Depuis le début de ce cours, vous avez appréhendé beaucoup de notions. À partir d’une seule trame, nous allons remonter les couches du modèle OSI et résumer leur rôle. Pour cela, nous utiliserons un analyseur de trame, qui nous permettra de visualiser bit par bit ce qui passe par le support physique.
Contexte
L’expérience réalisée pour ce chapitre est simple. Depuis un PC, on a ouvert un navigateur et on est allé sur zestedesavoir.com. Ce PC est relié à un routeur, lui-même connecté à Internet. En même temps, on a lancé une capture de trame avec le logiciel Wireshark. Ce programme permet de visualiser finement ce qui se passe au niveau des interfaces réseaux, à partir du niveau 2. Vous pouvez apprendre à l’utiliser grâce à cette annexe.
La capture réalisée permet de visualiser dans le détail chaque valeur de chaque champ de chaque protocole. Nous allons partir de la couche liaison de données et remonter jusqu’à la couche application. D’abord, nous prendrons le point de vue de la carte réseau pour les niveaux 2 et 3, puis celui du processus pour les niveaux 4 et 5, et enfin celui de l'application pour les niveaux 6 et 7.

Les adresses MAC ont été partiellement masquées pour des raisons de confidentialité.
Voici comment se représente la trame que nous allons décortiquer. Si vous avez l’œil, vous aurez peut-être déjà repéré qu’il s’agit d’une réponse du serveur interrogé qui nous parvient. 
Au niveau de la carte réseau
Rentrons dans le détail de la couche 2.

Il s’agit du protocole Ethernet. On y retrouve les adresses MAC et l’EtherType, noté simplement "Type". Les adresses MAC représentent des identifiants physiques et uniques des hôtes, ou plus exactement, de leur carte réseau. La destination est déterminée par la source en fonction des besoins du protocole de niveau supérieur. L’EtherType nous indique qu’il s’agit d’IPv6. L’adresse MAC de destination doit donc correspondre à celle de l’hôte de destination niveau IP, ou, s’il n’est pas dans le réseau local, à celle d’une passerelle adéquate.
Avouez qu’Ethernet, c’est plutôt simple ! On n’a pas de VLAN dans notre cas, ce qui facilite encore plus les choses. On n’a pas non plus de liaison point-à-point à transporter. Si vous éprouvez le besoin de réviser aussi ces sujets, n’hésitez pas à relire les chapitres correspondants. 
Passons maintenant à la couche réseau et son paquet IPv6.
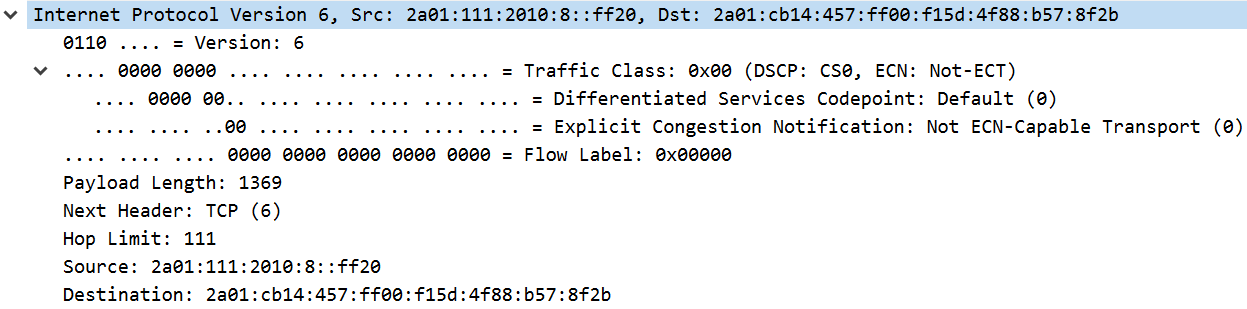
IP permet la transmission de paquets sur le réseau d’un bout à l’autre. Pour cela, il embarque un certain nombre de fonctionnalités qui se déclenchent selon divers paramètres. Le premier champ précise qu’il s’agit de la version 6. C’est important à savoir pour les routeurs : sans ça, ils ne sauraient pas forcément détacher et interpréter correctement les valeurs qui suivent !
On retrouve ensuite le DSCP. Il permet de donner une information sur le traitement à apporter au paquet, dans le cadre de la qualité de service. Ce système ne peut être utilisé que sur un réseau DiffServ, qui gère la priorité des paquets en fonction de divers paramètres comme le contenu transmis. Comme on n’est pas dans ce cas ici, ce champ vaut zéro.
L’ECN est un drapeau double permettant d’avertir les hôtes d’une congestion sur le réseau. Dans notre exemple, il n’est pas supporté. Le flow label, qui permet d’étiqueter des paquets appartenant à un même flux, n’est pas utilisé non plus. De manière générale, ces trois éléments ne sont pas utilisés sur Internet. Ils sont réservés aux réseaux d’entreprise.
La payload length, taille des données utiles, nous indique que 1369 octets sont encapsulés dans ce paquet. Le next header nous informe qu’ils correspondent à un segment TCP. IPv6 supporte un système d’extensions qui peuvent se superposer. Ainsi, un next header peut aussi indiquer qu’il faut s’attendre ensuite à un complément d’en-tête, par exemple une information de fragmentation. Un système similaire d’options existe avec IPv4 mais n’est presque pas utilisé.
Le hop limit qui suit, qu’on peut aussi appeler Time To Live, indique le nombre de sauts que le paquet pouvait encore effectuer sur le réseau. Un saut correspond à la traversée d’un routeur. Pour éviter qu’un paquet ne se retrouve coincé dans une boucle à cause d’une erreur, le nombre maximum de traversées est limité. Avec 111 sauts restants, il y avait de la marge. 
Pour finir, on retrouve les adresses source et destination. Avec IPv6, elles sont codées sur 128 bits, soit 16 octets. Pour faciliter la lecture, on les écrit en hexadécimal par blocs de 4 chiffres, en retirant les zéros inutiles. S’il y a beaucoup de zéros consécutifs, on peut les compresser en écrivant juste « :: ».
On a dit au départ qu’on a juste tapé zestedesavoir.com dans un navigateur, alors comment on se retrouve avec ces adresses précises dans le paquet ? 
Ça, c’est au programme de la prochaine partie du cours. Patience ! 
Au niveau du processus
Maintenant, prenons le point de vue processus. Pour les besoins de ce chapitre, on sépare processus et application, même si les deux correspondent au même logiciel. On considère que le processus, c’est la partie du navigateur qui gère les connexions et le transport (niveaux 4 et 5), tandis que l’application, c’est ce qui gère le niveau applicatif et permet l’affichage de pages web (niveaux 6 et 7). La partie processus pourrait être la même dans plein de programmes différents, tandis que l’application est spécifique au programme.
On en arrive à la couche transport. Si vous avez décroché lors des chapitres correspondants, c’est l’occasion de vous rattraper !
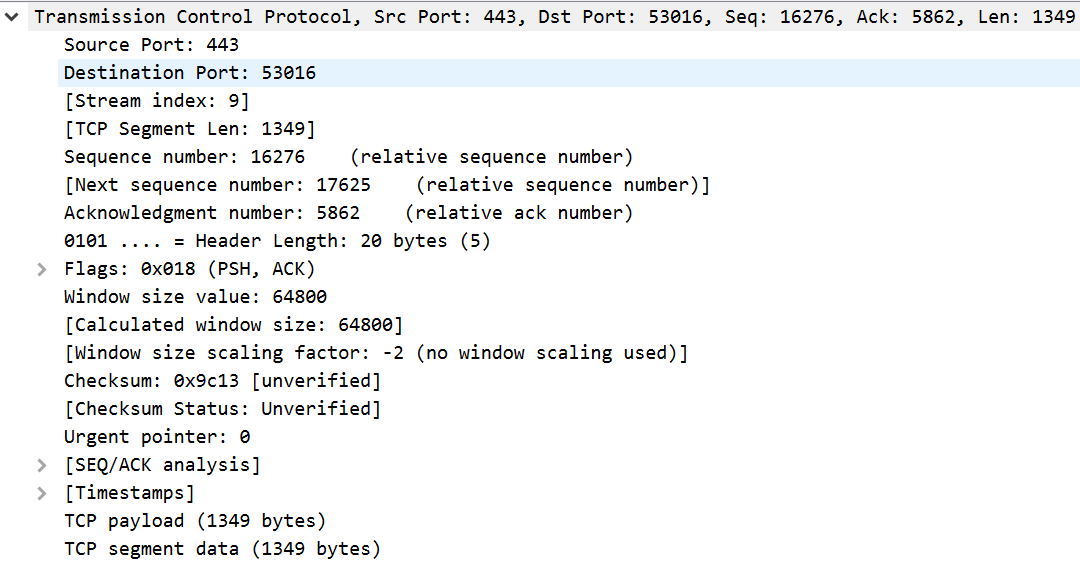
La couche transport permet d’établir une communication de bout en bout au niveau des processus. Pour identifier ces derniers sur un même système, on a recours à des ports, qui sont en quelque sorte des portes d’entrée. Ils sont numérotés de 0 à 65.535. Ceux entre 0 et 1023 sont dits "connus" et ont une application bien définie. Entre 1024 et 49.151, les ports sont dits "enregistrés". Certaines applications les utilisent de façon récurrente, mais leur utilisation est assez peu encadrée. Enfin, après 49.152, c’est libre. Cette plage est souvent utilisée par les clients pour des ouvertures de connexion qui n’ont pas besoin d’un numéro fixe et défini.
Dans notre exemple, on voit que le port source est 443, et le port destination, 53.016. 443 est un port connu qui correspond à un serveur web, et plus précisément au protocole HTTPS. La destination est un port libre. On constate donc que cette transmission est en provenance d’un serveur web et à destination d’un client. C’est donc une réponse à une requête précédemment envoyée.
TCP est orienté connexion. Il utilise un système de numéros de séquence, qui lui permet de savoir où on en est dans le transport des données. Pour peu que la quantité de données à transporter soit importante, elles seront découpées en plusieurs segments et TCP permet de s’assurer qu’ils arrivent tous bien à destination. Ici, le numéro de séquence relatif est 16.276, ce qui signifie que ce qui vient fait suite au 16.276ème octet du flux. En même temps, on indique un numéro d’acquittement de 5.862. Cela précise que, dans l’autre sens, on attend de notre interlocuteur un 5.862ème octet pour sa prochaine transmission. Si l’autre hôte avait déjà transmis 6.000 octets, cela lui permettra de se rendre compte qu’un segment n’a pas été reçu et ainsi de le renvoyer.
Les valeurs exprimées ici sont relatives, pour que ce soit plus lisible. Une séquence peut être initialisée avec une valeur arbitraire pour des raisons de confidentialité. Dans notre exemple, le numéro de séquence réel est 479.815.025. C’est tout de suite moins parlant !
Un mot sur la longueur de l’en-tête : 5 blocs de 4 octets, ça fait 20 octets. Les données de niveau supérieur se trouveront donc après ces 20 octets d’en-tête. Ce champ peut servir si le segment présente des options, ce qui n’est pas le cas ici.
Les drapeaux sont plus intéressants. On a ici les flags PSH et ACK levés. PSH indique au système que la transmission doit partir tout de suite, sans attendre de remplir davantage une mémoire tampon. ACK précise à l’interlocuteur qu’il doit faire attention au numéro d’acquittement juste avant, car l’émetteur souhaite accuser réception de données.
Le champ qui suit est la fenêtre. L’émetteur indique qu’il peut recevoir jusqu’à 64.800 octets sans acquittement. L’hôte de destination est invité à patienter avant son prochain envoi s’il n’a pas reçu d’accusé de réception après 64.800 octets envoyés. Cela permet de réguler la vitesse du flux, d’avoir des envois plus réguliers et d’éviter d’être surchargé.
La somme de contrôle vérifie l’intégrité des données transmises. Le destinataire va la recalculer selon le même mode opératoire que l’émetteur. S’il ne tombe pas sur la même valeur, il considérera qu’il y a un problème et n’acquittera pas le segment.
Le dernier champ n’est presque jamais utilisé. Il sert à préciser quelle partie du segment doit être traitée urgemment. Il n’est lu que si le drapeau "URG" est levé. Son utilisation est anecdotique.
Au début du chapitre, une ligne a peut-être attiré votre attention dans la capture.
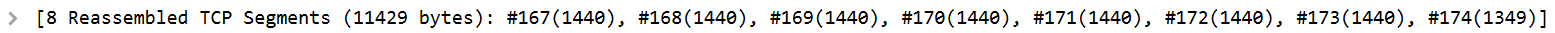
8 segments ont été réassemblés pour pouvoir lire le protocole de niveau supérieur. Il n’était pas possible de transmettre les 11.429 octets d’un coup, alors ils ont été segmentés pour être transportés. Le processus les a ensuite réunis pour pouvoir reconstruire les données d’origine.
En quoi consistent-elles, justement ? Eh bien, il s’agit de TLS, un protocole de chiffrement. Vous vous souvenez qu’à l’origine, on étudie la transmission d’une page web de Zeste de Savoir ? Pour cela, on utilise HTTPS, qui est la combinaison de HTTP, le protocole du web, encapsulé dans TLS, qui est en charge du chiffrement.
Comme nous sommes dans un chapitre de révision, on vous épargne le fonctionnement de TLS. Au moment de la capture de la trame, les échanges pour définir les conditions du chiffrement ont déjà eu lieu. Tout ce qu’on voit, c’est ceci, et ça se passe d’explications.

Le fait d’avoir écrit "niveau 5" va nous attirer des foudres. Personne n’est d’accord pour associer TLS à une couche en particulier. Certains considèrent que cela relève du transport, d’autres, de la présentation ou encore de la session. Vous le verrez parfois classé dans les niveaux 4, 5 ou 6, voire à cheval sur plusieurs niveaux, ou pire : entre deux niveaux.
En revanche, on ne risque pas d’être remis en cause pour le niveau applicatif.
Au niveau de l'application
On va avoir un souci avec notre analyseur de trame : à partir de maintenant, tout est chiffré ! Pour pouvoir visualiser ce qui est transmis au dessus de TLS, on a eu recours à un proxy. Ce service, qui sert de relai, sera étudié dans la partie suivante.
Voici ce qui est vu par notre application.
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 20 Mar 2019 22:45:08 GMT
Content-Type: text/html; charset=utf-8
Connection: close
Vary: Accept-Encoding
Vary: Cookie
Strict-Transport-Security: max-age=63072000; includeSubDomains; preload
X-Xss-Protection: 1
X-Content-Type-Options: nosniff
X-Frame-Options: SAMEORIGIN
P3P: CP="ALL DSP COR PSAa PSDa OUR NOR ONL UNI COM NAV"
Strict-Transport-Security: max-age=15768000
X-Clacks-Overhead: GNU Terry Pratchett
Content-Length: 87430
<!DOCTYPE html>
Ce serait beaucoup trop long de retranscrire l’intégralité de la réponse HTTP. Nous nous arrêtons à la première ligne après en-tête, c’est suffisant.
La couche 6 correspond à la présentation. Elle n’englobe pas de protocoles comme pour les autres niveaux. Elle désigne la façon dont l’information est représentée. Dans le cas de HTTP, l’en-tête, qui correspond au bloc ci-dessus à l’exception de la dernière ligne, est toujours codé en ASCII, un encodage simple faisant correspondre une valeur numérique sur un octet à un caractère. Ensuite, dans l’en-tête, on peut définir qu’on va faire autrement pour le contenu. Regardez cette ligne :
Content-Type: text/html; charset=utf-8
La fin indique que la page web qui suit sera encodée en UTF-8, un autre système de représentation de caractères. On aurait aussi pu avoir un en-tête indiquant que le contenu était compressé, ce qui n’est pas le cas ici. Cela relève aussi de la couche 6.
Finalement, on remonte à la surface avec le protocole de niveau 7, HTTP. Le contenu que nous avons là est une réponse d’un serveur web. Elle se lit facilement puisqu’elle est déjà bien présentée grâce à la couche 6. On peut distinguer l’en-tête, que nous avons représenté en intégralité, et le contenu, dont nous n’avons représenté que la première ligne. Si vous voulez le reste, c’est simple : allez sur la page d’accueil de Zeste de Savoir et affichez le code source. 
Et maintenant ? Nous n’allons pas nous quitter comme ça. Des questions ont été soulevées dans ce chapitre. L’objet de la partie suivante sera de revenir dessus en détail.