste qu’UDP ne maintient pas des informations sur l’état de la connexion.
- La longueur de l’en-tête : comme vous avez eu l’occasion de le voir par vous-même, l’en-tête d’un datagramme UDP est relativement simple. Il ne vaut que 8 octets. Vous allez voir que l’en-tête de TCP est plus complexe que celui d’UDP.
- Taux de transmission : avec UDP, la vitesse (ou le taux) de transmission est intimement liée aux caractéristiques de l’environnement du système d’exploitation. C’est-à-dire que cette vitesse dépend des ressources système (fréquence du processeur, etc.) d’une part, et de la bande passante d’autre part. Puisque UDP n’a pas de mécanisme de contrôle de congestion (on en a un peu parlé précédemment), le taux de transmission dépend de la vitesse à laquelle l’application utilisée génère ces datagrammes.
Ces caractéristiques révèlent en quelque sorte les avantages d’UDP. Puisqu’il n’est pas orienté connexion, il ne crée donc pas des délais d’attente pour établir une connexion avant transmission. Grossièrement, imaginez qu’envoyer un message « salut » à un hôte prend 3 secondes. Avec TCP, ça prendra 3 secondes + x secondes, x étant le temps mis pour établir une connexion avant la transmission. C’est un exemple très simplifié. Étant donné qu’il ne gère ni l’état de la connexion, ni le contrôle de congestion, il est donc un peu plus rapide que TCP.
Utilisez UDP lorsque vous n’avez pas besoin de garantir que les données envoyées arriveront à leurs destinataires. Par exemple, dans le cadre de la VoIP (la téléphonie via Internet), plusieurs applications utilisent UDP, comme Skype. S’il faut renvoyer les messages vocaux à chaque fois jusqu’à ce qu’ils arrivent, cela va significativement engorger le réseau, voilà pourquoi les conversations téléphoniques sur Internet se font via UDP. Le service DNS (qui permet de traduire les adresses IP en noms de domaine) utilise également UDP.
Nous allons comparer UDP et TCP plus tard, et c’est là que nous allons voir quand il faut utiliser TCP et quand il faut privilégier UDP.
UDP n’étant pas vraiment un protocole très fondamental de la pile TCP-IP, nous n’allons pas nous attarder sur son compte. En revanche, nous allons vraiment nous attarder sur TCP qui a le mérite de se retrouver dans le nom même du modèle de communication sur lequel se base Internet, à savoir TCP-IP.
Le protocole pessimiste : TCP
Nous espérons que vous avez encore en mémoire les exemples précédents (transmission des lettres entre cousins des deux maisons, aller a une fête en groupe en empruntant des taxis…). Dans ces deux exemples, nous avons illustré les principes fondamentaux qui sont aussi les divergences principales entre UDP et TCP.
TCP dans les grandes lignes
TCP signifie Transmission Control Protocol, soit protocole de contrôle de transmission. C’est un protocole de la couche transport défini par les RFC 793, 1122, 1323 et aussi 2581.
Tout comme UDP, le but de TCP est d’assurer la transmission des SDU. Tout comme UDP, TCP nous offre des services de multiplexage et démultiplexage. La différence se situe fondamentalement dans ce que nous avons appelé « principe de transmission fiable ».
Dans notre exemple de transmission des lettres de début de partie, Pierre et Jean représentent un protocole de transmission. Nous avons dit que ces derniers pouvaient offrir un service fiable en garantissant à leurs frères que les lettres arriveraient à la Poste.
Dans notre exemple impliquant les files de taxis, nous avons dit qu’il était impossible de garantir que chaque groupe arriverait à la fête en raison des imprévus.
UDP, comme nous l’avons vu, est un protocole orienté transaction, par conséquent, il ne peut garantir que les données transmises arriveront à destination. TCP, en revanche, est un protocole orienté connexion. Par le principe de la poignée de main (handshake), il établit une connexion au préalable entre les processus avant de débuter la transmission.
Le nom de cette section qualifie TCP comme étant un protocole pessimiste. Vous vous demandez certainement pourquoi (faites semblant, au moins  ). TCP « n’espère pas » comme UDP que les données arriveront à destination. Au contraire, en protocole responsable, il s’assure que les données transmises arriveront à bon port. Cette garantie est possible grâce à ses fonctionnalités : détection d’erreur, contrôle de séquences, retransmissions, et la plus importante : accusé de réception.
). TCP « n’espère pas » comme UDP que les données arriveront à destination. Au contraire, en protocole responsable, il s’assure que les données transmises arriveront à bon port. Cette garantie est possible grâce à ses fonctionnalités : détection d’erreur, contrôle de séquences, retransmissions, et la plus importante : accusé de réception.
TCP offre des services de détection d’erreurs dans les transmissions, mais n’a aucune propriété de « réparation » (data recovery en anglais) de ces données dont l’intégrité est affectée.
L’état de connexion avec TCP
Nous avons dit que TCP était un protocole orienté connexion, mais qu’est-ce que cela veut dire concrètement ?
Pour qu’il y ait échange ou transmission entre deux applications utilisant TCP comme protocole de transport, il faut établir une connexion TCP. La poignée de main (handshake), le genre de connexion que TCP établit, est aussi appelé « three-way handshake ». Cela veut dire que la connexion se fait en trois étapes. Vous vous souvenez des concepts full-duplex et half-duplex ? Ils s’appliquent aussi ici. En effet, TCP est un protocole full-duplex, ce qui implique qu’une communication bidirectionnelle et simultanée est possible dans une communication TCP.
En guise de rappel, un système de communication half-duplex veut dire que la communication se fait dans un seul sens à la fois. L’hôte A transmet à l’hôte B ou vice versa, mais en aucun cas les deux peuvent transmettre simultanément. Cet avantage ne nous est offert que dans un système de transmission full-duplex, et ça tombe bien : TCP est un protocole full-duplex.
Voici comment s’établit une connexion suivant le principe de « three-way handshake ».
Supposons que 2 processus de deux hôtes différents veulent s’échanger des informations. Il faut, bien entendu, qu’un hôte initialise la connexion (demande à l’autre hôte la permission de communiquer). Comme vous le savez, l’hôte qui initialise la connexion est le client, et celui qui accepte est le serveur.
Le client et le serveur s’échangent donc des unités de données appelées des segments TCP qui sont composés bien entendu d’un en-tête et d’un espace de données (data area en anglais). Pour nous assurer que vous n’aurez pas de difficulté à assimiler le three-way handshake, nous allons y aller petit à petit en détaillant chaque étape. Le long de notre analyse, nous allons considérer 6 paramètres extrêmement importants pour saisir la procédure d’établissement d’une connexion TCP entre un client et un serveur. Ces paramètres sont :
- État du serveur ;
- État du client ;
- Segment transmis par le client ;
- Segment transmis par le serveur ;
- État de transition du client ;
- État de transition du serveur.
Les noms des paramètres sont assez évocateurs. L’état du client/serveur définit dans quel état se trouve le client/serveur dans l’établissement de la connexion. Le segment transmis par le client/serveur fait référence au segment TCP constitué d’un en-tête et d’une donnée, que les deux s’échangent le long de la procédure. Finalement, l’état de transition du client/serveur définit simplement un état… entre deux états. Un exemple : quand le serveur passe de l’état fermé (closed) à l’état ouvert, l’état de transition ici est l’état d’écoute (listen). En effet, pour pouvoir ouvrir ou initialiser une connexion, il faut bien que le serveur écoute le port auquel il est attaché. On dit que cet état d’écoute est un état de transition.
Vous êtes prêts? C’est parti ! 
Étape 1
Pour faire une demande d’initialisation de connexion, le client envoie un segment TCP qui ne contient que l’en-tête. Il est important de noter que le premier segment TCP envoyé dans le three-way handshake n’a aucun payload (aucune donnée utile), mais seulement un en-tête.
Et il y a quoi dans cet en-tête alors ?
Nous y arrivons ! L’en-tête contient un flag (drapeau) de synchronisation : SYN, diminutif de SYNchronize, synchroniser. L’en-tête contient aussi le numéro de port TCP du serveur, comme pour UDP.
Après l’envoi de ce premier segment TCP, le client se met dans un état SYN_SENT. Pour ceux qui n’ont pas séché leurs cours d’anglais (  ), vous comprenez tout de suite que SYN_SENT signifie que le segment TCP ayant le flag SYN a été envoyé.
), vous comprenez tout de suite que SYN_SENT signifie que le segment TCP ayant le flag SYN a été envoyé.
Le serveur, de son côté, est en état Listen. Il écoute sur le numéro de port, attendant une demande de connexion. Dès qu’il reçoit le segment TCP envoyé par le client (celui qui n’a qu’un en-tête et un flag SYN), il envoie un segment TCP vers le client pour confirmer sa réception. Ce segment n’est constitué que d’un en-tête portant deux flags : SYN (synchronize) et ACK (acknowledge, accusé de réception).
Finalement, le serveur change d’état et passe de Listen à SYN_RCVD, RCVD étant le diminutif de received (reçu en anglais). Cet état confirme que le segment TCP portant le flag SYN a été reçu.
SYN ou ACK sont deux flags importants dans l’en-tête d’un segment TCP. Dans un en-tête TCP, toute une zone est dédiée à ces flags. À chacun d’entre eux correspond un bit spécifique. Ainsi, quand un flag est spécifié (on dit aussi que le drapeau est levé), cela se traduit dans l’en-tête par l’allumage du bit correspondant, qui vaut alors 1. Si le drapeau n’est pas levé, le bit vaut 0. Nous allons voir la structure détaillée un peu plus loin, pas de panique !
Étapes 2 et 3
Le client reçoit le segment TCP et analyse l’en-tête. Il remarque qu’il contient les flags SYN et ACK, qui sont pour lui des indicateurs que le serveur a été gentil accepte d’initialiser une connexion avec lui. La connexion passe donc de l’état Closed (fermée) à Established (établie). Il conclut la procédure en envoyant un segment TCP avec le flag ACK au serveur en guise de remerciement. Bon, en vrai, ce dernier ACK envoyé est la conclusion de la procédure et va également mettre le serveur en état de connexion établie (established state).
Voila ! Maintenant que les deux hôtes (client et serveur) ont établi une connexion, cette dernière peut être utilisée pour transmettre des informations !
Dans notre scénario, c’est le client qui est responsable d’avoir fait une demande de connexion. On dit que le client effectue une connexion active (active open) alors que le serveur n’a fait qu’accepter l’invitation, ce dernier effectue une connexion passive (passive open).
En résumé, voici une image pour vous permettre de mieux visualiser la procédure.
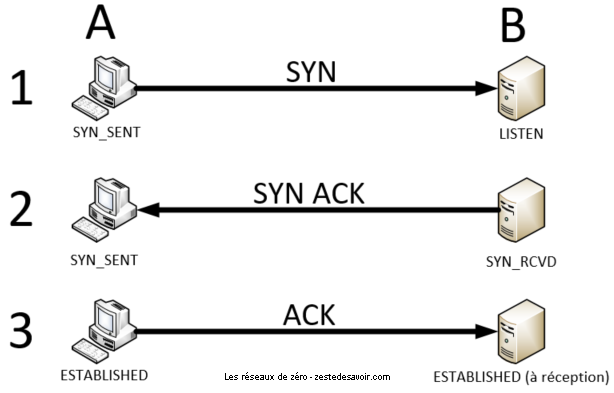
Voilà pour l’établissement, mais maintenant, il faut transmettre des données ! À quoi cela sert d’être connecté, sinon ?
Séquence émotion et acquittement
Comment TCP s’assure que les données sont bien arrivées ? Grâce à des numéros de séquence ! Lorsqu’une connexion TCP est initialisée, un nombre est généré : l'ISN (cela peut être un zéro ou un nombre aléatoire suivant les systèmes). Quand des données sont envoyées, ce numéro de séquence est augmenté d’autant d’octets de données qui sont envoyés.
Voici un exemple :

Sur cette capture, nous pouvons voir que l’hôte 192.168.1.56 a établi une connexion TCP avec 192.168.1.62. Les trois premières trames représentent le 3-way handshake. La quatrième trame, en bleu, est un envoi de données au travers de cette connexion. Regardez les valeurs de Seq et Len. Nous partons d’un numéro de séquence qui est de 1 et nous envoyons 6 octets de données. Le serveur nous répond avec un ACK (accusé de réception), ce qui signifie qu’il a bien reçu quelque chose. Il précise la valeur 7 dans le champ « Ack », car il a additionné le numéro de séquence du segment reçu (1) avec la longueur des données du segment en question (6), ce qui fait bien 7. Le client sait donc que son segment a bien été reçu.
Que se serait-il passé si le segment n’avait pas été reçu ? Pour une raison quelconque, il aurait pu être perdu en cours de route. Dans ce cas, si le client ne reçoit pas d’accusé de réception, il renvoie automatiquement le même segment au bout d’un temps défini appelé RTO. Ce temps est calculé dynamiquement. Si vous voulez vous amuser à comprendre ce mécanisme, vous pouvez lire la RFC 2988.
Lors de l’établissement en trois phases, aucune donnée n’est transmise, et pourtant, le serveur répond avec un Ack de 1 alors que le numéro de séquence du segment envoyé est 0 !
Si vous l’avez remarqué, chapeau ! Effectivement, le numéro de séquence des deux machines est augmenté de 1 lors du 3-way handshake.
Le principe des numéros de séquence et d’acquittement est fondamental pour comprendre TCP. Pourtant, ce protocole a plus d’un tour dans son sac et permet d’effectuer tout un tas de contrôles pour optimiser le traitement des communications. Avant d’aller plus loin, voyons comment est structuré un segment TCP pour visualiser toutes les possibilités qu’il offre.
Structure d’un segment
Visualisons les différents champs d’un segment TCP :
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | E C N | C W R | E C E | U R G | A C K | P S H | R S T | S Y N | F I N | Fenêtre | ||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
20 | 160 | Option(s) (facultatif) | |||||||||||||||||||||||||||||||
selon options | Données | ||||||||||||||||||||||||||||||||
La plupart des informations transmises par TCP comme la fenêtre ou la somme de contrôle seront étudiés dans les prochains chapitres. Pour conclure cette sous-partie, nous allons étudier la fermeture d’une connexion TCP.
Maintenant que nous savons comment s’ouvre une connexion TCP et que nous avons évoqué en surface l’acquittement des données transmises, il est temps de clore la connexion. Il y a deux façons de faire : la normale… et la brutale.  Commençons par la méthode douce.
Commençons par la méthode douce.
Clôture normale
Rappelez-vous ce que deux personnes font quand elles rentrent en contact : une poignée de main. Et que font-elles lorsqu’elles se séparent ? Eh bien, une autre poignée de main. Avec TCP, c’est pareil, c’est juste un peu plus long. Alors que le handshake d’initialisation se fait en 3 temps, celui de clôture se fait en 4 temps.
Considérons deux hôtes A et B qui ont initié une connexion TCP. Peu importe qui est client ou serveur, cela ne change rien. Quand ils n’ont plus rien à se dire, l’un va prendre l’initiative de clore la communication. Dans notre exemple, disons qu’il s’agit de A. Pour cela, il va envoyer un segment vide, comme pour l’ouverture de connexion, mais en levant le flag FIN. L’état de la connexion chez l’hôte A passe alors à FIN_WAIT_1.
L’hôte B va alors répondre avec un segment vide et le flag ACK levé. C’est comme la 3ème étape de l’ouverture. L’état de la connexion chez B passe alors à CLOSE_WAIT.
À ce moment-là, A a dit à B qu’il souhaitait clore la connexion, et B a confirmé avoir reçu cette demande. Il n’a pas encore accepté la clôture. Pour ce faire, il doit à son tour envoyer un message de fin, que son interlocuteur doit acquitter.
La 3ème étape est donc l’envoi par l’hôte B d’un segment vide avec le flag FIN levé. L’état de la connexion chez B devient alors LAST_ACK. De manière assez explicite, cela signifie qu’il n’attend plus qu’un dernier ACK.
C’est la 4ème et dernière étape : l’hôte A confirme la réception du dernier segment avec un ACK. Lorsqu’il est reçu par B, l’état de la connexion chez B est CLOSED. Pour lui, la connexion est proprement fermée. Au moment de l’envoi, l’état de la connexion chez A passe par la phase transitoire TIME_WAIT. Il s’agit d’une période de temps durant laquelle l’hôte patiente pour être sûr que B a bien reçu le segment. Comme il n’y a plus aucun échange après, A considère que B a reçu l’ACK au bout d’une durée égale à 2 MSL. Le MSL (Maximum Segment Lifetime) est un paramètre du système qui vaut généralement 30 secondes ou 1 minute.
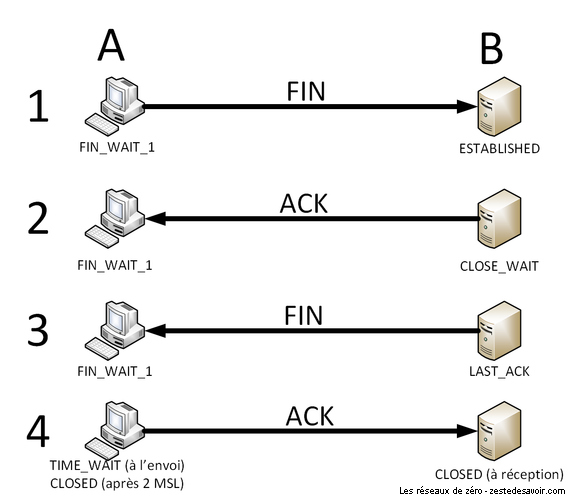
Depuis un système Windows ou Linux, on peut visualiser l’état des différentes connexions de notre système avec la commande netstat. Voici un extrait de ce qu’elle peut nous retourner (les adresses IP ont été modifiées) :
TCP 127.0.0.1:63146 DESKTOP-XXXXXXX:63145 ESTABLISHED
TCP 192.168.1.14:62442 ec2-94-107-164-227:https ESTABLISHED
TCP 192.168.1.14:62953 192.125.106.67:27021 ESTABLISHED
TCP 192.168.1.14:63217 48.97.221.206:https ESTABLISHED
TCP 192.168.1.14:63266 65:imap CLOSE_WAIT
TCP 192.168.1.14:63275 65:imap CLOSE_WAIT
TCP 192.168.1.14:63282 14.215.39.17:https ESTABLISHED
TCP 192.168.1.14:63283 41.70.165.13:https TIME_WAIT
TCP 192.168.1.14:63284 140.11.113.150:https ESTABLISHED
TCP 192.168.1.14:63285 123.17.31.28:https ESTABLISHED
Ça, c’est si tout se passe bien (et ça se passe généralement bien). Mais que se passe-t-il en cas de pépin ?
Clôture brutale
Il existe un flag TCP qui fait partie des plus courants : RST (reset). RST signifie à peu près « va te faire voir ». Ce drapeau apparait lorsqu’une communication non autorisée arrive sur un port.
Typiquement, si vous essayez d’ouvrir une connexion TCP avec un hôte sur un port quelconque, sitôt votre premier SYN envoyé, vous allez recevoir un segment vide avec seulement le flag RST levé (et un ACK pour préciser à quoi on répond). Pourquoi ? Parce que le système que vous contactez va recevoir votre demande de connexion, va regarder le port destination, et si aucun programme n’écoute sur ce port, il n’a aucune raison d’accepter et vous le fait savoir sans détour.
Dans ce même cas de figure, il est aussi possible que vous ne receviez rien du tout. Cela arrive lorsque l’hôte distant est protégé par un pare-feu. Ce dernier peut être configuré pour ignorer les demandes de connexion sur des ports inconnus. Cela permet d’éviter d’ennuyer les serveurs avec des requêtes inutiles.
Il peut aussi arriver qu’une connexion déjà établie soit brutalement interrompue par un flag RST. Cela peut se produire en cas de mauvais comportement d’un hôte. Un programme peut être conçu pour mettre fin à une connexion s’il détecte que son interlocuteur envoie des données inattendues : requêtes mal formées, brute force de mot de passe, … Dans ce genre de cas, mieux vaut ne pas prendre de pincettes.
Pour aller plus loin, nous vous conseillons l’outil socklab. Il s’agit d’un programme français très utilisé dans les universités pour l’expérimentation sur TCP et UDP. Vous trouverez une documentation en suivant ce lien.
Nous venons d’évoquer les principes de base de TCP. Oui, de base. Les notions plus complexes viendront plus tard. Avant cela, reposons-nous un peu la tête en regardant l’affrontement entre TCP et UDP.
TCP / UDP : le clash !
Eh bien, en réalité, il n’y a pas de clash puisque ces deux protocoles ne sont pas concurrents, mais complémentaires. C’est comme imaginer un clash entre un rhinocéros et un aigle. Et non, dans Pokémon ça ne compte pas.
Les usages sont fondamentalement différents. Le choix de l’un ou l’autre peut venir de plusieurs facteurs.
Nécessité fonctionnelle
En premier lieu, une application peut tout bonnement ne pas fonctionner si son protocole n’est pas transporté de manière appropriée. Prenons pour exemple la visioconférence. Pour que l’image et la voix de votre interlocuteur vous parviennent de manière fluide, il faut que les données transitent rapidement et sans gigue. La gigue (en anglais jitter) est le phénomène de décalage, de délai entre l’émission et la réception d’un flux. Le délai de transmission en soi n’est pas forcément gênant, mais si ce délai se met à s’allonger ou se raccourcir brusquement, la vidéo sera saccadée ou, a contrario, passera en accéléré pendant un court temps.
Si nous faisons passer un flux de visioconférence sur UDP, que se passera-t-il ? La vidéo va être découpée en petits morceaux au fur et à mesure, puis envoyée directement sans certitude que chaque pièce soit bien reçue. Pour le récepteur, il est donc possible que les morceaux n’arrivent pas tous dans le même ordre voire que certains n’arrivent pas du tout. Si ce cas ne se produit pas souvent, ce n’est pas forcément gênant : la perte de 100 millisecondes de voix ou d’image n’empêche généralement pas la compréhension par le destinataire, même si cela arrive toutes les 10 secondes. Dans ce cas, c’est de la qualité du réseau que dépendra la qualité de la communication.
Maintenant, que se passerait-il si le même flux était transmis sur TCP ? La moindre donnée perdue devrait être retransmise. TCP considère qu’un segment est perdu lorsqu’il n’a pas reçu d’accusé de réception au bout d’un temps donné, le RTO, qui est de l’ordre de la seconde. Un problème de taille se pose alors : l’hôte destinataire n’enverra pas d’accusé de réception tant qu’il n’aura pas reçu ce paquet perdu, même s’il a reçu tous ceux qui suivent. En l’absence de cet acquittement, l’expéditeur va ralentir le rythme, voire arrêter sa transmission. Catastrophe ! Le flux se retrouve alors interrompu temporairement. Quand il reprendra, le délai entre émission et réception se sera élargi, causant ainsi une gigue. Pour compenser cet écart, l’application doit se débrouiller pour passer un moment en accéléré, couper un morceau, etc. De plus, la transmission sur TCP encombre davantage le réseau : les en-têtes sont plus volumineux que ceux de UDP, et les acquittements occupent aussi le support.
La transmission de visioconférence sur TCP n’a donc presque aucun avantage pour beaucoup d’inconvénients, pouvant aller jusqu’au non fonctionnement de l’application. Dans ce cas de figure, UDP s’impose, malgré quelques faiblesses qui peuvent être plus facilement compensées par l’application.
Le cas inverse se rencontre avec d’autres protocoles. Prenons l’exemple de SMTP, que nous avons étudié précédemment. Imaginons qu’un e-mail un peu volumineux, avec des pièces jointes, soit transmis sur UDP. Le message devra être découpé en plusieurs datagrammes. Que se passerait-il si l’un d’entre eux se perdait ? L’expéditeur ne pourrait pas savoir si son courriel a été correctement reçu. Le serveur de messagerie recevrait un message inconsistant, avec éventuellement une pièce jointe corrompue, un contenu dont la taille ne coïncide pas avec celle déclarée dans l’en-tête du mail, … On pourrait imaginer que le serveur renvoie un message à l’expéditeur pour lui dire que quelque chose cloche, mais d’une part, ce n’est pas son rôle, d’autre part, on ne pourrait même pas s’assurer que le message d’erreur arrive à bon port. En revanche, ces problématiques sont très bien gérées par TCP. Ce dernier s’impose donc comme protocole de transport pour SMTP.
Nécessité matérielle
On peut aussi se retrouver contraint d’utiliser TCP ou UDP pour des raisons matérielles. Nous avons évoqué le fonctionnement de BitTorrent précédemment. Ce protocole utilise TCP pour la transmission des données (les fichiers échangés), et UDP pour la transmission d’informations de contrôle. En 2008, la société BitTorrent, qui gère le protocole du même nom, a envisagé la possibilité de transmettre les données sur UDP. À cette période, ce système d’échanges P2P était très utilisé, bien plus que de nos jours (2018). UDP n’offrant pas de mécanismes de contrôle de flux ou de congestion, contrairement à TCP, des craintes sont apparues quant à la saturation de réseaux. Cet article de NextINpact résume la problématique soulevée à l’époque. Il ne s’agissait pas là d’une question de fonctionnement de l’application, mais de savoir si les infrastructures matérielles étaient capables de supporter le changement. Finalement, c’est toujours TCP qui transmet les fichiers échangés sur BitTorrent.
Complémentarité
Nous avons dit que TCP et UDP étaient complémentaires. En réalité, ils le sont tellement qu’un même protocole peut utiliser les deux.
Mais comment est-ce possible ? 
Comprenons-nous bien, il ne s’agit pas d’utiliser les deux en même temps. L’un ou l’autre peut être utilisé en fonction du contexte ou des données. Dans le paragraphe précédent sur BitTorrent, nous avons évoqué le fait que TCP était utilisé pour les contenus et UDP pour les informations. La différence se fait sur les données à transmettre. Il existe aussi des cas où la différence est contextuelle.
Le protocole DNS (Domain Name System) permet de faire le lien entre noms de domaines, comme zestedesavoir.com, et adresses IP, comme 2001:4b98:dc0:41:216:3eff:febc:7e10 (un peu d’IPv6 pour changer !  ). Quand un hôte demande à un serveur DNS une adresse IP, l’échange se fait sur UDP. Par contre, lorsque deux serveurs DNS font partie d’un même ensemble (l’un étant le backup de l’autre par exemple, ce qu’on appelle une relation maitre-esclave), les requêtes DNS entre ces serveurs se font en TCP.
). Quand un hôte demande à un serveur DNS une adresse IP, l’échange se fait sur UDP. Par contre, lorsque deux serveurs DNS font partie d’un même ensemble (l’un étant le backup de l’autre par exemple, ce qu’on appelle une relation maitre-esclave), les requêtes DNS entre ces serveurs se font en TCP.
Pourquoi ça ne se fait pas en UDP comme pour les requêtes habituelles ?
C’est une question de contexte. Quand votre ordinateur envoie une requête DNS ou reçoit une réponse, le contenu est minimaliste. Le paquet tout entier va faire quelques centaines d’octets tout au plus. Si on l’expédiait sur TCP, le volume d’échanges pour une seule requête serait au minimum doublé : d’abord le 3-way handshake, le paquet contenant la requête serait alourdi de tout l’en-tête TCP, le serveur devrait répondre d’un acquittement même s’il n’a pas de réponse à fournir, sans compter la clôture propre de la connexion. Le jeu n’en vaut pas la chandelle, on préfère envoyer les requêtes DNS sur UDP quitte à devoir en retransmettre une de temps en temps en cas de perte.
Toutefois, quand deux serveurs travaillent en binôme, il est primordial qu’ils soient synchros sur les réponses qu’ils fournissent aux clients. On ne peut pas se permettre que l’un soit au courant d’une correspondance nom de domaine-adresse IP et pas l’autre : cela serait bancal pour les utilisateurs. On a besoin, dans le cadre de cette relation maitre-esclave, de fiabilité. Dans ce contexte, le volume d’échanges peut parfois être important (dans le cas de transfert de zones notamment), et le besoin de transmission fiable est réel, on utilise donc TCP.
Voici un schéma illustrant cela. Notez que lorsqu’une requête DNS d’un client est particulièrement volumineuse, on utilise aussi TCP, bien que ce cas soit rare.
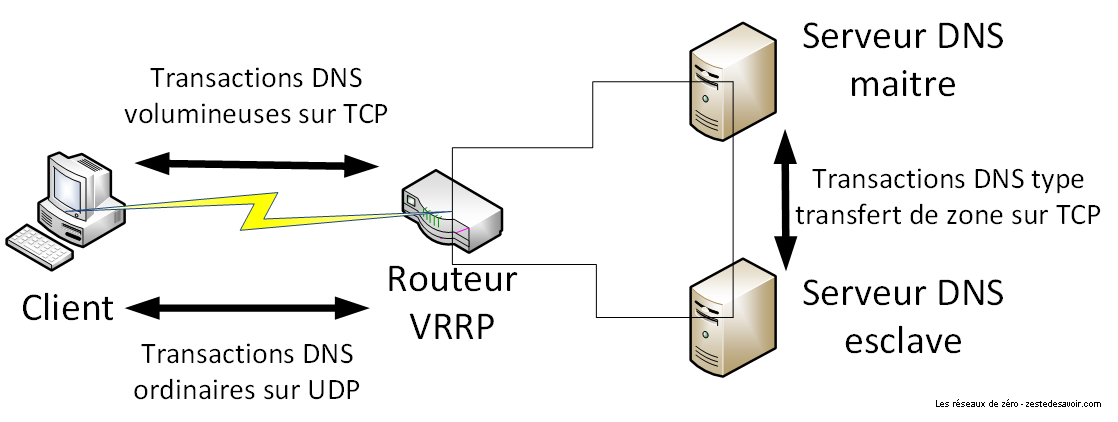
Dans ce schéma, on peut voir un routeur qui sert d’intermédiaire entre les serveurs DNS et le client. Il fait le relai dans le cadre du VRRP, un protocole qui permet de basculer d’un serveur à l’autre en cas de problème ou pour équilibrer la charge.
Ce chapitre nous a permis d’étudier les faiblesses du protocole UDP et surtout de comprendre pourquoi TCP est le protocole de transport le plus utilisé. En outre, vous avez saisi que dans certaines circonstances, il est préférable d’utiliser UDP. Le but de la connaissance théorique des protocoles est justement de vous permettre d’être en mesure de choisir celui qui correspond le mieux aux contraintes de votre projet. TCP, comme nous l’avons souligné, est un protocole très riche, c’est pour cela que nous ne pouvons pas évoquer d’un seul coup toutes les possibilités qu’il offre.