Dans ce chapitre, nous allons attirer votre attention sur les protocoles de routage. Vous avez pu lire une introduction à cette notion dans le chapitre précédent. Il est maintenant temps de voir quelles sont les caractéristiques des différents protocoles de routage. Nous allons nous focaliser sur RIP, OSPF et BGP.
- Direct au cimetière avec RIP
- Vecteur de distances
- OSPF, le mastodonte
- Protocoles à états de lien
- BGP : les entrailles d'Internet
Direct au cimetière avec RIP
Tout comme les adresses MAC n’ont aucun rapport avec les ordinateurs Apple, RIP n’a rien d’une pierre tombale. Loin de signifier Requiescat In Pace, on parle ici de protocole d’information de routage (Routing Information Protocol). Il permet de faire du routage dynamique, c’est-à-dire sans intervention humaine. Les routeurs peuvent s’échanger dynamiquement les informations de routage au moyen de ce protocole.
Il est défini par la RFC 1058 et utilise un algorithme de routage dit à vecteur de distances (distance vector). Retenez ce nom, nous étudierons cette notion par la suite. RIP est classé dans la famille des protocoles de routage interne (IGP), que nous avons évoquée dans notre introduction aux protocoles de routage.  Les protocoles de routage à vecteur de distances, comme RIP, sont basés sur l’algorithme de Bellman-Ford.
Les protocoles de routage à vecteur de distances, comme RIP, sont basés sur l’algorithme de Bellman-Ford.
Il existe deux versions de ce protocole. Commençons par étudier la différence entre ces versions avant de plonger dans la technique.
Première version
La toute première version de ce protocole ne pouvait fonctionner que dans un réseau utilisant l’adressage par classe.  Cela veut donc dire que dans un réseau utilisant RIPv1 comme protocole de routage, on ne peut pas utiliser des techniques telles que l’implémentation des masques de sous-réseaux à longueur variable (VLSM) ou l’agrégation des routes (supernetting). Une autre faiblesse de cette version est qu’elle ne peut supporter qu’un maximum de 15 sauts. Cela veut dire que s’il y a plus de 15 sauts entre deux passerelles, RIP ne pourra pas assurer son devoir de routage. Ce n’est pas tout : RIPv1 ne supporte pas l’authentification.
Cela veut donc dire que dans un réseau utilisant RIPv1 comme protocole de routage, on ne peut pas utiliser des techniques telles que l’implémentation des masques de sous-réseaux à longueur variable (VLSM) ou l’agrégation des routes (supernetting). Une autre faiblesse de cette version est qu’elle ne peut supporter qu’un maximum de 15 sauts. Cela veut dire que s’il y a plus de 15 sauts entre deux passerelles, RIP ne pourra pas assurer son devoir de routage. Ce n’est pas tout : RIPv1 ne supporte pas l’authentification.  Ainsi, il accepte et intègre tous les messages qu’il reçoit de tout le monde sans sourciller. Cela fait donc de RIPv1 un protocole très vulnérable. Pour terminer sur les caractéristiques de cette version, les routeurs utilisant RIPv1 mettent à jour leurs tables de routage en les broadcastant (diffusant) sur tous les routeurs adjacents (ou voisins).
Ainsi, il accepte et intègre tous les messages qu’il reçoit de tout le monde sans sourciller. Cela fait donc de RIPv1 un protocole très vulnérable. Pour terminer sur les caractéristiques de cette version, les routeurs utilisant RIPv1 mettent à jour leurs tables de routage en les broadcastant (diffusant) sur tous les routeurs adjacents (ou voisins).
Alléluia, la v2 est là
Comme nous l’avons vu, la version 1 est toute pourrie limitée. Elle était pratique jusqu’à un certain moment, alors ses créateurs ont décidé de la faire évoluer : c’est la naissance de RIP version 2 (RIPv2). Cette dernière supporte l’implémentation des masques de sous-réseaux, ce qui veut dire qu’elle peut efficacement router les paquets dans un réseau basé sur l’adressage CIDR. L’échange des tables de routage se fait par multicast. Les tables de routage sont transmises aux autres routeurs adjacents à l’adresse 224.0.0.9.
L’autre grande avancée de RIPv2 est qu’on peut désormais sécuriser l’accès à un routeur en utilisant une authentification chiffrée.
Côté technique
Ces présentations étant faites, explorons un peu ce protocole d’un point de vue technique.
Nous avons déjà vu que l’unité de métrique du protocole IP était appellée « saut ». Voilà une caractéristique de RIP : pour empêcher les boucles de routage, RIP limite le nombre de sauts par chemin de la source à la destination. Nous avons vu que la limite de sauts était de 15. Notons aussi que RIP utilise le protocole UDP que nous avons étudié dans la couche transport et 520 comme numéro de port.
Le principal rôle des protocoles de routage est l’échange d’informations sur les routes. Que se passe-t-il alors dans un réseau si une route ne fonctionne plus ? Les routeurs continueront à s’échanger des tables de routage. Cela veut donc dire que des informations fausses pourront être transmises à d’autres routeurs. Pour empêcher la diffusion de ces informations inexactes, RIP utilise trois mécanismes distincts : split horizon, route poisoning et finalement le holddown. Voyons en détail cette première technique, split horizon.
Séparation horizontale
Cette technique, qui est d’ailleurs reprise par d’autres protocoles comme IGRP et EIGRP, empêche un routeur de diffuser des fausses informations en l’interdisant de transmettre sa table de routage par l’interface au travers de laquelle il a reçu la dernière mise à jour de sa table.
C’est peut-être confus, nous allons regarder cela avec un schéma à l’appui pour mieux comprendre.
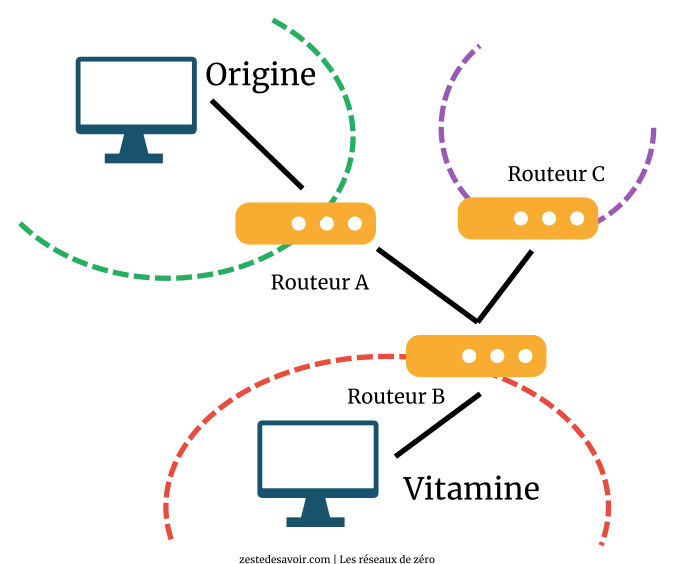
Dans le schéma ci-dessus, l’échange des tables de routage devrait, en principe, se faire comme suit :
- A envoie sa table a B ;
- B met sa table à jour et la renvoie à A ;
- B envoie sa table à C ;
- C met sa table à jour et la renvoie à B.
Maintenant, que se passerait-t-il si après la deuxième étape, le routeur A tombait en panne, comme illustré dans le schéma ci-dessous ?
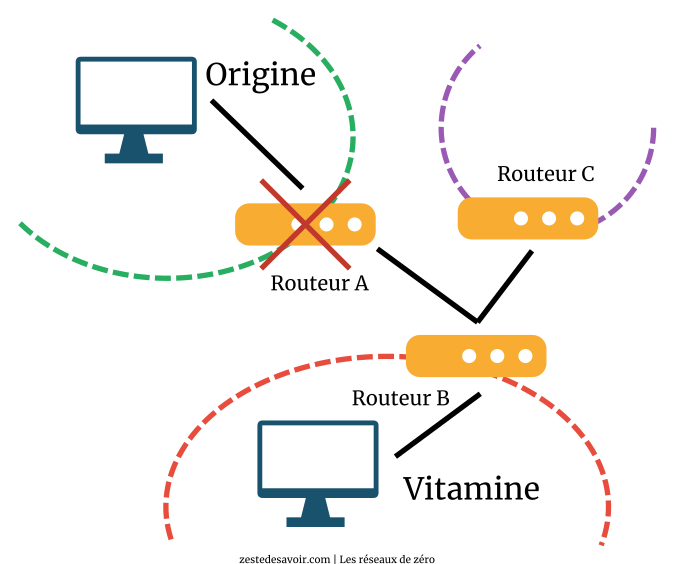
En toute logique, C va mettre sa table à jour comme l’indique l’étape 4 et ensuite renvoyer sa table à B !
Et quel est le problème ?
Eh bien, quand B a envoyé sa table à C, elle contenait la route vers le réseau Origine, auquel A est directement relié. Mais, si le routeur A est en panne, cela veut dire que la route vers Origine n’existera plus. C va alors transmettre de fausses informations à B, car la route menant à A n’existe plus !
Malheur ! Comment éviter un tel drame ? 
C’est justement le split horizon qui fera ça. Par ce mécanisme, RIP va interdire à C de renvoyer sa table de routage à B, puisque, de toutes les façons, aucun paquet ne sera transmis au réseau Vitamine via A. C et B sont directement reliés, donc ça ne servirait à rien de passer par A pour transmettre un paquet au réseau Vitamine.
Avant de passer à la conclusion de cette section, un mot sur les autres techniques pour éviter de pourrir les tables de routage. Le route poisoning (empoisonnement de route) consiste à combattre le feu par le feu.  Un routeur qui détecte la perte d’une connexion à un réseau adjacent, comme A à Origine ou B à Vitamine, peut immédiatement mettre à jour la route vers ce réseau en indiquant un nombre de sauts de 16. Comme cette valeur n’est pas permise par RIP, les routeurs considéreront la route comme invalide et ne la prendront plus en compte. Le holddown consiste à être prudent : quand une information de route injoignable est reçue, un compte à rebours se déclenche, durant lequel sera ignoré tout message indiquant que la route est joignable. Cela permet de ne pas prendre en compte une information qui parviendrait avec un délai et qui invaliderait à tort le message d’indisponibilité.
Un routeur qui détecte la perte d’une connexion à un réseau adjacent, comme A à Origine ou B à Vitamine, peut immédiatement mettre à jour la route vers ce réseau en indiquant un nombre de sauts de 16. Comme cette valeur n’est pas permise par RIP, les routeurs considéreront la route comme invalide et ne la prendront plus en compte. Le holddown consiste à être prudent : quand une information de route injoignable est reçue, un compte à rebours se déclenche, durant lequel sera ignoré tout message indiquant que la route est joignable. Cela permet de ne pas prendre en compte une information qui parviendrait avec un délai et qui invaliderait à tort le message d’indisponibilité.
Comparaison finale
Pour terminer sur RIP, voici un tableau comparant les deux versions.
| Propriété | RIPv1 | RIPv2 |
|---|---|---|
| Famille de protocole | IGP | IGP |
| Intervalle de mise à jour | 30 secondes | 30 secondes |
| Système d’adressage | Par classes | Sans classe |
| Algorithme de base | Bellman-Ford | Bellman-Ford |
| Adresse de mise à jour | Broadcast sur 255.255.255.255 | Multicast sur 224.0.0.9 |
| Protocole et port | UDP 520 | UDP 520 |
| Unité de métrique | Saut (jusqu’à 15) | Saut (jusqu’à 15) |
| Élément de mise à jour | Table entière | Table entière |
Le tableau ci-dessus n’est pas complet, nous n’avons pas représenté toutes les caractéristiques de RIP. Par exemple, nous n’avons pas spécifié la valeur par défaut de la distance administrative, qui constitue également une métrique. Toutefois, cette métrique n’existe que sur les routeurs Cisco, nous n’avons pas trouvé nécessairement opportun d’en parler.
Vecteur de distances
Nous avons dit que RIP, comme la majorité des protocoles de routage à vecteur de distances, sont basés sur l’algorithme de Bellman-Ford. C’est ce principe algorithmique que nous allons maintenant explorer.
Dans un réseau basé sur un protocole de routage à vecteur de distance (VD, ou aussi distance vector, DV), le chemin que doit emprunter un paquet est déterminé par deux critères :
- La distance : dans un algorithme VD, la distance entre deux réseaux est la valeur de l’unité de métrique qui les sépare. Cette unité, pour les protocoles VD, correspond généralement au nombre de sauts. Ainsi, la distance entre un réseau A et un réseau B est déterminée par le nombre de routeurs qui les sépare.
- La direction : ce critère est déterminé par deux facteurs.
- Le next hop : quand nous avions vu ce qu’était une table de routage, nous avons dit que le next hop ou prochain saut était l’adresse IP du routeur auquel les paquets devaient être routés.
- L’interface de sortie : il s’agit de l’interface par laquelle sortiront les paquets routés vers le next hop de la table de routage.
Dans un réseau pareil, les routeurs sont représentés sous forme de vecteurs de direction et de distance. Le contenu de leurs tables de routage résulte du calcul de la direction et de la distance entre réseaux. Les routeurs ne connaissent pas tous les chemins possibles, car lors des échanges de table de routage, seuls des échanges directs s’effectuent. En d’autres termes, les routeurs n’échangent leur table qu’avec les routeurs auxquels ils sont directement reliés. Ils n’ont pas de vision globale du réseau. Cette philosophie de routage est également appellée « routage par rumeur ». Par « rumeur », la pensée exprimée est qu’on ne sait pas si une information est vraie ou fausse. Les routeurs dans un réseau basé sur un protocole de routage VD s’appuient sur les informations reçues des routeurs voisins, auxquels ils sont directement reliés, pour assurer le routage, sans vérifier leur véracité.
Le principe d’un algorithme VD
Nous allons voir comment fonctionne un algorithme de routage à vecteur de distances. C’est une notion un peu difficile à appréhender, nous allons donc l’illustrer au mieux et le plus précisément possible (comme toujours  ).
).
Nous allons considérer le réseau suivant, constitué des routeurs A, B, C, D, et E. Ces 5 routeurs sont reliés entre eux comme le montre le schéma ci-dessous. Les traits orange représentent les connexions entre les routeurs, mais attention ! Ils ne sont pas directement reliés entre eux.
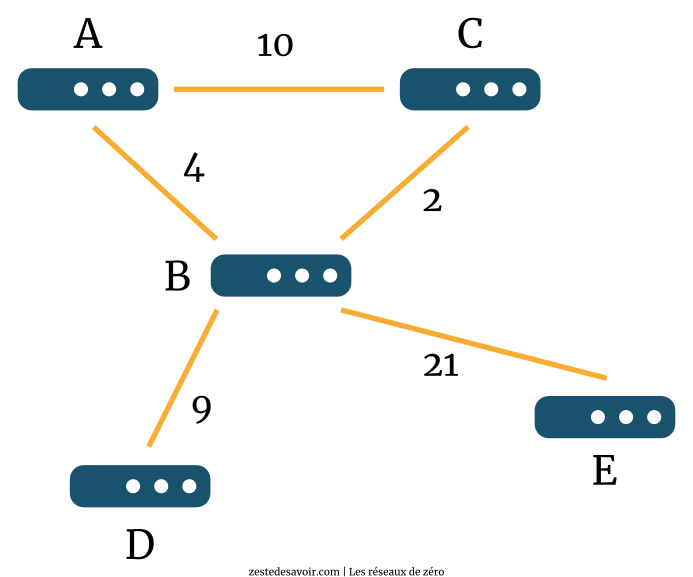
Comme l’indique le schéma, il y a des sauts entre chaque routeur. Par exemple, entre les routeurs A et C, il y a 10 sauts, ce qui indique qu’il y a a priori 10 routeurs qui les séparent. Nous n’allions quand même pas tous les représenter.  Nous allons utiliser ce réseau de base pour analyser comment le meilleur chemin est déterminé par cet algorithme VD.
Nous allons utiliser ce réseau de base pour analyser comment le meilleur chemin est déterminé par cet algorithme VD.
Déterminons les chemins actuels
| À partir de A | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | 4 | ||||
| allant vers C | 10 | ||||
| allant vers D | |||||
| allant vers E |
| À partir de B | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 4 | ||||
| allant vers B | |||||
| allant vers C | 2 | ||||
| allant vers D | 9 | ||||
| allant vers E | 21 |
| À partir de C | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 10 | ||||
| allant vers B | 2 | ||||
| allant vers C | |||||
| allant vers D | |||||
| allant vers E |
| À partir de D | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | 9 | ||||
| allant vers C | |||||
| allant vers D | |||||
| allant vers E |
| À partir de E | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | 21 | ||||
| allant vers C | |||||
| allant vers D | |||||
| allant vers E |
Après initialisation, les routeurs vont « découvrir » l’environnement dans lequel ils se trouvent. Cette « découverte » leur permettra de commencer à remplir leur table de routage. Comme vous le voyez, le routeur A ne connait que le chemin vers ses routeurs voisins, soit B et C. Pour aller à B, il peut y aller directement et cela ne lui coute que 4 sauts. Pour aller à C, cela coute 10 sauts. À ce stade précis, pour le routeur A, C est le meilleur chemin (étant donné que c’est l’unique) pour arriver au réseau C, et B également est le meilleur chemin pour arriver au réseau B.
Nous n’avons pas représenté les différents réseaux que ces routeurs lient. En pratique, A dispose d’une interface liée au réseau A, B a une interface liée au réseau B, etc.
Le routeur B de son côté fera la même chose. Il va remplir sa table en fonction de ses routeurs voisins. Étant donné que B est le routeur « central », il aura dès le départ plus d’informations que les autres. Il sait qu’il existe un chemin menant à A en passant directement par A, et qu’il coute 4 sauts. Il existe également un chemin menant à C en passant directement par C qui coute 2 sauts. Le reste des données du tableau devrait vous paraitre évident.
Le routeur C, quant à lui, est relié aux routeurs A et B. Il va donc remplir sa table en fonction de ces liaisons. Il faut 10 sauts pour arriver à A en passant par A directement et 2 sauts pour atteindre B directement. À ce stade également, le vecteur A10 constitue le meilleur chemin pour atteindre A, de même que B2 est le meilleur chemin pour atteindre B.
L’appellation « vecteur A10 », par exemple, vient du fait que chaque routeur est considéré comme étant un vecteur de distance. Le vecteur est donné par la direction (le routeur vers lequel on se dirige, A en l’occurrence) et la distance (le nombre de sauts, 10 en l’occurrence). Donc, pour le routeur D par exemple, B9 est le routeur B, éloigné de 9 sauts.
Le routeur D ainsi que le routeur E sont isolés, les pauvres ! Ils ne connaitront qu’une seule route directe chacun et cette route passe obligatoirement par B. D y est relié par une route qui coute 9 sauts, et il en faut 21 pour qu’un paquet venant du réseau E atteigne le réseau B.
Premier échange des VD
| À partir de A | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | 4 | 12 | |||
| allant vers C | 6 | 10 | |||
| allant vers D | 13 | ||||
| allant vers E | 25 |
| À partir de B | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 4 | 12 | |||
| allant vers B | |||||
| allant vers C | 14 | 2 | |||
| allant vers D | 9 | ||||
| allant vers E | 21 |
| À partir de C | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 10 | 6 | |||
| allant vers B | 6 | 2 | |||
| allant vers C | |||||
| allant vers D | 11 | ||||
| allant vers E | 23 |
| À partir de D | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 13 | ||||
| allant vers B | 9 | ||||
| allant vers C | 11 | ||||
| allant vers D | |||||
| allant vers E | 30 |
| À partir de E | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 25 | ||||
| allant vers B | 21 | ||||
| allant vers C | 23 | ||||
| allant vers D | 30 | ||||
| allant vers E |
Après un laps de temps (30 secondes en ce qui concerne RIP), les routeurs vont s’échanger les informations qu’ils ont reçues lors de la découverte de leur environnement.
B enverra donc sa table de routage aux routeurs auxquels il est connecté, soit A, C, D, et E, et ces derniers pourront mettre leurs tables à jour.
Jetons un coup d’œil à la mise à jour effectuée par A.
A découvre qu’il existe une route vers un réseau D. Mais pour atteindre cette route, il faut passer par B. Étant donné que les routeurs sont représentés comme des vecteurs de distance, comme nous l’avons vu, A pourra alors calculer le nombre de sauts qui le sépare de D. Dans la première étape, il a découvert qu’il pouvait accéder à un réseau B au prix de 4 sauts. Lorsqu’il reçoit la table de routage de B, ce dernier l’informe qu’il est relié à un réseau D avec pour coût 9 sauts.
Ce qui nous donne :
- A -> B = 4
- B -> D = 9
- Donc A->D = A->B + B->D
- A -> D = B(4+9) = B13
Le routeur A devient alors un vecteur B13, ce qui veut dire que pour accéder à D, A doit passer par B et cela coûtera 13 sauts. Par la même mise à jour, A découvre également qu’une autre route existe vers un réseau C.
Mais lors de la découverte, il le savait déjà, non ? Pourquoi est-ce qu’il considère une nouvelle route vers un réseau qu’il connait déjà ?
Le but d’un protocole de routage est de connaitre tous les chemins possibles pour atteindre une route donnée, pour la redondance et la rapidité. La route découverte par A vers C lors de l’étape 1 valait 10 couts, n’est-ce pas ? Mais B envoie à A sa table de routage et lui dis « Tiens, j’ai découvert un chemin menant à C et cela ne me coute que 2 sauts ». A va calculer la distance entre lui et C via B, et il se rend compte que ça ne lui coute que 6 sauts. Il enregistre donc cette nouvelle route dans sa table de routage, et cette dernière deviendra la plus courte pour atteindre C. Au lieu d’aller à C directement, ce qui coute 10 sauts, il est plus rentable de passer par B, ce qui ne coutera que 6 sauts.
A ne supprime pas la route initiale menant à C qu’il a découverte dans l’étape 1. Il faut garder toutes les routes possibles menant vers un réseau voisin.
Quant à B, il découvre après avoir reçu la table de routage de C, qu’il existe une autre route vers A, mais en passant par C. Il va donc calculer la distance qui le sépare de A :
- B - > C = 2
- C -> A = 10
- Donc B -> A = B -> C + C -> A = C(2+10) = C12
La nouvelle route conduisant à A coute 12 sauts en passant par C. B gardera donc la route directe (4 sauts) vers A comme la route la plus rapide, mais ajoutera à sa table le nouvel itinéraire vers A via C.
Le routeur C va découvrir l’existence de 2 nouvelles routes. Il s’agit de D et E, lesquelles routes ne sont accessibles que via B. Sachant, grâce à la table de routage qu’il a reçue de B, que la distance entre B et D est de 9 sauts et celle entre B et E, de 21 sauts, il peut facilement calculer le nombre de sauts le séparant de ces deux réseaux. Cela donne 11 et 23 pour D et E respectivement. Vous devriez avoir compris comment nous avons eu 11 et 23. 
D également découvrira des nouvelles routes, 3 pour être précis. Une route menant à A, une autre menant à C, et une autre menant à E, le tout accessible via B. Il va également calculer la distance qu’il y a entre lui et ces routes et mettre à jour sa table de routage, d’où les nouvelles valeurs que vous pouvez observer dans la table de D. Inutile de détailler les calculs, le principe est le même.
Finalement, E reçoit la table de routage en provenance de C et découvre l’existence des routes A, C et D, accessibles via B. Il fait les calculs pour trouver les valeurs des sauts et met sa table de routage à jour.
Lors de la prochaine mise à jour, il s’agit du même principe : la découverte de tous les chemins possibles et la mise à jour des tables… en faisant bien attention au split horizon : tout chemin qui ferait revenir un routeur vers lui-même ne sera pas pris en compte. Nous n’allons donc pas détailler les 5 tableaux qui suivront. Notez simplement que les tables de routage D et E ne connaissent aucune mise à jour. Ces routeurs n’ont plus rien à apprendre, ce qui est logique car tous les routeurs qu’ils peuvent atteindre passent obligatoirement par B, il n’y a pas d’alternatives.
Deuxième échange des VD
| À partir de A | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | 4 | 12 | |||
| allant vers C | 6 | 10 | |||
| allant vers D | 13 | 21 | |||
| allant vers E | 25 | 33 |
| À partir de B | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 4 | 12 | |||
| allant vers B | |||||
| allant vers C | 14 | 2 | |||
| allant vers D | 9 | ||||
| allant vers E | 21 |
| À partir de C | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 10 | 6 | |||
| allant vers B | 14 | 2 | |||
| allant vers C | |||||
| allant vers D | 23 | 11 | |||
| allant vers E | 35 | 23 |
| À partir de D | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 13 | ||||
| allant vers B | 9 | ||||
| allant vers C | 11 | ||||
| allant vers D | |||||
| allant vers E | 30 |
| À partir de E | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 25 | ||||
| allant vers B | 21 | ||||
| allant vers C | 23 | ||||
| allant vers D | 30 | ||||
| allant vers E |
Un commentaire rapide de cette étape : A découvre qu’il peut atteindre D et C, non seulement au travers de B, mais également par C. Il fait les calculs et met sa table à jour.
B n’a aucune mise à jour à effectuer, il connait déjà toutes les routes possibles du réseau.
C découvre qu’il peut atteindre D et E, toujours au travers de B mais en passant par A. En fait, il ne saura même pas que cette nouvelle route passera encore par B. Il reçoit la table de routage de A qui dit « Hé, tu sais quoi ? J’ai découvert un chemin qui mène à D et E ». Il enregistre l’information : « Cool, je peux donc atteindre D et E par A ». C’est tout ce qu’il sait. Bien entendu, ces nouveaux itinéraires sont plus coûteux pour C par rapport à un accès direct via B !
Suite et fin de l’algorithme
| À partir de A | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | |||||
| allant vers B | ✔ 4 | 12 | |||
| allant vers C | ✔ 6 | 10 | |||
| allant vers D | ✔ 13 | 21 | |||
| allant vers E | ✔ 25 | 33 |
| À partir de B | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | ✔ 4 | 12 | |||
| allant vers B | |||||
| allant vers C | 14 | ✔ 2 | |||
| allant vers D | ✔ 9 | ||||
| allant vers E | ✔ 21 |
| À partir de C | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | 10 | ✔ 6 | |||
| allant vers B | 14 | ✔ 2 | |||
| allant vers C | |||||
| allant vers D | 23 | ✔ 11 | |||
| allant vers E | 35 | ✔ 23 |
| À partir de D | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | ✔ 13 | ||||
| allant vers B | ✔ 9 | ||||
| allant vers C | ✔ 11 | ||||
| allant vers D | |||||
| allant vers E | ✔ 30 |
| À partir de E | via A | via B | via C | via D | via E |
|---|---|---|---|---|---|
| allant vers A | ✔ 25 | ||||
| allant vers B | ✔ 21 | ||||
| allant vers C | ✔ 23 | ||||
| allant vers D | ✔ 30 | ||||
| allant vers E |
Finalement, nous arrivons à la fin de l’algorithme VD. Il n’y a plus de changement dans la topologie du réseau, ainsi les tables de routage restent les mêmes à ce stade. Nous avons coché les meilleurs chemins pour chaque ligne : il s’agit juste de choisir la route ayant la plus petite métrique.
Alors, cette exploration vous a plu ? 
Sans vouloir vous effrayer, l’algorithme de Dijkstra est encore plus intéressant. Le protocole OSPF est basé sur cet algorithme. Nous continuons avec la même optique : d’abord, on voit le protocole de routage, ensuite, l’algo.
OSPF, le mastodonte
Mastodonte, le mot n’est pas galvaudé. RIP, c’est bien pour de petits réseaux avec peu d’exigences, c’est facile à mettre en place et simple à configurer. OSPF, c’est tout l’inverse. On peut passer des heures sur le sujet tellement il est complexe. Dans ce chapitre, nous resterons en surface et nous vous orienterons vers d’autres ressources pour compléter.
Pour commencer, OSPF est un protocole de routage dynamique de type IGP. C’est à peu près le seul point commun avec RIP. Il rentre dans la catégorie des protocoles à état de liens (link state protocol) et utilise l'algorithme de Dijkstra. On garde ces notions de côté ; pour le moment, on va rester sur l’aspect purement réseau de la bête.
Comme ce protocole est conçu pour de vastes réseaux, il introduit la notion de zone, aussi parfois appelée aire (area en anglais). Chaque zone porte un numéro. L’aire principale porte toujours le numéro 0. Toutes les zones ne sont pas nécessairement reliées entre elles directement, mais une zone OSPF ne peut pas être isolée par des routeurs non OSPF, sinon, elle n’est pas visible du reste du réseau. Et pour cause : les informations sont transmises de proche en proche, directement d’un routeur à l’autre.
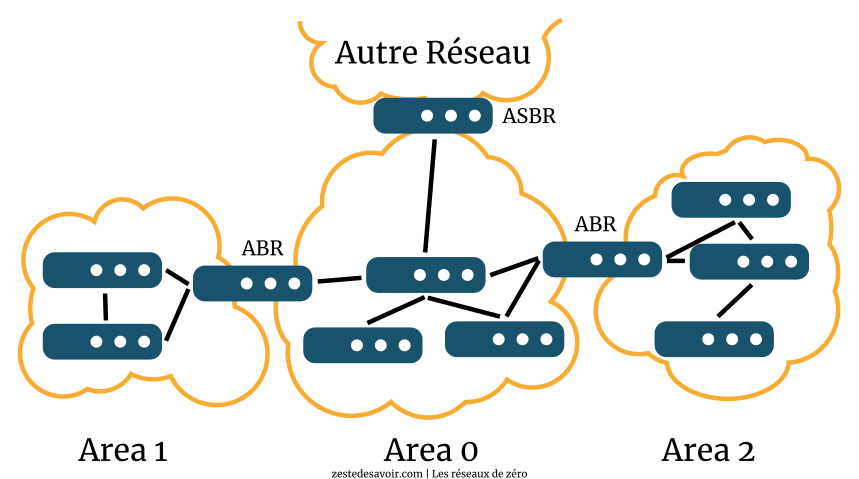
OSPF a son vocabulaire propre, et franchement, ce n’est pas très grave si vous ne le retenez pas. L’important, c’est que vous compreniez comment ça marche ! Sur l’image ci-dessus, vous pouvez voir des ABR (Area Border Router) : ce sont les routeurs qui sont à cheval sur plusieurs aires. On aperçoit également un ASBR (Autonomous System Boundary Router) : il s’agit d’un routeur qui est en limite d’un réseau OSPF et qui assure les échanges avec un réseau utilisant un autre protocole de routage, comme RIP ou BGP.
Pour découvrir son environnement, OSPF envoie des paquets Hello à ses voisins. Cela permet d’identifier sur quelles interfaces il va avoir à communiquer.
Un routeur A est un voisin ou une adjacence d’un routeur B si A et B sont directement reliés de manière logique entre eux.
Une fois les voisins découverts, OSPF émet un Link-State Advertisement (LSA) en leur direction pour les informer des informations de routage dont il dispose. Les voisins propagent l’information à leurs propres voisins avec un Link-State Update (LSU), et ainsi de suite.
Chaque changement dans un routeur génère un LSA, chaque mise à jour dans une table de routage génère un LSU. Contrairement à RIP, aucune information de routage n’est transmise par OSPF s’il n’y a pas eu de changement. Tout au plus, il envoie des paquets Hello régulièrement. Cela permet de signaler aux voisins que le routeur est toujours là, bien que discret. Quand un routeur ne donne plus de nouvelles après un certain temps (de 40 secondes à 2 minutes selon les configurations), il est considéré comme ne faisant plus partie du réseau par OSPF et ne reçoit plus les mises à jour.
Pour attribuer un coût à une liaison, nous avons vu que RIP se base sur le nombre de sauts. OSPF se base sur la bande passante : plus elle est élevée, plus le coût est faible. Une technique utilisée par Cisco consiste à diviser une bande passante de référence par la bande passante réelle. Initialement, la référence était de 100 Mb/s. Vu les débits d’aujourd’hui, cette valeur n’a plus grand intérêt. On peut la configurer pour qu’elle soit, par exemple, de 10 Gb/s, ce qui serait plus pertinent. Ainsi, un lien de 10 Mb/s aura un coût de 1.000 (10 G / 10 M = 1.000), un lien de 200 Mb/s aura un coût de 50, etc.
Il faut ensuite interpréter toutes ces valeurs reçues pour construire une table de routage. Pour cela, OSPF a recours à l’algorithme de Dijkstra, que nous allons voir dans la section suivante.
Avant cela, voici quelques liens pour approfondir votre connaissance d’OSPF. Comme évoqué, ce protocole est un mastodonte, nous n’avons fait que survoler quelques notions fondamentales. C’est Les réseaux de zéro ici, pas Les réseaux vers l’infini et au-delà !
- Introduction à OSPF, François Goffinet. Un bon article pour introduire de manière plus précise d’autres notions.
- Open Shortest Path First, Wikipédia. Moins bien structuré mais plus détaillé dans les notions évoquées.
- Introduction à OSPF, Réussir son CCNA. Plus formel et pratique, assurez-vous d’avoir bien compris le premier lien avant d’appréhender celui-ci.
Enfin, nous pouvons comparer OSPF et RIP avec le tableau suivant.
| Propriété | RIPv1 | RIPv2 | OSPF |
|---|---|---|---|
| Famille de protocole | IGP | IGP | IGP |
| Intervalle de mise à jour | 30 secondes | 30 secondes | Immédiat à chaque changement |
| Système d’adressage | Par classes | Sans classe | Sans classe, supporte le VLSM |
| Algorithme de base | Bellman-Ford | Bellman-Ford | Dijkstra |
| Adresse de mise à jour | Broadcast sur 255.255.255.255 | Multicast sur 224.0.0.9 | Multicast sur 225.0.0.5 ou 225.0.0.6 |
| Protocole et port | UDP 520 | UDP 520 | IP |
| Unité de métrique | Saut (jusqu’à 15) | Saut (jusqu’à 15) | Rapport bande passante de référence / bande passante du lien |
| Élément de mise à jour | Table entière | Table entière | Ligne de la table de routage |
Protocoles à états de lien
Notions de graphe
Avant tout, nous devons introduire une notion : celle des graphes. Ce concept mathématique a bien des applications ; aussi, nous n’introduirons que ce qui est nécessaire à une transposition au réseau. Si vous souhaitez aller plus loin, vous pouvez vous orienter vers ce tuto.
Un graphe, c’est grossièrement des points reliés par des liens. En mathématiques, on parle de sommets ou nœuds reliés par des arêtes.
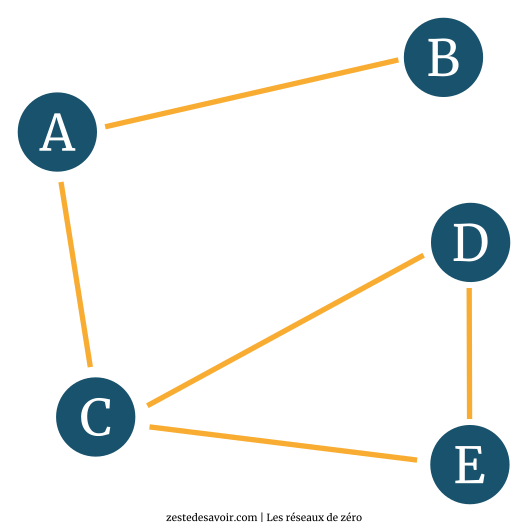
Ce qui est intéressant, c’est que ce genre de schéma peut facilement être transposé au réseau. Remplaçons les nœuds par des routeurs et les liens par des câbles.
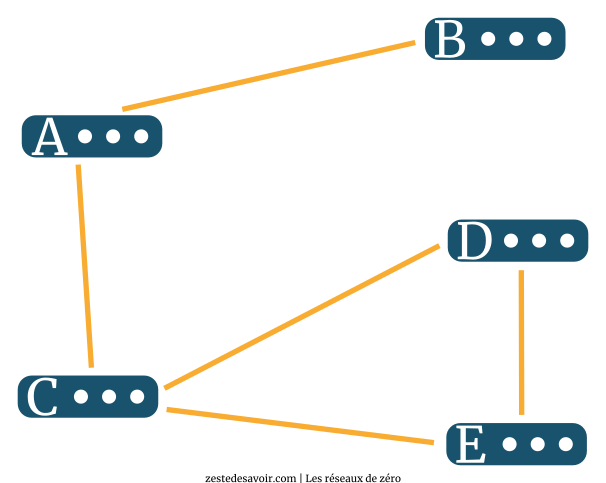
On peut aussi attribuer des valeurs à ces liens. On parle alors de poids. Pondérons le graphe précédent pour l’exemple.
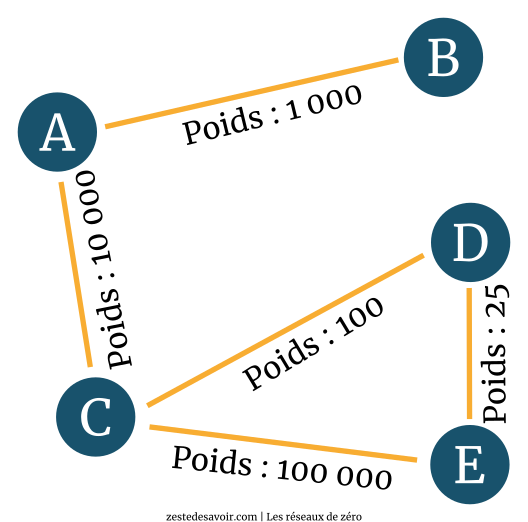
Nous pouvons faire pareil avec le schéma réseau, en y indiquant la bande passante des liens. Mieux : on peut indiquer les poids avec le rapport entre une bande passante de référence et la bande passante des liens, comme vu dans la section précédente. Prenons comme référence 100 Gb/s, soit 100.000 Mb/s.
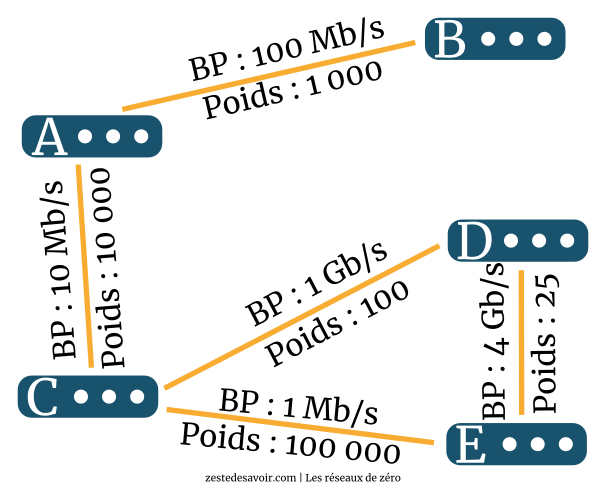
| Référence | 100.000 Mb/s | 100.000 Mb/s | 100.000 Mb/s | 100.000 Mb/s | 100.000 Mb/s |
|---|---|---|---|---|---|
| Bande passante | 1 Mb/s | 10 Mb/s | 100 Mb/s | 1 Gb/s (1.000 Mb/s) | 4 Gb/s (4.000 Mb/s) |
| Poids | 100.000 | 10.000 | 1.000 | 100 | 25 |
Comme nous transposons directement le concept mathématique à OSPF, nous utiliserons indifféremment les termes de poids et de coût. Dans ce contexte, c’est la même chose.
Ceci étant posé, il est temps de faire connaissance avec votre nouvel ami : Dijkstra.
Qui ça ?
Le plus difficile avec Dijkstra, c’est :
- réussir à l’écrire correctement ;
- réussir à le prononcer.
Pour le reste, vous avez un cours sous les yeux !
Nous allons procéder directement à l’exécution de l’algorithme avec le schéma précédent. Chaque routeur ne calcule que les distances pour lui-même. Prenons le cas du routeur A. Il sait qu’il a, directement connectés, B et C, avec des poids respectifs de 1.000 et 10.000. Sa représentation, pour le moment, se limite à ceci :
| via \ Destination | B | C | D | E |
|---|---|---|---|---|
| B | 1.000 | ∞ | ∞ | ∞ |
| C | ∞ | 10.000 | ∞ | ∞ |
Quand on ne sait pas le poids qu’aura un chemin, comme ici le chemin de A vers C en passant par B, on le note ∞ (infini). Mathématiquement, cela permet de dire qu’un tel chemin sera toujours plus lourd, et donc moins efficace que n’importe quel autre et qu’il ne faut donc pas l’emprunter.
Faisons le même exercice avec C. Pour le moment, on considère toujours que les routeurs n’ont pas encore transmis d’information par OSPF.
| via \ Destination | A | B | D | E |
|---|---|---|---|---|
| A | 10.000 | ∞ | ∞ | ∞ |
| D | ∞ | ∞ | 100 | ∞ |
| E | ∞ | ∞ | ∞ | 100.000 |
Maintenant, la machine OSPF se met en branle et C envoie sa représentation du réseau à A. Que se passe-t-il dans la tête de A ?
Voyons cela… Pour atteindre A, je m’en fous, c’est moi… Pour atteindre D, le coût depuis C est de 100. Moi, pour atteindre C, j’ai un coût de 10.000. J’additionne les deux, ça me fait un coût total de 10.100 pour atteindre D en passant par C. Mmh, je n’ai pas mieux comme possibilité, j’enregistre cela.
via \ Destination B C D E C ∞ 10.000 10.100 ∞ Il y a autre chose : C peut atteindre E avec un coût de 100.000. Si j’ajoute mon propre coût pour atteindre C, cela donne 110.000. Je n’ai pas de meilleure possibilité, j’enregistre cela.
via \ Destination B C D E C ∞ 10.000 10.100 110.000 On dirait bien que c’est tout pour le moment.
Après l’application de cet algorithme, la représentation OSPF du réseau de A est la suivante :
| via \ Destination | B | C | D | E |
|---|---|---|---|---|
| B | 1.000 | ∞ | ∞ | ∞ |
| C | ∞ | 10.000 | 10.100 | 110.000 |
Dans le même temps, D et E vont procéder aux mêmes échanges et aux mêmes calculs. Puis C va aussi envoyer ses informations à D, et ainsi de suite jusqu’à que chaque nœud ait envoyé ses informations, et traité celles qu’il a reçues. Détailler chaque étape est assez long, ce chapitre prendrait des pages et des pages. En revanche, vous, vous pouvez tout à fait faire ce travail et le partager sur le forum pour voir si vous avez tout compris. Sachez juste que, quand un routeur calcule un chemin possible qui est moins avantageux qu’un autre chemin qu’il connait déjà via le même nœud, il va l’ignorer. Par exemple, à un moment, A va recevoir de C un chemin menant à E avec un poids de 10.125. Supposons que l’autre chemin passant par C menant à E avec un poids de 110.000 n’arrive que plus tard. Il serait ignoré, car le premier chemin est plus avantageux.
Vous devriez aboutir au résultat suivant :
| via \ Destination | B | C | D | E |
|---|---|---|---|---|
| B | 1.000 | ∞ | ∞ | ∞ |
| C | ∞ | 10.000 | 10.100 | 10.125 |
La table de routage de A sera ainsi remplie avec une route pour B qui va directement sur B, ainsi que des routes vers C, D et E qui passent toutes par C. Les coûts associés sont aussi enregistrés dans la table.
| via \ Destination | A | C | D | E |
|---|---|---|---|---|
| A | 1.000 | 11.000 | 11.100 | 11.125 |
Pour B, c’est encore plus simple : la table de routage est remplie de routes vers A, C, D et E qui passent toutes par A.
| via \ Destination | A | B | D | E |
|---|---|---|---|---|
| A | 10.000 | 11.000 | ∞ | ∞ |
| D | ∞ | ∞ | 100 | 125 |
| E | ∞ | ∞ | 100.025 | 100.000 |
Là, c’est un peu plus complexe. Pour atteindre A et B, C n’a d’autre choix que de passer par A, ces routes sont enregistrées dans la table de routage. Par contre, pour aller vers D et E, il y a deux possibilités : passer par D ou par E. Passer par D est moins coûteux pour les deux destinations, on enregistre alors une route vers elles-deux via D. On ne conserve pas les chemins qui passent par E.
| via \ Destination | A | B | C | E |
|---|---|---|---|---|
| C | 10.100 | 11.100 | 100 | 100.100 |
| E | 110.025 | 111.025 | 100.025 | 25 |
Pour D, les routes vers A, B et C passeront par C. Pour atteindre E, il utilisera son lien direct.
| via \ Destination | A | B | C | D |
|---|---|---|---|---|
| C | 110.000 | 111.000 | 100.000 | 100.100 |
| D | 10.125 | 11.125 | 125 | 25 |
Pour E, les paquets à destination de A, B, C et D partiront par D. Le poids très important du lien entre C et E le rend complètement inintéressant.
Voilà pour Dijkstra ! N’oubliez pas que les routes enregistrées dans les tables par OSPF peuvent cohabiter avec d’autres routes et ne seront pas forcément empruntées. En cas de routes différentes pour une même destination, les protocoles de routage ont un ordre de priorité. Une route OSPF aura l’avantage sur une route RIP, mais elle s’inclinera face à une route statique, c’est-à-dire renseignée manuellement.
BGP : les entrailles d'Internet
Nous abordons maintenant un protocole particulier. BGP est très différent de ce que nous avons vu jusqu’à présent. Voyons ses caractéristiques dans les grandes lignes.
D’abord, c’est un fondement d’Internet. Son utilité principale est d’assurer l’échange de routes entre fournisseurs d’accès à Internet et autres opérateurs de télécommunications. Ensuite, il fonctionne sur un mode pair-à-pair, en établissant une connexion TCP sur le port 179. Contrairement à RIP ou OSPF qui émettent des messages et découvrent le réseau qui les entoure, BGP doit être spécifiquement configuré sur un routeur pour travailler avec un seul autre routeur voisin. On peut avoir plusieurs liaisons BGP (on parle de session) sur un même routeur, mais elles sont indépendantes et doivent être configurées manuellement.
Un routeur qui exécute BGP fait le lien entre un réseau dit interne (les clients d’un FAI par exemple) et le réseau d’interconnexion dit externe (Internet). C’est de là que vient le B pour Border : ce protocole intervient à la frontière entre ces réseaux. La partie interne est considérée comme un système autonome, en anglais autonomous system et souvent abrégé AS. Chaque AS dispose d’un numéro qui lui est attribué par une autorité pour éviter les conflits.
BGP est donc un protocole de type EGP. Il peut aussi être utilisé en interne, au sein d’un AS, par exemple pour des besoins de redondance. Dans ce cas, on parle d'IBGP. Dans cette section, nous nous limiterons à l’utilisation externe, dite EBGP.
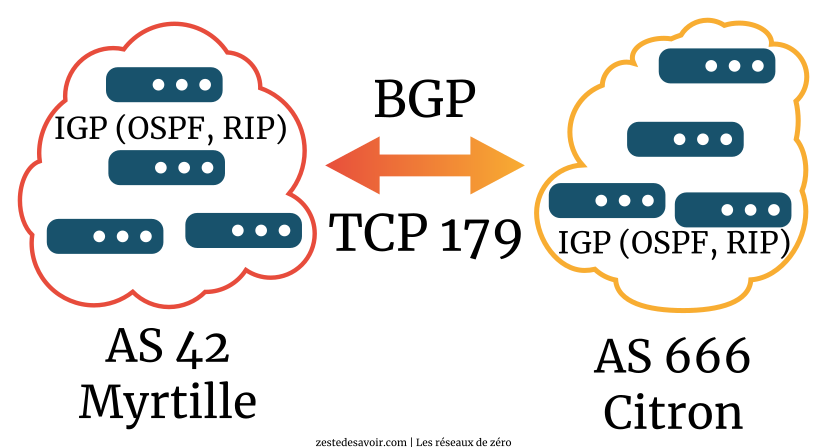
Comme on peut s’en douter, sur Internet, le nombre de routes est conséquent. BGP a recours à l’agrégation de routes, que nous avons étudiée précédemment. Cela permet d’alléger un peu les transmissions. Selon le constructeur Cisco, en 2015, une table BGP complète sur Internet compte plus de 570.000 entrées !
Vu le volume, il ne vaut mieux pas balancer toute sa table de routage à son voisin. Pour éviter la saturation, BGP doit être relativement lent. Chaque routeur BGP envoie à ses voisins les modifications de sa table avec un intervalle minimum de 30 secondes par voisin et par préfixe, c’est-à-dire par route agrégée. Cette valeur est une recommandation, ce paramètre peut être modifié. Si une route devient inaccessible, l’annonce est immédiate. Toute route reçue par BGP n’est pas forcément intégrée à la table de routage : des comparaisons sont effectuées avec les entrées existantes pour déterminer si une modification est pertinente.
Comme OSPF, s’il n’a rien à dire, BGP envoie des messages régulièrement à ses voisins pour dire qu’il est en vie. Si un pair n’émet rien durant 90 secondes (valeur par défaut), la session est considérée close par son voisin. 90 secondes, c’est long, mais une fréquence plus élevée implique mécaniquement une augmentation du trafic et donc augmente le risque de congestion. En revanche, en cas de coupure brute, comme une clôture de session niveau TCP ou un câble débranché, la session BGP prend fin immédiatement.
Récapitulons ce que nous avons vu jusqu’à présent avec un tableau.
| Propriété | RIPv1 | RIPv2 | OSPF | BGP |
|---|---|---|---|---|
| Famille de protocole | IGP | IGP | IGP | EGP |
| Intervalle de mise à jour | 30 secondes | 30 secondes | Immédiat à chaque changement | Immédiat / 30 secondes pour un même voisin et un même préfixe |
| Système d’adressage | Par classes | Sans classe | Sans classe, supporte le VLSM | Agrégation de routes |
| Algorithme de base | Bellman-Ford | Bellman-Ford | Dijkstra | aucun |
| Adresse de mise à jour | Broadcast sur 255.255.255.255 | Multicast sur 224.0.0.9 | Multicast sur 225.0.0.5 ou 225.0.0.6 | Unicast vers le voisin |
| Protocole et port | UDP 520 | UDP 520 | IP | TCP 179 |
| Unité de métrique | Saut (jusqu’à 15) | Saut (jusqu’à 15) | Rapport bande passante de référence / bande passante du lien | selon les IGP |
| Élément de mise à jour | Table entière | Table entière | Ligne de la table de routage | Préfixe |
Nous avons terminé notre petite étude de quelques protocoles de routage parmi les plus populaires. Il en existe d’autres, comme IS-IS, similaire à OSPF, ou encore EIGRP. Avant de changer de niveau, il nous reste à disséquer le protocole central de la couche réseau !